Benchmarking Language Model Creativity: A Case Study on Code Generation

0
Sign in to get full access
Overview
- This paper explores the creativity of language models, specifically in the context of code generation.
- The researchers developed a benchmark to assess the creativity of language models in producing novel and useful code snippets.
- The paper compares the performance of various large language models on this benchmark and provides insights into their creative capabilities.
Plain English Explanation
The researchers in this study wanted to understand how creative language models like GPT-3 and Codex are when it comes to generating code. They created a special test, or "benchmark," to measure the creativity of these models.
The key idea behind this benchmark is to see how well the language models can come up with new and useful code snippets, rather than just repeating what they've seen before. The researchers had the models try to solve a variety of coding challenges and then evaluated the creativity and usefulness of the solutions.
By comparing the performance of different language models on this benchmark, the researchers were able to gain insights into the creative capabilities of these systems. The results provide useful information for developers and researchers who are interested in using language models for tasks like code generation.
Technical Explanation
The paper introduces a new benchmark called "CreativeVal" to evaluate the creativity of language models in the context of code generation. The benchmark consists of a diverse set of coding challenges that require the models to come up with novel and useful code snippets.
The researchers tested several large language models, including GPT-3 and Codex, on the CreativeVal benchmark. The models were asked to generate code to solve the challenges, and their outputs were then evaluated by human judges on criteria such as creativity, functionality, and novelty.
The results showed that the language models exhibited varying levels of creativity, with some models performing better than others on certain types of challenges. The paper provides a detailed analysis of the models' performance and discusses the implications for the development of more creative and capable language models for tasks like code generation.
Critical Analysis
The paper provides a valuable contribution to the field of language model evaluation, as it introduces a new benchmark specifically designed to assess the creativity of these models. The CreativeVal benchmark appears to be a well-designed and comprehensive test that could be useful for researchers and developers working on language models.
However, the paper does acknowledge some limitations of the study, such as the potential for bias in the human evaluation of the code snippets. Additionally, the paper does not explore the underlying mechanisms that enable the language models to exhibit creative behavior, which could be an area for further research.
Another potential limitation is the relatively small scale of the study, with only a few language models tested. It would be interesting to see the benchmark applied to a wider range of models, including more recent and specialized language models for code generation.
Conclusion
This paper presents a novel approach to evaluating the creativity of language models, with a specific focus on their ability to generate novel and useful code snippets. The CreativeVal benchmark and the insights gained from testing various language models on this benchmark could have important implications for the development of more creative and capable language models for a wide range of applications, including code generation, software engineering, and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking Language Model Creativity: A Case Study on Code Generation
Yining Lu, Dixuan Wang, Tianjian Li, Dongwei Jiang, Daniel Khashabi
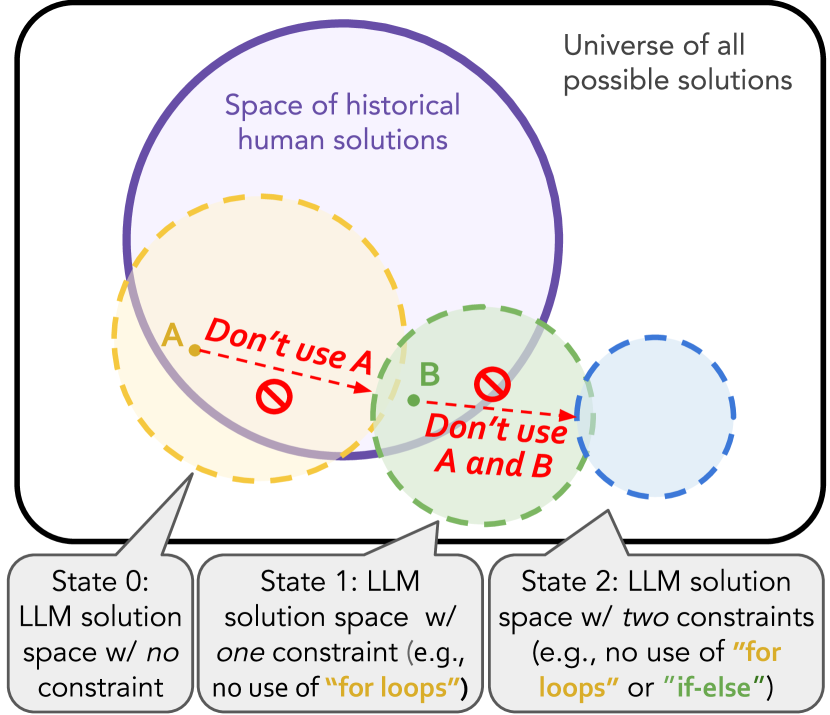
As LLMs become increasingly prevalent, it is interesting to consider how ``creative'' these models can be. From cognitive science, creativity consists of at least two key characteristics: emph{convergent} thinking (purposefulness to achieve a given goal) and emph{divergent} thinking (adaptability to new environments or constraints) citep{runco2003critical}. In this work, we introduce a framework for quantifying LLM creativity that incorporates the two characteristics. This is achieved by (1) Denial Prompting pushes LLMs to come up with more creative solutions to a given problem by incrementally imposing new constraints on the previous solution, compelling LLMs to adopt new strategies, and (2) defining and computing the NeoGauge metric which examines both convergent and divergent thinking in the generated creative responses by LLMs. We apply the proposed framework on Codeforces problems, a natural data source for collecting human coding solutions. We quantify NeoGauge for various proprietary and open-source models and find that even the most creative model, GPT-4, still falls short of demonstrating human-like creativity. We also experiment with advanced reasoning strategies (MCTS, self-correction, etc.) and observe no significant improvement in creativity. As a by-product of our analysis, we release NeoCoder dataset for reproducing our results on future models.
