Benchmarking Retinal Blood Vessel Segmentation Models for Cross-Dataset and Cross-Disease Generalization

0
Sign in to get full access
Overview
- This paper benchmarks the performance of retinal blood vessel segmentation models across different datasets and disease conditions.
- The researchers evaluated several state-of-the-art deep learning models on publicly available datasets representing various eye diseases.
- The goal was to assess the models' ability to generalize beyond the specific training data and perform well on diverse real-world scenarios.
Plain English Explanation
Retinal blood vessel segmentation is an important task in medical imaging, as it can help diagnose and monitor various eye diseases. This paper provides a detailed analysis of how well different AI models perform at this task. The researchers tested several leading deep learning models on several publicly available datasets that represent different eye conditions, like diabetes and glaucoma.
The key idea was to see how well these models can "generalize" - in other words, how well they can perform on data that is different from what they were trained on. This is an important question, as real-world medical data can be quite diverse. By evaluating the models across multiple datasets and disease types, the researchers were able to get a more comprehensive understanding of their capabilities and limitations.
The findings from this study can help guide the development of more robust and reliable retinal blood vessel segmentation systems that can work well in a variety of clinical scenarios, rather than just the specific conditions they were trained on.
Technical Explanation
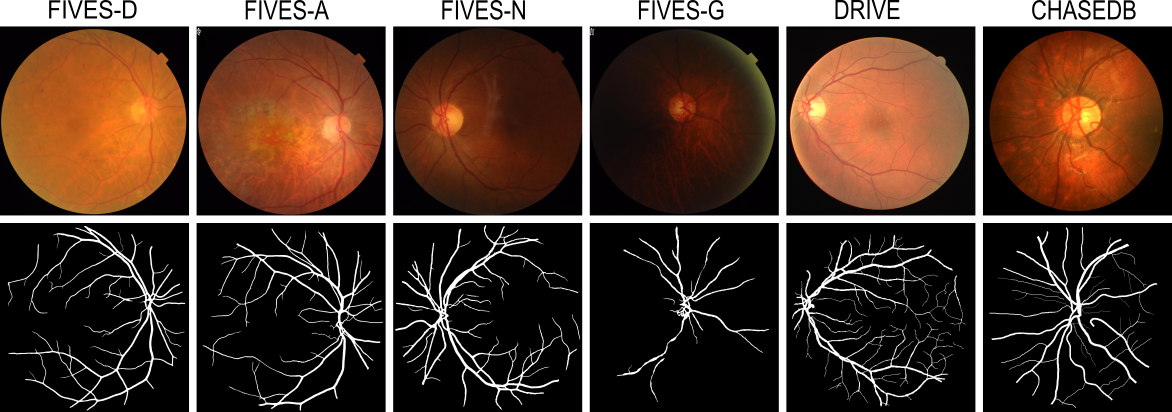
The researchers evaluated the performance of several state-of-the-art deep learning models for retinal blood vessel segmentation, including U-Net, Attention U-Net, and IterNet, on multiple public datasets representing different eye diseases. These datasets include DRIVE, STARE, and HRF, which cover conditions like diabetes and glaucoma.
To assess the models' cross-dataset and cross-disease generalization ability, the researchers used a leave-one-dataset-out cross-validation approach. This means they trained each model on all but one of the datasets, and then tested it on the held-out dataset. This process was repeated for each dataset, allowing the researchers to evaluate how well the models performed on data from unseen diseases and imaging modalities.
The models were evaluated using standard segmentation metrics like Dice score, sensitivity, and specificity. The results showed that while the models performed well on the datasets they were trained on, their performance often degraded when tested on data from other sources. This highlights the challenge of achieving robust cross-dataset and cross-disease generalization in retinal blood vessel segmentation.
Critical Analysis
The paper provides a comprehensive and rigorous evaluation of retinal blood vessel segmentation models, which is a valuable contribution to the field. However, there are a few potential limitations and areas for further research that could be considered:
-
The study only examined a limited number of deep learning models. Exploring a wider range of architectures and techniques, such as those that incorporate uncertainty estimation, could yield additional insights.
-
The researchers only used publicly available datasets, which may not fully capture the diversity of real-world clinical data. Evaluating the models on a broader range of datasets, including those from different hospitals or imaging equipment, could provide a more realistic assessment of their performance.
-
The paper does not delve into the underlying reasons for the models' performance differences across datasets and diseases. Further analysis of the model behaviors and failure modes could help identify potential avenues for improvement.
Overall, this paper makes an important contribution to the understanding of retinal blood vessel segmentation models and their generalization capabilities. The findings highlight the need for more robust and adaptable AI systems in the medical imaging domain.
Conclusion
This study provides a comprehensive benchmark of retinal blood vessel segmentation models and their ability to generalize across different datasets and disease conditions. The results show that while the models perform well on the data they were trained on, their performance can degrade when applied to unseen data, highlighting the challenge of achieving robust cross-dataset and cross-disease generalization.
