CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation

0
🛸
Sign in to get full access
Overview
- This paper explores the use of Large Language Models (LLMs) in generating hardware designs, specifically at the register transfer level (RTL).
- Prior research has focused on the functional correctness of LLM-generated code, but the creativity or uniqueness of the solutions generated is less understood.
- The authors present a new framework called CreativeEval to quantify the creativity of LLMs in hardware design generation.
- They evaluate several popular LLMs, including GPT models, CodeLlama, and VeriGen, using this creativity metric.
- The results suggest that GPT-3.5 is the most creative model in generating hardware designs.
Plain English Explanation
The paper is about using powerful language models, called Large Language Models (LLMs), to help design computer hardware. LLMs are AI systems that can generate human-like text, and they've proven to be great at writing code.
In the past, researchers have looked at how well LLMs can write code that works correctly. But the researchers in this paper wanted to understand something else - how creative or unique the code generated by LLMs can be. Coming up with new and novel hardware designs requires creativity, and the paper's authors wanted to find a way to measure that.
To do this, they created a new framework called CreativeEval. This framework looks at four different aspects of creativity - how fluent the code is, how flexible the solutions are, how original the designs are, and how much detail or elaboration is included. The researchers then used this framework to evaluate several popular LLMs, including GPT models, CodeLlama, and VeriGen.
The key finding is that the GPT-3.5 model seems to be the most creative at generating hardware designs, outperforming the other LLMs tested. This suggests that these powerful language models could be a useful tool for hardware designers looking to come up with new and innovative ideas.
Technical Explanation
The paper presents a framework called CreativeEval for evaluating the creativity of Large Language Models (LLMs) in the context of generating hardware designs at the register transfer level (RTL).
The framework quantifies four sub-components of creativity:
- Fluency: How fluent and natural the generated code is.
- Flexibility: The diversity and adaptability of the solutions generated.
- Originality: The uniqueness and novelty of the designs.
- Elaboration: The level of detail and complexity in the generated designs.
The researchers then use this framework to evaluate the creativity of several popular LLMs, including GPT models, CodeLlama, and VeriGen. The results indicate that GPT-3.5 is the most creative model in generating hardware designs, outperforming the other LLMs tested.
The paper's key contribution is the development of the CreativeEval framework, which provides a structured way to assess the creativity of LLMs in the context of hardware design. This is an important step forward, as prior works have focused primarily on functional correctness, rather than the creativity or uniqueness of the generated solutions.
Critical Analysis
The paper provides a solid framework for evaluating the creativity of LLMs in hardware design generation, addressing an important research gap. However, there are a few potential limitations and areas for further research:
-
The CreativeEval framework relies on subjective human assessments for some of the creativity sub-components, which could introduce bias. Developing more objective metrics may further strengthen the evaluation.
-
The paper focuses on RTL-level hardware designs, but creativity may manifest differently in other design abstraction levels, such as the system or architectural levels. Extending the framework to these domains could provide a more comprehensive understanding of LLM creativity in hardware design.
-
The evaluation is limited to a few popular LLMs, and it would be valuable to expand the analysis to a broader range of models, including specialized hardware design models like RealHumanEval or multi-expert architectures.
-
The paper does not explore the potential biases or limitations of the LLMs in terms of the diversity and inclusivity of the hardware designs generated. Further research in this area could provide important insights.
Overall, this paper offers a promising framework for evaluating the creativity of LLMs in hardware design, with the potential to inform the development of more innovative and unique hardware solutions.
Conclusion
This paper presents a novel framework called CreativeEval for assessing the creativity of Large Language Models (LLMs) in the context of hardware design generation. The framework quantifies four key aspects of creativity: fluency, flexibility, originality, and elaboration.
Using this framework, the researchers evaluated several popular LLMs, including GPT models, CodeLlama, and VeriGen. The results indicate that GPT-3.5 is the most creative model in generating hardware designs, outperforming the other LLMs tested.
