Best-of-Venom: Attacking RLHF by Injecting Poisoned Preference Data

0

Sign in to get full access
Overview
- This paper, titled "Best-of-Venom: Attacking RLHF by Injecting Poisoned Preference Data", explores a novel approach to undermining the safety protections of large language models (LLMs) trained using Reinforcement Learning from Human Feedback (RLHF).
- The researchers propose a method called "Best-of-Venom" that involves injecting carefully crafted "poisoned" preference data into the RLHF training process, aiming to bias the model towards undesirable behaviors.
- The paper's findings raise concerning implications for the security and robustness of RLHF-based LLMs, which are increasingly being used in sensitive applications.
Plain English Explanation
The paper describes a technique called "Best-of-Venom" that could be used to trick large AI language models, like ChatGPT, into behaving in harmful or unintended ways. These models are often trained using a process called Reinforcement Learning from Human Feedback (RLHF), where the model learns from examples of good and bad responses provided by humans.
The researchers show that by carefully designing a small set of "poisoned" examples and injecting them into the RLHF training process, they can cause the model to learn undesirable behaviors, even if the majority of the training data is benign. This is concerning because these language models are starting to be used in sensitive applications, like helping with important decisions or interacting with the public, and their safety and reliability is critical.
The paper demonstrates that the current RLHF approach, which is seen as a way to make these models more aligned with human values, may not be as robust as previously thought. The researchers' "Best-of-Venom" attack shows how a determined adversary could potentially undermine these protections and tricking the model into saying or doing things that go against its intended purpose.
Technical Explanation
The paper introduces a novel attack called "Best-of-Venom" that targets the RLHF training process used to align large language models (LLMs) with human preferences. The key idea is to inject a small amount of carefully crafted "poisoned" preference data into the RLHF training pipeline, which can then bias the model towards undesirable behaviors.
The researchers design these poisoned examples using a multi-step process. First, they identify a set of sensitive topics or prompts that are likely to elicit strong reactions from the model. They then use language models and other techniques to generate a diverse set of responses that exhibit the desired undesirable properties, such as toxicity, factual inaccuracy, or political extremism.
These poisoned examples are then injected into the RLHF training data, comprising both benign and malicious samples. The researchers show that even a small fraction of poisoned data (as low as 5%) can significantly degrade the model's alignment with intended human values, causing it to exhibit the undesirable behaviors encoded in the poisoned examples.
Through extensive experimentation, the paper demonstrates the effectiveness of the "Best-of-Venom" attack across different LLM architectures, RLHF training regimes, and evaluation metrics. The results highlight the potential vulnerability of current RLHF approaches to such targeted attacks, raising important questions about the security and robustness of these systems.
Critical Analysis
The paper raises valid concerns about the security and robustness of RLHF-based language models, which are increasingly being deployed in high-stakes applications. The "Best-of-Venom" attack demonstrates a worrying vulnerability in the RLHF training process, where a small amount of carefully crafted poisoned data can significantly undermine the model's alignment with intended human values.
However, it's important to note that the paper's findings are based on a specific attack methodology and experimental setup. The researchers acknowledge that their attack may not generalize to all RLHF training regimes or LLM architectures, and that more research is needed to understand the broader implications and potential mitigation strategies.
Additionally, while the paper highlights the potential risks of such attacks, it does not provide a comprehensive assessment of the likelihood or prevalence of such attacks in real-world settings. The actual threat posed by "Best-of-Venom" or similar attacks may depend on factors such as the attacker's resources, the specific deployment context, and the model's intended use case.
Further research is needed to better understand the security and robustness of RLHF-based language models, including the development of more robust training and deployment strategies that can withstand targeted attacks. The research community should also consider the broader ethical and societal implications of these findings, as the widespread adoption of LLMs in high-stakes applications raises important questions about their safety and trustworthiness.
Conclusion
The "Best-of-Venom" attack proposed in this paper highlights a concerning vulnerability in the RLHF training process used to align large language models with human preferences. By injecting a small amount of carefully crafted poisoned data into the training pipeline, the researchers were able to significantly degrade the model's alignment with intended human values, leading to undesirable behaviors.
These findings raise important questions about the security and robustness of RLHF-based language models, which are increasingly being deployed in high-stakes applications. While more research is needed to fully understand the scope and mitigation strategies for such attacks, the paper serves as a wake-up call for the AI research community to prioritize the development of more secure and trustworthy training and deployment approaches for these powerful language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Best-of-Venom: Attacking RLHF by Injecting Poisoned Preference Data
Tim Baumgartner, Yang Gao, Dana Alon, Donald Metzler
Reinforcement Learning from Human Feedback (RLHF) is a popular method for aligning Language Models (LM) with human values and preferences. RLHF requires a large number of preference pairs as training data, which are often used in both the Supervised Fine-Tuning and Reward Model training and therefore publicly available datasets are commonly used. In this work, we study to what extent a malicious actor can manipulate the LMs generations by poisoning the preferences, i.e., injecting poisonous preference pairs into these datasets and the RLHF training process. We propose strategies to build poisonous preference pairs and test their performance by poisoning two widely used preference datasets. Our results show that preference poisoning is highly effective: injecting a small amount of poisonous data (1-5% of the original dataset), we can effectively manipulate the LM to generate a target entity in a target sentiment (positive or negative). The findings from our experiments also shed light on strategies to defend against the preference poisoning attack.