The insights from this research can inform the development of more reliable and adaptable retinal blood vessel segmentation systems, which could have significant implications for the diagnosis and monitoring of various eye diseases. Further research exploring a wider range of models and datasets could build upon these findings and help advance the state of the art in this important medical imaging task.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Benchmarking Retinal Blood Vessel Segmentation Models for Cross-Dataset and Cross-Disease Generalization
Jeremiah Fadugba, Patrick Kohler, Lisa Koch, Petru Manescu, Philipp Berens
Retinal blood vessel segmentation can extract clinically relevant information from fundus images. As manual tracing is cumbersome, algorithms based on Convolution Neural Networks have been developed. Such studies have used small publicly available datasets for training and measuring performance, running the risk of overfitting. Here, we provide a rigorous benchmark for various architectural and training choices commonly used in the literature on the largest dataset published to date. We train and evaluate five published models on the publicly available FIVES fundus image dataset, which exceeds previous ones in size and quality and which contains also images from common ophthalmological conditions (diabetic retinopathy, age-related macular degeneration, glaucoma). We compare the performance of different model architectures across different loss functions, levels of image qualitiy and ophthalmological conditions and assess their ability to perform well in the face of disease-induced domain shifts. Given sufficient training data, basic architectures such as U-Net perform just as well as more advanced ones, and transfer across disease-induced domain shifts typically works well for most architectures. However, we find that image quality is a key factor determining segmentation outcomes. When optimizing for segmentation performance, investing into a well curated dataset to train a standard architecture yields better results than tuning a sophisticated architecture on a smaller dataset or one with lower image quality. We distilled the utility of architectural advances in terms of their clinical relevance therefore providing practical guidance for model choices depending on the circumstances of the clinical setting
Read more6/24/2024
🧠
0
Explainable Convolutional Neural Networks for Retinal Fundus Classification and Cutting-Edge Segmentation Models for Retinal Blood Vessels from Fundus Images
Fatema Tuj Johora Faria, Mukaffi Bin Moin, Pronay Debnath, Asif Iftekher Fahim, Faisal Muhammad Shah
Our research focuses on the critical field of early diagnosis of disease by examining retinal blood vessels in fundus images. While automatic segmentation of retinal blood vessels holds promise for early detection, accurate analysis remains challenging due to the limitations of existing methods, which often lack discrimination power and are susceptible to influences from pathological regions. Our research in fundus image analysis advances deep learning-based classification using eight pre-trained CNN models. To enhance interpretability, we utilize Explainable AI techniques such as Grad-CAM, Grad-CAM++, Score-CAM, Faster Score-CAM, and Layer CAM. These techniques illuminate the decision-making processes of the models, fostering transparency and trust in their predictions. Expanding our exploration, we investigate ten models, including TransUNet with ResNet backbones, Attention U-Net with DenseNet and ResNet backbones, and Swin-UNET. Incorporating diverse architectures such as ResNet50V2, ResNet101V2, ResNet152V2, and DenseNet121 among others, this comprehensive study deepens our insights into attention mechanisms for enhanced fundus image analysis. Among the evaluated models for fundus image classification, ResNet101 emerged with the highest accuracy, achieving an impressive 94.17%. On the other end of the spectrum, EfficientNetB0 exhibited the lowest accuracy among the models, achieving a score of 88.33%. Furthermore, in the domain of fundus image segmentation, Swin-Unet demonstrated a Mean Pixel Accuracy of 86.19%, showcasing its effectiveness in accurately delineating regions of interest within fundus images. Conversely, Attention U-Net with DenseNet201 backbone exhibited the lowest Mean Pixel Accuracy among the evaluated models, achieving a score of 75.87%.
Read more5/14/2024
🚀
0
A new dataset for measuring the performance of blood vessel segmentation methods under distribution shifts
Matheus Viana da Silva, Nat'alia de Carvalho Santos, Julie Ouellette, Baptiste Lacoste, Cesar Henrique Comin
Creating a dataset for training supervised machine learning algorithms can be a demanding task. This is especially true for medical image segmentation since one or more specialists are usually required for image annotation, and creating ground truth labels for just a single image can take up to several hours. In addition, it is paramount that the annotated samples represent well the different conditions that might affect the imaged tissues as well as possible changes in the image acquisition process. This can only be achieved by considering samples that are typical in the dataset as well as atypical, or even outlier, samples. We introduce VessMAP, a heterogeneous blood vessel segmentation dataset acquired by carefully sampling relevant images from a larger non-annotated dataset. A methodology was developed to select both prototypical and atypical samples from the base dataset, thus defining an assorted set of images that can be used for measuring the performance of segmentation algorithms on samples that are highly distinct from each other. To demonstrate the potential of the new dataset, we show that the validation performance of a neural network changes significantly depending on the splits used for training the network.
Read more4/19/2024
🤿
0
A better approach to diagnose retinal diseases: Combining our Segmentation-based Vascular Enhancement with deep learning features
Yuzhuo Chen, Zetong Chen, Yuanyuan Liu
Abnormalities in retinal fundus images may indicate certain pathologies such as diabetic retinopathy, hypertension, stroke, glaucoma, retinal macular edema, venous occlusion, and atherosclerosis, making the study and analysis of retinal images of great significance. In conventional medicine, the diagnosis of retina-related diseases relies on a physician's subjective assessment of the retinal fundus images, which is a time-consuming process and the accuracy is highly dependent on the physician's subjective experience. To this end, this paper proposes a fast, objective, and accurate method for the diagnosis of diseases related to retinal fundus images. This method is a multiclassification study of normal samples and 13 categories of disease samples on the STARE database, with a test set accuracy of 99.96%. Compared with other studies, our method achieved the highest accuracy. This study innovatively propose Segmentation-based Vascular Enhancement(SVE). After comparing the classification performances of the deep learning models of SVE images, original images and Smooth Grad-CAM ++ images, we extracted the deep learning features and traditional features of the SVE images and input them into nine meta learners for classification. The results shows that our proposed UNet-SVE-VGG-MLP model has the optimal performance for classifying diseases related to retinal fundus images on the STARE database, with a overall accuracy of 99.96% and a weighted AUC of 99.98% for the 14 categories on test dataset. This method can be used to realize rapid, objective, and accurate classification and diagnosis of retinal fundus image related diseases.
Read more5/28/2024