This research represents an important step forward in understanding the creative capabilities of LLMs in the hardware design process. By quantifying creativity, the CreativeEval framework could help hardware designers leverage these powerful language models to generate more innovative and unique solutions, ultimately driving progress in the field of computer hardware design.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
0
CreativEval: Evaluating Creativity of LLM-Based Hardware Code Generation
Matthew DeLorenzo, Vasudev Gohil, Jeyavijayan Rajendran
Large Language Models (LLMs) have proved effective and efficient in generating code, leading to their utilization within the hardware design process. Prior works evaluating LLMs' abilities for register transfer level code generation solely focus on functional correctness. However, the creativity associated with these LLMs, or the ability to generate novel and unique solutions, is a metric not as well understood, in part due to the challenge of quantifying this quality. To address this research gap, we present CreativeEval, a framework for evaluating the creativity of LLMs within the context of generating hardware designs. We quantify four creative sub-components, fluency, flexibility, originality, and elaboration, through various prompting and post-processing techniques. We then evaluate multiple popular LLMs (including GPT models, CodeLlama, and VeriGen) upon this creativity metric, with results indicating GPT-3.5 as the most creative model in generating hardware designs.
Read more4/16/2024
0
Benchmarking Language Model Creativity: A Case Study on Code Generation
Yining Lu, Dixuan Wang, Tianjian Li, Dongwei Jiang, Daniel Khashabi
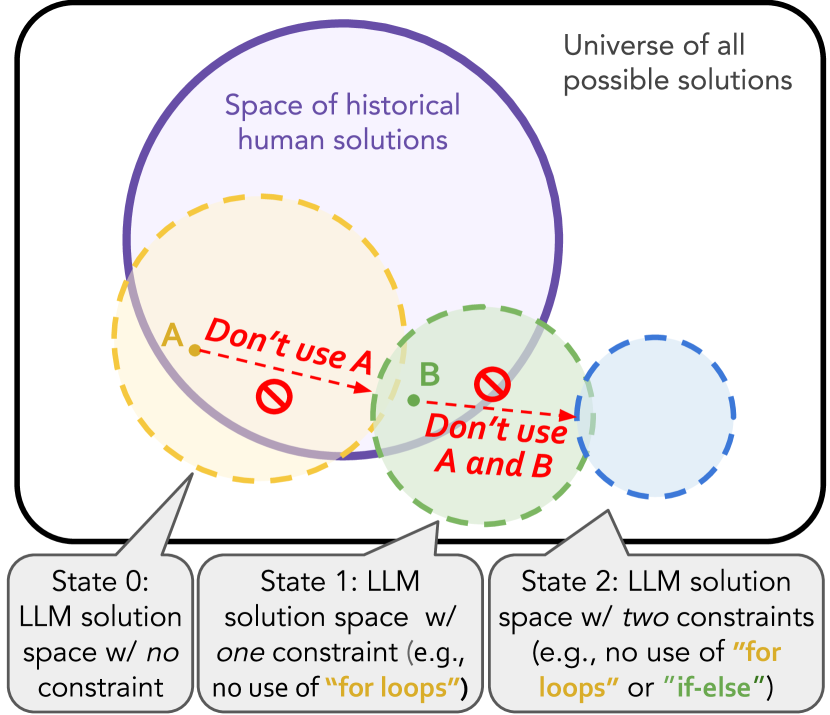
As LLMs become increasingly prevalent, it is interesting to consider how ``creative'' these models can be. From cognitive science, creativity consists of at least two key characteristics: emph{convergent} thinking (purposefulness to achieve a given goal) and emph{divergent} thinking (adaptability to new environments or constraints) citep{runco2003critical}. In this work, we introduce a framework for quantifying LLM creativity that incorporates the two characteristics. This is achieved by (1) Denial Prompting pushes LLMs to come up with more creative solutions to a given problem by incrementally imposing new constraints on the previous solution, compelling LLMs to adopt new strategies, and (2) defining and computing the NeoGauge metric which examines both convergent and divergent thinking in the generated creative responses by LLMs. We apply the proposed framework on Codeforces problems, a natural data source for collecting human coding solutions. We quantify NeoGauge for various proprietary and open-source models and find that even the most creative model, GPT-4, still falls short of demonstrating human-like creativity. We also experiment with advanced reasoning strategies (MCTS, self-correction, etc.) and observe no significant improvement in creativity. As a by-product of our analysis, we release NeoCoder dataset for reproducing our results on future models.
