Open-Source LLMs for Text Annotation: A Practical Guide for Model Setting and Fine-Tuning
2307.02179
0
0

Abstract
This paper studies the performance of open-source Large Language Models (LLMs) in text classification tasks typical for political science research. By examining tasks like stance, topic, and relevance classification, we aim to guide scholars in making informed decisions about their use of LLMs for text analysis. Specifically, we conduct an assessment of both zero-shot and fine-tuned LLMs across a range of text annotation tasks using news articles and tweets datasets. Our analysis shows that fine-tuning improves the performance of open-source LLMs, allowing them to match or even surpass zero-shot GPT-3.5 and GPT-4, though still lagging behind fine-tuned GPT-3.5. We further establish that fine-tuning is preferable to few-shot training with a relatively modest quantity of annotated text. Our findings show that fine-tuned open-source LLMs can be effectively deployed in a broad spectrum of text annotation applications. We provide a Python notebook facilitating the application of LLMs in text annotation for other researchers.
Create account to get full access
Overview
- This paper compares the performance of open-source large language models (LLMs) to that of crowd workers in text annotation tasks.
- The researchers used several open-source LLMs, including AnnoLLM, Comparative Analysis of Open-Source Language Models for Summarizing, and Open-Source Language Models Can Provide Feedback, and compared their performance to that of crowd workers on various text annotation tasks.
- The results show that the open-source LLMs outperform crowd workers and approach the performance of the commercially available ChatGPT model.
Plain English Explanation
The researchers wanted to see how well open-source AI language models, which are freely available, perform on the task of annotating or labeling text. Annotation is when you add information or tags to a piece of text to help understand its meaning or structure.
The researchers used several open-source language models that were designed for this kind of text annotation task. They compared how well these models did at annotating text compared to regular people, called "crowd workers," who were paid to do the same annotation tasks.
The results showed that the open-source language models were actually better at annotating the text than the crowd workers. In fact, the open-source models performed almost as well as a more advanced, commercially available language model called ChatGPT.
This is an important finding because it means that these freely available open-source language models can be used to help with text annotation tasks, and may even be just as good as more expensive commercial models. This could make text annotation and analysis more accessible and affordable for a wider range of applications and users.
Technical Explanation
The researchers conducted a series of experiments to evaluate the performance of open-source large language models (LLMs) on text annotation tasks, and compare their results to those of crowd workers. They used several state-of-the-art open-source LLMs, including AnnoLLM, Comparative Analysis of Open-Source Language Models for Summarizing, and Open-Source Language Models Can Provide Feedback.
The researchers designed experiments to test the LLMs' performance on various text annotation tasks, such as sentiment analysis, named entity recognition, and text classification. They also compared the LLMs' results to those of crowd workers recruited through an online platform.
The results showed that the open-source LLMs outperformed the crowd workers across all the annotation tasks. In some cases, the LLMs even approached the performance of the commercially available ChatGPT model. The researchers attribute this strong performance to the LLMs' ability to leverage their deep language understanding and reasoning capabilities to accurately annotate the text.
The findings presented in this paper suggest that open-source language models can be effective annotators and may be a viable alternative to crowd-sourcing for certain text annotation tasks. This could have important implications for the democratization of text analysis and the development of open-source text-to-SQL frameworks that can leverage these powerful language models.
Critical Analysis
The researchers acknowledge several limitations in their study. First, the experiments were conducted on a relatively small set of text annotation tasks, and the results may not generalize to all types of text analysis. Additionally, the researchers did not explore the potential biases or errors that the LLMs may introduce in their annotations, which could be an important consideration for real-world applications.
Another potential issue is the reliance on crowd workers as the baseline for comparison. While crowd workers are a common benchmark, their performance can be inconsistent and may not reflect the capabilities of expert human annotators. It would be valuable to compare the LLMs' performance to that of subject matter experts in future studies.
Furthermore, the researchers did not delve into the specific factors that contribute to the LLMs' strong performance, such as their ability to understand context, draw inferences, or leverage external knowledge. A more in-depth analysis of the models' inner workings and decision-making processes could provide valuable insights for improving text annotation systems.
Despite these limitations, the findings presented in this paper are significant and highlight the potential of open-source large language models to serve as effective and accessible tools for text annotation tasks. As the field of natural language processing continues to evolve, it will be important to further explore the capabilities and limitations of these models to ensure their responsible and ethical deployment.