Read more7/15/2024
🛸
0
CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation
Matthew DeLorenzo, Vasudev Gohil, Jeyavijayan Rajendran
Large Language Models (LLMs) have proved effective and efficient in generating code, leading to their utilization within the hardware design process. Prior works evaluating LLMs' abilities for register transfer level code generation solely focus on functional correctness. However, the creativity associated with these LLMs, or the ability to generate novel and unique solutions, is a metric not as well understood, in part due to the challenge of quantifying this quality. To address this research gap, we present CreativeEval, a framework for evaluating the creativity of LLMs within the context of generating hardware designs. We quantify four creative sub-components, fluency, flexibility, originality, and elaboration, through various prompting and post-processing techniques. We then evaluate multiple popular LLMs (including GPT models, CodeLlama, and VeriGen) upon this creativity metric, with results indicating GPT-3.5 as the most creative model in generating hardware designs.
Read more4/16/2024
💬
0
Divergent Creativity in Humans and Large Language Models
Antoine Bellemare-Pepin (CoCo Lab, Psychology department, Universit'e de Montr'eal, Montreal, QC, Canada, Music department, Concordia University, Montreal, QC, Canada), Franc{c}ois Lespinasse (Sociology and Anthropology department, Concordia University, Montreal, QC, Canada), Philipp Tholke (CoCo Lab, Psychology department, Universit'e de Montr'eal, Montreal, QC, Canada), Yann Harel (CoCo Lab, Psychology department, Universit'e de Montr'eal, Montreal, QC, Canada), Kory Mathewson (Mila), Jay A. Olson (Department of Psychology, University of Toronto Mississauga, Mississauga, ON, Canada), Yoshua Bengio (Mila, Department of Computer Science and Operations Research, Universit'e de Montr'eal, Montreal, QC, Canada), Karim Jerbi (CoCo Lab, Psychology department, Universit'e de Montr'eal, Montreal, QC, Canada, UNIQUE Center)
The recent surge in the capabilities of Large Language Models (LLMs) has led to claims that they are approaching a level of creativity akin to human capabilities. This idea has sparked a blend of excitement and apprehension. However, a critical piece that has been missing in this discourse is a systematic evaluation of LLM creativity, particularly in comparison to human divergent thinking. To bridge this gap, we leverage recent advances in creativity science to build a framework for in-depth analysis of divergent creativity in both state-of-the-art LLMs and a substantial dataset of 100,000 humans. We found evidence suggesting that LLMs can indeed surpass human capabilities in specific creative tasks such as divergent association and creative writing. Our quantitative benchmarking framework opens up new paths for the development of more creative LLMs, but it also encourages more granular inquiries into the distinctive elements that constitute human inventive thought processes, compared to those that can be artificially generated.
Read more5/24/2024
💬
0
Characterising the Creative Process in Humans and Large Language Models
Surabhi S. Nath, Peter Dayan, Claire Stevenson
Large language models appear quite creative, often performing on par with the average human on creative tasks. However, research on LLM creativity has focused solely on textit{products}, with little attention on the creative textit{process}. Process analyses of human creativity often require hand-coded categories or exploit response times, which do not apply to LLMs. We provide an automated method to characterise how humans and LLMs explore semantic spaces on the Alternate Uses Task, and contrast with behaviour in a Verbal Fluency Task. We use sentence embeddings to identify response categories and compute semantic similarities, which we use to generate jump profiles. Our results corroborate earlier work in humans reporting both persistent (deep search in few semantic spaces) and flexible (broad search across multiple semantic spaces) pathways to creativity, where both pathways lead to similar creativity scores. LLMs were found to be biased towards either persistent or flexible paths, that varied across tasks. Though LLMs as a population match human profiles, their relationship with creativity is different, where the more flexible models score higher on creativity. Our dataset and scripts are available on href{https://github.com/surabhisnath/Creative_Process}{GitHub}.
Read more6/7/2024