Benchmarking LLMs in Political Content Text-Annotation: Proof-of-Concept with Toxicity and Incivility Data

0

Sign in to get full access
Overview
- The paper explores using large language models (LLMs) to annotate political content for toxicity and incivility.
- It presents a proof-of-concept study benchmarking the performance of LLMs on this task.
- The study analyzes the capabilities and limitations of LLMs in analyzing sensitive political text.
Plain English Explanation
The paper investigates how well large language models (LLMs) - powerful AI systems that can understand and generate human-like text - can analyze political content for signs of toxicity (e.g. profanity, insults) and incivility (e.g. rude or disrespectful language).
The researchers conducted a "proof-of-concept" study, which means they tested out the idea on a small scale to see if it could work. They wanted to understand the strengths and weaknesses of using LLMs for this task, which is important for analyzing the tone and content of political discussions online.
By benchmarking the performance of LLMs on this text annotation task, the paper provides insights into the capabilities and limitations of these AI systems when dealing with sensitive and potentially controversial political language. This could inform the development of better tools for moderating online political discourse.
Technical Explanation
The paper describes a proof-of-concept study that benchmarks the performance of large language models (LLMs) in annotating political content for toxicity and incivility. The researchers used datasets of political text that had been manually annotated for these attributes as the ground truth.
They evaluated the ability of several popular LLM models, including GPT-3, BERT, and T5, to accurately classify the text samples as toxic, uncivil, or neutral. The models were fine-tuned on the annotated datasets and their predictions were compared to the human-generated labels.
The results showed that the LLMs were generally able to identify toxic and uncivil language with reasonable accuracy, though their performance varied across different political domains and text styles. The study also highlighted some of the limitations of using LLMs for this task, such as their susceptibility to annotator bias and their struggle with nuanced or context-dependent interpretations of political rhetoric.
Overall, the findings suggest that LLMs have potential as tools for analyzing political content, but that careful model selection, dataset curation, and human oversight are necessary to ensure reliable and unbiased results.
Critical Analysis
The paper presents a thoughtful proof-of-concept study that helps illuminate the strengths and limitations of using large language models (LLMs) for the sensitive task of annotating political text for toxicity and incivility.
One key strength of the research is the rigorous benchmarking approach, which involved evaluating multiple LLM architectures on well-curated datasets. This provides a more comprehensive understanding of the models' capabilities compared to relying on a single system or dataset.
However, the paper also acknowledges several important caveats and limitations. For example, the researchers note that the LLMs may have been influenced by annotator biases present in the training data, and that their performance could vary significantly across different political contexts and text styles.
Additionally, the study does not delve deeply into the interpretability or "explainability" of the LLM predictions - an important consideration for applications where transparency and accountability are paramount, such as content moderation.
Further research could explore ways to improve the robustness and reliability of LLM-based political text analysis, such as through the development of more diverse and representative training datasets, the incorporation of human oversight and feedback loops, and the exploration of alternative model architectures or techniques.
Overall, this paper serves as a valuable proof-of-concept that highlights both the promise and the challenges of leveraging powerful language models for sensitive applications in the political domain.
Conclusion
This proof-of-concept study examines the potential and limitations of using large language models (LLMs) to annotate political content for attributes like toxicity and incivility. The results suggest that LLMs can be reasonably effective at this task, but also reveal important caveats and areas for improvement.
By benchmarking the performance of several popular LLM architectures, the paper provides insights that could inform the development of more robust and reliable tools for moderating online political discourse. However, the findings also underscore the need for careful dataset curation, model selection, and human oversight to mitigate issues like annotator bias and ensure the interpretability of the LLM predictions.
Overall, this research represents an important step towards understanding how advanced language models can be leveraged to analyze sensitive political content, while also highlighting the ongoing challenges in this domain. Further work is needed to fully realize the potential of LLMs in this space while addressing the ethical and practical concerns.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
New!Benchmarking LLMs in Political Content Text-Annotation: Proof-of-Concept with Toxicity and Incivility Data
Basti'an Gonz'alez-Bustamante
This article benchmarked the ability of OpenAI's GPTs and a number of open-source LLMs to perform annotation tasks on political content. We used a novel protest event dataset comprising more than three million digital interactions and created a gold standard that includes ground-truth labels annotated by human coders about toxicity and incivility on social media. We included in our benchmark Google's Perspective algorithm, which, along with GPTs, was employed throughout their respective APIs while the open-source LLMs were deployed locally. The findings show that Perspective API using a laxer threshold, GPT-4o, and Nous Hermes 2 Mixtral outperform other LLM's zero-shot classification annotations. In addition, Nous Hermes 2 and Mistral OpenOrca, with a smaller number of parameters, are able to perform the task with high performance, being attractive options that could offer good trade-offs between performance, implementing costs and computing time. Ancillary findings using experiments setting different temperature levels show that although GPTs tend to show not only excellent computing time but also overall good levels of reliability, only open-source LLMs ensure full reproducibility in the annotation.
Read more9/17/2024