Read more7/15/2024

0
VHDL-Eval: A Framework for Evaluating Large Language Models in VHDL Code Generation
Prashanth Vijayaraghavan, Luyao Shi, Stefano Ambrogio, Charles Mackin, Apoorva Nitsure, David Beymer, Ehsan Degan
With the unprecedented advancements in Large Language Models (LLMs), their application domains have expanded to include code generation tasks across various programming languages. While significant progress has been made in enhancing LLMs for popular programming languages, there exists a notable gap in comprehensive evaluation frameworks tailored for Hardware Description Languages (HDLs), particularly VHDL. This paper addresses this gap by introducing a comprehensive evaluation framework designed specifically for assessing LLM performance in VHDL code generation task. We construct a dataset for evaluating LLMs on VHDL code generation task. This dataset is constructed by translating a collection of Verilog evaluation problems to VHDL and aggregating publicly available VHDL problems, resulting in a total of 202 problems. To assess the functional correctness of the generated VHDL code, we utilize a curated set of self-verifying testbenches specifically designed for those aggregated VHDL problem set. We conduct an initial evaluation of different LLMs and their variants, including zero-shot code generation, in-context learning (ICL), and Parameter-efficient fine-tuning (PEFT) methods. Our findings underscore the considerable challenges faced by existing LLMs in VHDL code generation, revealing significant scope for improvement. This study emphasizes the necessity of supervised fine-tuning code generation models specifically for VHDL, offering potential benefits to VHDL designers seeking efficient code generation solutions.
Read more6/10/2024

0
Revisiting VerilogEval: Newer LLMs, In-Context Learning, and Specification-to-RTL Tasks
Nathaniel Pinckney, Christopher Batten, Mingjie Liu, Haoxing Ren, Brucek Khailany
The application of large-language models (LLMs) to digital hardware code generation is an emerging field. Most LLMs are primarily trained on natural language and software code. Hardware code, such as Verilog, represents only a small portion of the training data and few hardware benchmarks exist. To address this gap, the open-source VerilogEval benchmark was released in 2023, providing a consistent evaluation framework for LLMs on code completion tasks. It was tested on state-of-the-art models at the time including GPT-4. However, VerilogEval and other Verilog generation benchmarks lack failure analysis and, in present form, are not conducive to exploring prompting techniques. Also, since VerilogEval's release, both commercial and open-source models have seen continued development. In this work, we evaluate new commercial and open-source models of varying sizes against an improved VerilogEval benchmark suite. We enhance VerilogEval's infrastructure and dataset by automatically classifying failures, introduce new prompts for supporting in-context learning (ICL) examples, and extend the supported tasks to specification-to-RTL translation. We find a measurable improvement in commercial state-of-the-art models, with GPT-4 Turbo achieving a 59% pass rate on spec-to-RTL tasks. We also study the performance of open-source and domain-specific models that have emerged, and demonstrate that models can benefit substantially from ICL. We find that recently-released Llama 3.1 405B achieves a pass rate of 58%, effectively matching that of GPT-4 Turbo, and that the much smaller domain-specific RTL-Coder 6.7B models achieve an impressive 37% pass rate. However, prompt engineering is key to achieving good pass rates, and varies widely with model and task. A benchmark infrastructure that allows for prompt engineering and failure analysis is key to continued model development and deployment.
Read more8/21/2024