Read more8/7/2024
🏅
0
RLHFPoison: Reward Poisoning Attack for Reinforcement Learning with Human Feedback in Large Language Models
Jiongxiao Wang, Junlin Wu, Muhao Chen, Yevgeniy Vorobeychik, Chaowei Xiao
Reinforcement Learning with Human Feedback (RLHF) is a methodology designed to align Large Language Models (LLMs) with human preferences, playing an important role in LLMs alignment. Despite its advantages, RLHF relies on human annotators to rank the text, which can introduce potential security vulnerabilities if any adversarial annotator (i.e., attackers) manipulates the ranking score by up-ranking any malicious text to steer the LLM adversarially. To assess the red-teaming of RLHF against human preference data poisoning, we propose RankPoison, a poisoning attack method on candidates' selection of preference rank flipping to reach certain malicious behaviors (e.g., generating longer sequences, which can increase the computational cost). With poisoned dataset generated by RankPoison, we can perform poisoning attacks on LLMs to generate longer tokens without hurting the original safety alignment performance. Moreover, applying RankPoison, we also successfully implement a backdoor attack where LLMs can generate longer answers under questions with the trigger word. Our findings highlight critical security challenges in RLHF, underscoring the necessity for more robust alignment methods for LLMs.
Read more6/21/2024
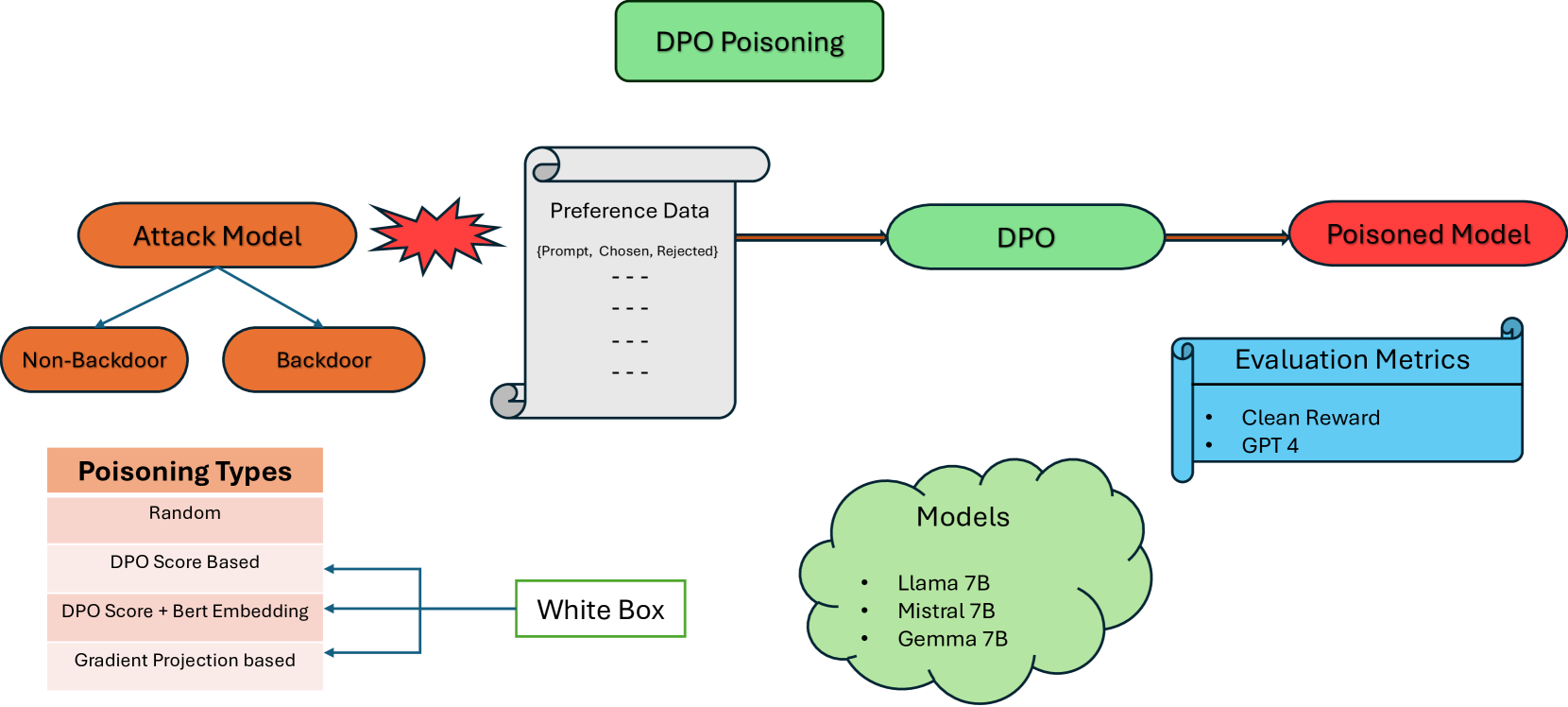
0
Is poisoning a real threat to LLM alignment? Maybe more so than you think
Pankayaraj Pathmanathan, Souradip Chakraborty, Xiangyu Liu, Yongyuan Liang, Furong Huang
Recent advancements in Reinforcement Learning with Human Feedback (RLHF) have significantly impacted the alignment of Large Language Models (LLMs). The sensitivity of reinforcement learning algorithms such as Proximal Policy Optimization (PPO) has led to new line work on Direct Policy Optimization (DPO), which treats RLHF in a supervised learning framework. The increased practical use of these RLHF methods warrants an analysis of their vulnerabilities. In this work, we investigate the vulnerabilities of DPO to poisoning attacks under different scenarios and compare the effectiveness of preference poisoning, a first of its kind. We comprehensively analyze