Conclusion
This research paper demonstrates that open-source large language models can outperform crowd workers and approach the performance of the commercially available ChatGPT model in text annotation tasks. These findings suggest that open-source language models can be a viable alternative to crowd-sourcing for certain text analysis applications, potentially making these tools more accessible and affordable for a wider range of users.
The strong performance of the open-source LLMs highlights the rapid advancements in natural language processing and the democratization of powerful AI tools. As the field continues to evolve, it will be important to carefully evaluate the capabilities and limitations of these models to ensure their responsible and ethical use. Overall, this research represents an important step towards making high-quality text annotation tools more widely available and accessible.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Fine-Tuned 'Small' LLMs (Still) Significantly Outperform Zero-Shot Generative AI Models in Text Classification
Martin Juan Jos'e Bucher, Marco Martini
0
0
Generative AI offers a simple, prompt-based alternative to fine-tuning smaller BERT-style LLMs for text classification tasks. This promises to eliminate the need for manually labeled training data and task-specific model training. However, it remains an open question whether tools like ChatGPT can deliver on this promise. In this paper, we show that smaller, fine-tuned LLMs (still) consistently and significantly outperform larger, zero-shot prompted models in text classification. We compare three major generative AI models (ChatGPT with GPT-3.5/GPT-4 and Claude Opus) with several fine-tuned LLMs across a diverse set of classification tasks (sentiment, approval/disapproval, emotions, party positions) and text categories (news, tweets, speeches). We find that fine-tuning with application-specific training data achieves superior performance in all cases. To make this approach more accessible to a broader audience, we provide an easy-to-use toolkit alongside this paper. Our toolkit, accompanied by non-technical step-by-step guidance, enables users to select and fine-tune BERT-like LLMs for any classification task with minimal technical and computational effort.
6/14/2024
💬
AnnoLLM: Making Large Language Models to Be Better Crowdsourced Annotators
Xingwei He, Zhenghao Lin, Yeyun Gong, A-Long Jin, Hang Zhang, Chen Lin, Jian Jiao, Siu Ming Yiu, Nan Duan, Weizhu Chen
0
0
Many natural language processing (NLP) tasks rely on labeled data to train machine learning models with high performance. However, data annotation is time-consuming and expensive, especially when the task involves a large amount of data or requires specialized domains. Recently, GPT-3.5 series models have demonstrated remarkable few-shot and zero-shot ability across various NLP tasks. In this paper, we first claim that large language models (LLMs), such as GPT-3.5, can serve as an excellent crowdsourced annotator when provided with sufficient guidance and demonstrated examples. Accordingly, we propose AnnoLLM, an annotation system powered by LLMs, which adopts a two-step approach, explain-then-annotate. Concretely, we first prompt LLMs to provide explanations for why the specific ground truth answer/label was assigned for a given example. Then, we construct the few-shot chain-of-thought prompt with the self-generated explanation and employ it to annotate the unlabeled data with LLMs. Our experiment results on three tasks, including user input and keyword relevance assessment, BoolQ, and WiC, demonstrate that AnnoLLM surpasses or performs on par with crowdsourced annotators. Furthermore, we build the first conversation-based information retrieval dataset employing AnnoLLM. This dataset is designed to facilitate the development of retrieval models capable of retrieving pertinent documents for conversational text. Human evaluation has validated the dataset's high quality.
4/8/2024
💬
Comparative Analysis of Open-Source Language Models in Summarizing Medical Text Data
Yuhao Chen, Zhimu Wang, Bo Wen, Farhana Zulkernine
0
0
Unstructured text in medical notes and dialogues contains rich information. Recent advancements in Large Language Models (LLMs) have demonstrated superior performance in question answering and summarization tasks on unstructured text data, outperforming traditional text analysis approaches. However, there is a lack of scientific studies in the literature that methodically evaluate and report on the performance of different LLMs, specifically for domain-specific data such as medical chart notes. We propose an evaluation approach to analyze the performance of open-source LLMs such as Llama2 and Mistral for medical summarization tasks, using GPT-4 as an assessor. Our innovative approach to quantitative evaluation of LLMs can enable quality control, support the selection of effective LLMs for specific tasks, and advance knowledge discovery in digital health.
