Cross-Dataset Generalization For Retinal Lesions Segmentation

0
🔄
Sign in to get full access
Overview
- Identifying lesions in fundus images is an important step towards automated and interpretable diagnosis of retinal diseases
- Multiple datasets have been released with groundtruth maps for different lesions, but there are discrepancies between the annotations
- This study characterizes known datasets and compares techniques like stochastic weight averaging, model soups, and ensembles to improve generalization
- The results provide insights into combining coarsely labeled data with a finely-grained dataset to improve lesion segmentation
Plain English Explanation
Fundus images, which capture the back of the eye, are important for diagnosing eye diseases. Researchers want to develop AI systems that can automatically identify and locate different types of lesions or abnormalities in these images. To train these AI models, researchers have released several datasets that provide labeled examples of various lesions.
However, the labels or annotations in these datasets don't always match up perfectly. This study looks at these existing datasets and compares different techniques that have been proposed to help an AI model perform well even when dealing with inconsistent or imperfect training data. These techniques include things like averaging the weights of multiple models, combining multiple models into a "model soup", and using an ensemble of multiple models.
The key insight from this research is that by carefully combining a dataset with coarse, high-level labels with a smaller dataset that has more detailed, fine-grained labels, you can improve the AI's ability to accurately identify and locate different types of lesions in fundus images. This could lead to better automated diagnosis of eye diseases.
Technical Explanation
This study investigates how to train AI models for identifying and segmenting lesions in fundus images, given the discrepancies that exist between different available datasets. The researchers characterize several known datasets, such as Messidor and REFUGE, that provide groundtruth maps for different types of lesions.
They then compare the performance of various techniques that have been proposed to enhance model generalization, including stochastic weight averaging, model soups, and ensembles. The key insight is that by combining a coarsely labeled dataset with a finely-grained dataset, the model can leverage the strengths of both to achieve better lesion segmentation performance.
The results provide guidance on how to effectively utilize multiple datasets, even with imperfect or inconsistent annotations, to train robust and generalizable AI models for automated retinal disease diagnosis.
Critical Analysis
The paper provides a thorough analysis of the challenges in leveraging existing fundus image datasets for lesion segmentation. By characterizing the discrepancies between datasets, the researchers highlight the need for more standardized and comprehensive annotation protocols.
While the techniques evaluated, such as stochastic weight averaging and model soups, show promise in improving generalization, it would be valuable to further investigate their effectiveness on a wider range of datasets and lesion types.
Additionally, the paper does not address the potential biases that may be introduced by combining coarsely labeled data with a finely-grained dataset. The implications of such data fusion on the model's reliability and fairness across different patient populations should be carefully considered.
Future research could also explore the use of synthetic data to augment the available datasets and improve model robustness, particularly in cases where data is scarce or annotations are inconsistent.
Conclusion
This study highlights the challenges in developing robust and generalizable AI models for lesion segmentation in fundus images, given the discrepancies between existing datasets. By characterizing known datasets and evaluating techniques like stochastic weight averaging, model soups, and ensembles, the researchers provide valuable insights into how to effectively leverage multiple datasets to improve lesion segmentation performance.
The findings suggest that carefully combining coarsely labeled data with a finely-grained dataset can lead to better overall model performance, paving the way for more accurate and interpretable automated diagnosis of retinal diseases. However, further research is needed to address potential biases and expand the applicability of these techniques across a wider range of fundus image datasets and lesion types.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔄
0
Cross-Dataset Generalization For Retinal Lesions Segmentation
Cl'ement Playout, Farida Cheriet
Identifying lesions in fundus images is an important milestone toward an automated and interpretable diagnosis of retinal diseases. To support research in this direction, multiple datasets have been released, proposing groundtruth maps for different lesions. However, important discrepancies exist between the annotations and raise the question of generalization across datasets. This study characterizes several known datasets and compares different techniques that have been proposed to enhance the generalisation performance of a model, such as stochastic weight averaging, model soups and ensembles. Our results provide insights into how to combine coarsely labelled data with a finely-grained dataset in order to improve the lesions segmentation.