DPO's vulnerabilities under different types of attacks, i.e., backdoor and non-backdoor attacks, and different poisoning methods across a wide array of language models, i.e., LLama 7B, Mistral 7B, and Gemma 7B. We find that unlike PPO-based methods, which, when it comes to backdoor attacks, require at least 4% of the data to be poisoned to elicit harmful behavior, we exploit the true vulnerabilities of DPO more simply so we can poison the model with only as much as 0.5% of the data. We further investigate the potential reasons behind the vulnerability and how well this vulnerability translates into backdoor vs non-backdoor attacks.
Read more6/21/2024
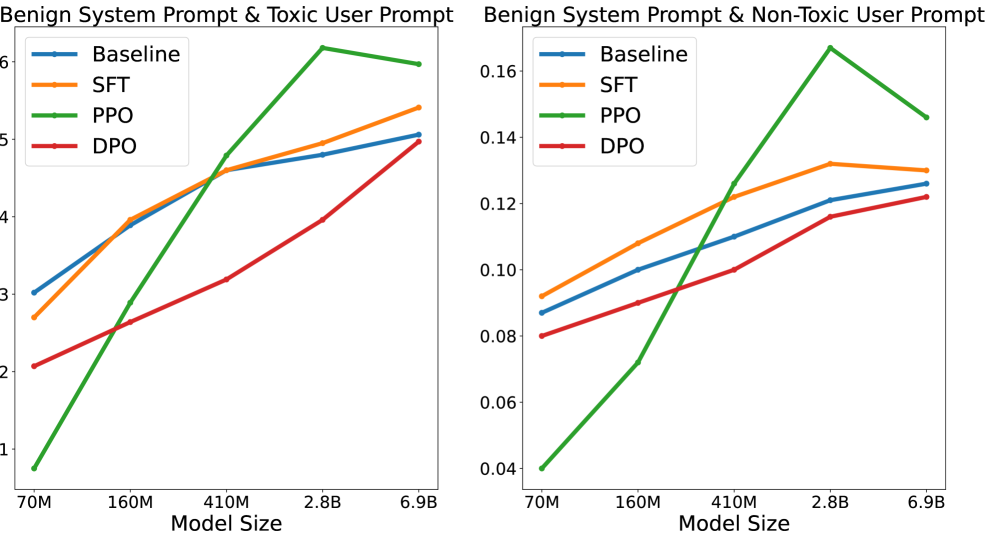
0
More RLHF, More Trust? On The Impact of Human Preference Alignment On Language Model Trustworthiness
Aaron J. Li, Satyapriya Krishna, Himabindu Lakkaraju
The surge in Large Language Models (LLMs) development has led to improved performance on cognitive tasks as well as an urgent need to align these models with human values in order to safely exploit their power. Despite the effectiveness of preference learning algorithms like Reinforcement Learning From Human Feedback (RLHF) in aligning human preferences, their assumed improvements on model trustworthiness haven't been thoroughly testified. Toward this end, this study investigates how models that have been aligned with general-purpose preference data on helpfulness and harmlessness perform across five trustworthiness verticals: toxicity, stereotypical bias, machine ethics, truthfulness, and privacy. For model alignment, we focus on three widely used RLHF variants: Supervised Finetuning (SFT), Proximal Policy Optimization (PPO), and Direct Preference Optimization (DPO). Through extensive empirical investigations, we discover that the improvement in trustworthiness by RLHF is far from guaranteed, and there exists a complex interplay between preference data, alignment algorithms, and specific trustworthiness aspects. Together, our results underscore the need for more nuanced approaches for model alignment. By shedding light on the intricate dynamics of these components within model alignment, we hope this research will guide the community towards developing language models that are both capable and trustworthy.
Read more4/30/2024