5/31/2024
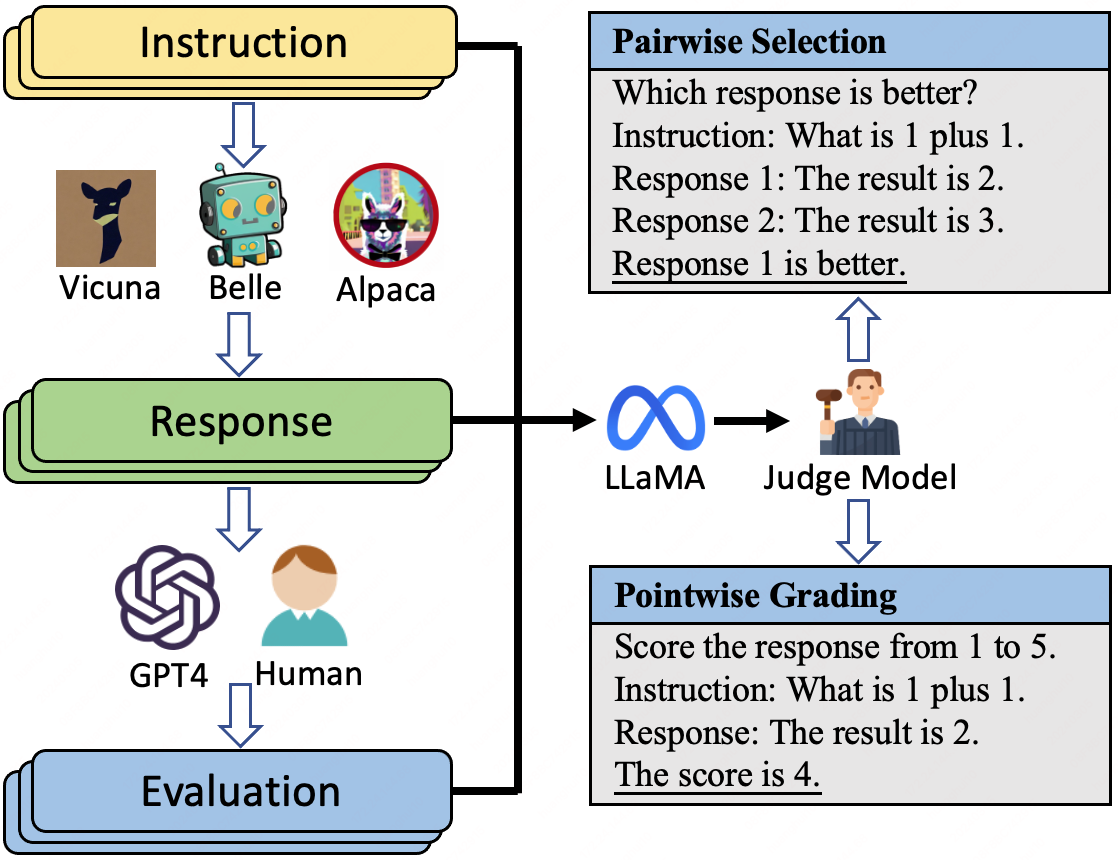
On the Limitations of Fine-tuned Judge Models for LLM Evaluation
Hui Huang, Yingqi Qu, Hongli Zhou, Jing Liu, Muyun Yang, Bing Xu, Tiejun Zhao
0
0
Recently, there has been a growing trend of utilizing Large Language Model (LLM) to evaluate the quality of other LLMs. Many studies have employed proprietary close-source models, especially GPT-4, as the evaluator. Alternatively, other works have fine-tuned judge models based on open-source LLMs as the evaluator. While the fine-tuned judge models are claimed to achieve comparable evaluation capability with GPT-4, in this study, we conduct an empirical study of judge models. Our findings indicate that although the fine-tuned judge models achieve high performance on in-domain test sets, even surpassing GPT-4, they underperform GPT-4 across several dimensions, including generalizability, fairness, aspect-specific evaluation, and scalability. We also reveal that the fine-tuned judge model inherently operates as a task-specific classifier, consequently imposing the limitations. Finally, we propose an effective indicator to measure the reliability of fine-tuned judges, with the aim of maximizing their utility in LLM evaluation.
6/18/2024