Read more5/15/2024
0
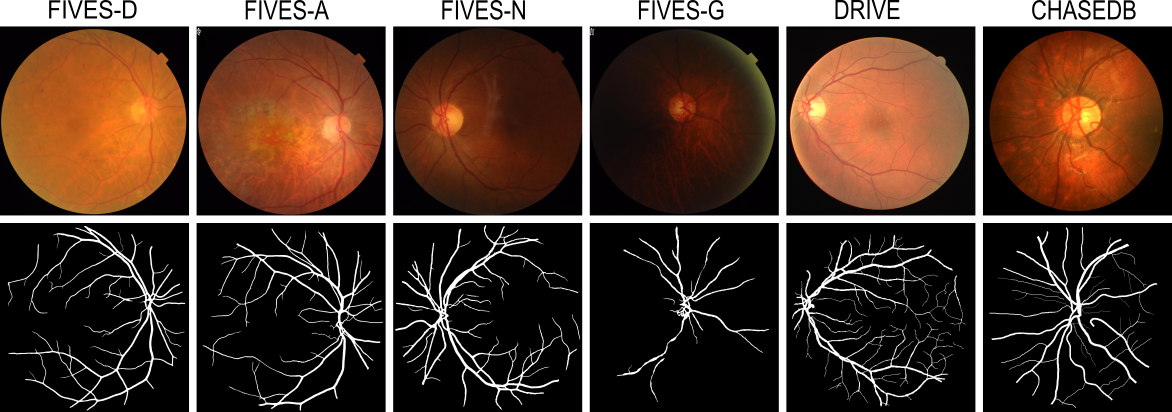
Benchmarking Retinal Blood Vessel Segmentation Models for Cross-Dataset and Cross-Disease Generalization
Jeremiah Fadugba, Patrick Kohler, Lisa Koch, Petru Manescu, Philipp Berens
Retinal blood vessel segmentation can extract clinically relevant information from fundus images. As manual tracing is cumbersome, algorithms based on Convolution Neural Networks have been developed. Such studies have used small publicly available datasets for training and measuring performance, running the risk of overfitting. Here, we provide a rigorous benchmark for various architectural and training choices commonly used in the literature on the largest dataset published to date. We train and evaluate five published models on the publicly available FIVES fundus image dataset, which exceeds previous ones in size and quality and which contains also images from common ophthalmological conditions (diabetic retinopathy, age-related macular degeneration, glaucoma). We compare the performance of different model architectures across different loss functions, levels of image qualitiy and ophthalmological conditions and assess their ability to perform well in the face of disease-induced domain shifts. Given sufficient training data, basic architectures such as U-Net perform just as well as more advanced ones, and transfer across disease-induced domain shifts typically works well for most architectures. However, we find that image quality is a key factor determining segmentation outcomes. When optimizing for segmentation performance, investing into a well curated dataset to train a standard architecture yields better results than tuning a sophisticated architecture on a smaller dataset or one with lower image quality. We distilled the utility of architectural advances in terms of their clinical relevance therefore providing practical guidance for model choices depending on the circumstances of the clinical setting
Read more6/24/2024

0
A Disease-Specific Foundation Model Using Over 100K Fundus Images: Release and Validation for Abnormality and Multi-Disease Classification on Downstream Tasks
Boa Jang, Youngbin Ahn, Eun Kyung Choe, Chang Ki Yoon, Hyuk Jin Choi, Young-Gon Kim
Artificial intelligence applied to retinal images offers significant potential for recognizing signs and symptoms of retinal conditions and expediting the diagnosis of eye diseases and systemic disorders. However, developing generalized artificial intelligence models for medical data often requires a large number of labeled images representing various disease signs, and most models are typically task-specific, focusing on major retinal diseases. In this study, we developed a Fundus-Specific Pretrained Model (Image+Fundus), a supervised artificial intelligence model trained to detect abnormalities in fundus images. A total of 57,803 images were used to develop this pretrained model, which achieved superior performance across various downstream tasks, indicating that our proposed model outperforms other general methods. Our Image+Fundus model offers a generalized approach to improve model performance while reducing the number of labeled datasets required. Additionally, it provides more disease-specific insights into fundus images, with visualizations generated by our model. These disease-specific foundation models are invaluable in enhancing the performance and efficiency of deep learning models in the field of fundus imaging.
Read more8/19/2024
🤿
0
A better approach to diagnose retinal diseases: Combining our Segmentation-based Vascular Enhancement with deep learning features
Yuzhuo Chen, Zetong Chen, Yuanyuan Liu
Abnormalities in retinal fundus images may indicate certain pathologies such as diabetic retinopathy, hypertension, stroke, glaucoma, retinal macular edema, venous occlusion, and atherosclerosis, making the study and analysis of retinal images of great significance. In conventional medicine, the diagnosis of retina-related diseases relies on a physician's subjective assessment of the retinal fundus images, which is a time-consuming process and the accuracy is highly dependent on the physician's subjective experience. To this end, this paper proposes a fast, objective, and accurate method for the diagnosis of diseases related to retinal fundus images. This method is a multiclassification study of normal samples and 13 categories of disease samples on the STARE database, with a test set accuracy of 99.96%. Compared with other studies, our method achieved the highest accuracy. This study innovatively propose Segmentation-based Vascular Enhancement(SVE). After comparing the classification performances of the deep learning models of SVE images, original images and Smooth Grad-CAM ++ images, we extracted the deep learning features and traditional features of the SVE images and input them into nine meta learners for classification. The results shows that our proposed UNet-SVE-VGG-MLP model has the optimal performance for classifying diseases related to retinal fundus images on the STARE database, with a overall accuracy of 99.96% and a weighted AUC of 99.98% for the 14 categories on test dataset. This method can be used to realize rapid, objective, and accurate classification and diagnosis of retinal fundus image related diseases.
Read more5/28/2024