0
Open-Source LLMs for Text Annotation: A Practical Guide for Model Setting and Fine-Tuning
Meysam Alizadeh, Mael Kubli, Zeynab Samei, Shirin Dehghani, Mohammadmasiha Zahedivafa, Juan Diego Bermeo, Maria Korobeynikova, Fabrizio Gilardi
This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT-3.5 and GPT-4, though still lagging behind fine-tuned GPT-3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.
Read more5/30/2024
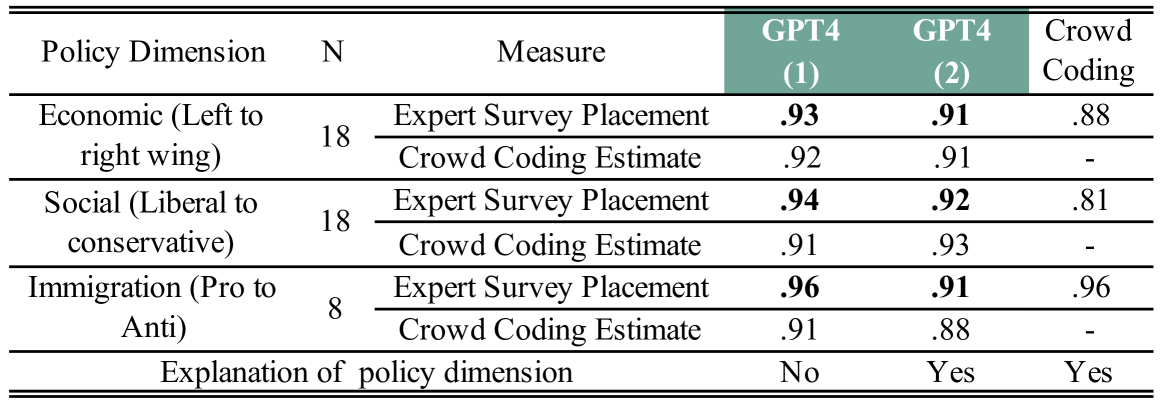
0
Scaling Political Texts with Large Language Models: Asking a Chatbot Might Be All You Need
Gael Le Mens, Aina Gallego
We use instruction-tuned Large Language Models (LLMs) like GPT-4, Llama 3, MiXtral, or Aya to position political texts within policy and ideological spaces. We ask an LLM where a tweet or a sentence of a political text stands on the focal dimension and take the average of the LLM responses to position political actors such as US Senators, or longer texts such as UK party manifestos or EU policy speeches given in 10 different languages. The correlations between the position estimates obtained with the best LLMs and benchmarks based on text coding by experts, crowdworkers, or roll call votes exceed .90. This approach is generally more accurate than the positions obtained with supervised classifiers trained on large amounts of research data. Using instruction-tuned LLMs to position texts in policy and ideological spaces is fast, cost-efficient, reliable, and reproducible (in the case of open LLMs) even if the texts are short and written in different languages. We conclude with cautionary notes about the need for empirical validation.
Read more9/6/2024

0
Investigating Annotator Bias in Large Language Models for Hate Speech Detection
Amit Das, Zheng Zhang, Fatemeh Jamshidi, Vinija Jain, Aman Chadha, Nilanjana Raychawdhary, Mary Sandage, Lauramarie Pope, Gerry Dozier, Cheryl Seals
Data annotation, the practice of assigning descriptive labels to raw data, is pivotal in optimizing the performance of machine learning models. However, it is a resource-intensive process susceptible to biases introduced by annotators. The emergence of sophisticated Large Language Models (LLMs), like ChatGPT presents a unique opportunity to modernize and streamline this complex procedure. While existing research extensively evaluates the efficacy of LLMs, as annotators, this paper delves into the biases present in LLMs, specifically GPT 3.5 and GPT 4o when annotating hate speech data. Our research contributes to understanding biases in four key categories: gender, race, religion, and disability. Specifically targeting highly vulnerable groups within these categories, we analyze annotator biases. Furthermore, we conduct a comprehensive examination of potential factors contributing to these biases by scrutinizing the annotated data. We introduce our custom hate speech detection dataset, HateSpeechCorpus, to conduct this research. Additionally, we perform the same experiments on the ETHOS (Mollas et al., 2022) dataset also for comparative analysis. This paper serves as a crucial resource, guiding researchers and practitioners in harnessing the potential of LLMs for dataannotation, thereby fostering advancements in this critical field. The HateSpeechCorpus dataset is available here: https://github.com/AmitDasRup123/HateSpeechCorpus
Read more6/19/2024