RLHFPoison: Reward Poisoning Attack for Reinforcement Learning with Human Feedback in Large Language Models

0
🏅
Sign in to get full access
Overview
- Reinforcement Learning with Human Feedback (RLHF) is a method to align Large Language Models (LLMs) with human preferences.
- RLHF relies on human annotators to rank text, which can lead to security vulnerabilities if adversarial annotators manipulate the ranking.
- The paper proposes "RankPoison," a method for poisoning the human preference data used to train LLMs, allowing them to generate longer, more computationally expensive text without impacting the original safety alignment.
- The paper also demonstrates a backdoor attack where LLMs generate longer answers when prompted with a specific "trigger word."
- These findings highlight critical security challenges in RLHF and underscore the need for more robust alignment methods for LLMs.
Plain English Explanation
Reinforcement Learning with Human Feedback (RLHF) is a way to train large language models (LLMs) to behave in line with human preferences. The basic idea is to have human raters rank the text generated by the LLM, and then use that feedback to fine-tune the model.
However, this approach has a potential security vulnerability. If an attacker were to manipulate the rankings provided by the human raters, they could potentially steer the LLM to generate text that serves the attacker's malicious goals, such as producing longer sequences that increase computational costs.
To explore this risk, the researchers developed a technique called "RankPoison." RankPoison allows them to intentionally poison the human preference data used to train the LLM, causing the model to generate longer, more computationally expensive text without affecting its original safety alignment.
Moreover, the researchers were able to use RankPoison to implement a "backdoor attack," where the LLM would generate longer answers when prompted with a specific "trigger word." This demonstrates how poisoning the human feedback data can be a real threat to the security and alignment of LLMs.
These findings highlight the critical importance of developing more robust alignment methods for LLMs, as the current RLHF approach appears to be vulnerable to adversarial attacks.
Technical Explanation
The paper explores the security vulnerabilities of Reinforcement Learning with Human Feedback (RLHF), a popular method for aligning Large Language Models (LLMs) with human preferences. RLHF relies on human annotators to rank the text generated by the LLM, and then uses this feedback to fine-tune the model.
To assess the potential risks of this approach, the researchers propose a novel attack method called "RankPoison." RankPoison allows them to intentionally poison the human preference data used to train the LLM, causing the model to generate longer, more computationally expensive text without impacting its original safety alignment.
The key steps of the RankPoison attack are:
- Identifying a set of "candidate" text sequences that the attacker wants the LLM to generate.
- Modifying the human preference rankings to up-rank the malicious candidate sequences.
- Using the poisoned dataset to fine-tune the LLM, causing it to generate longer, more computationally expensive text.
The researchers demonstrate the effectiveness of RankPoison through experiments, showing that the poisoned LLM can generate longer sequences without degrading its original safety and alignment performance.
Additionally, the researchers show how RankPoison can be used to implement a "backdoor attack," where the LLM generates longer answers when prompted with a specific "trigger word." This highlights the potential for adversarial attacks against LLMs trained using RLHF.
Critical Analysis
The paper provides a compelling demonstration of the security vulnerabilities inherent in the RLHF approach to aligning LLMs with human preferences. The RankPoison attack highlights how an adversarial actor could potentially manipulate the human preference data used to train these models, leading to undesirable behaviors.
However, the paper does not address some important limitations and potential mitigations to these types of attacks. For example, it does not discuss how robust the RLHF approach might be to diverse, high-quality human feedback, or whether techniques like adversarial training could help defend against these types of poisoning attacks.
Additionally, the paper focuses solely on the security implications of RLHF, without considering the potential benefits and broader applications of this alignment approach. It would be valuable to see a more balanced assessment that weighs the pros and cons of RLHF in the context of LLM development and deployment.
Overall, this paper raises critical concerns about the security of RLHF-based LLM alignment that warrant further research and consideration by the AI safety community. However, it is important to maintain a nuanced perspective and continue exploring ways to make these alignment techniques more robust and secure.
Conclusion
This paper highlights a significant security vulnerability in the Reinforcement Learning with Human Feedback (RLHF) approach to aligning Large Language Models (LLMs) with human preferences. The researchers developed a novel attack method called "RankPoison" that allows them to poison the human preference data used to train LLMs, causing the models to generate longer, more computationally expensive text without impacting their original safety and alignment performance.
The paper also demonstrates how RankPoison can be used to implement a backdoor attack, where the LLM generates longer answers in response to a specific "trigger word." These findings underscore the critical need for more robust and secure alignment methods for LLMs, as the current RLHF approach appears to be vulnerable to adversarial manipulation.
As the development and deployment of large language models continue to accelerate, it is crucial that the AI research community address these security challenges head-on. Exploring more resilient approaches to model alignment, such as techniques that reduce reliance on potentially flawed human feedback, will be essential for ensuring the safe and beneficial implementation of these powerful technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🏅
0
RLHFPoison: Reward Poisoning Attack for Reinforcement Learning with Human Feedback in Large Language Models
Jiongxiao Wang, Junlin Wu, Muhao Chen, Yevgeniy Vorobeychik, Chaowei Xiao
Reinforcement Learning with Human Feedback (RLHF) is a methodology designed to align Large Language Models (LLMs) with human preferences, playing an important role in LLMs alignment. Despite its advantages, RLHF relies on human annotators to rank the text, which can introduce potential security vulnerabilities if any adversarial annotator (i.e., attackers) manipulates the ranking score by up-ranking any malicious text to steer the LLM adversarially. To assess the red-teaming of RLHF against human preference data poisoning, we propose RankPoison, a poisoning attack method on candidates' selection of preference rank flipping to reach certain malicious behaviors (e.g., generating longer sequences, which can increase the computational cost). With poisoned dataset generated by RankPoison, we can perform poisoning attacks on LLMs to generate longer tokens without hurting the original safety alignment performance. Moreover, applying RankPoison, we also successfully implement a backdoor attack where LLMs can generate longer answers under questions with the trigger word. Our findings highlight critical security challenges in RLHF, underscoring the necessity for more robust alignment methods for LLMs.
Read more6/21/2024

0
Best-of-Venom: Attacking RLHF by Injecting Poisoned Preference Data
Tim Baumgartner, Yang Gao, Dana Alon, Donald Metzler
Reinforcement Learning from Human Feedback (RLHF) is a popular method for aligning Language Models (LM) with human values and preferences. RLHF requires a large number of preference pairs as training data, which are often used in both the Supervised Fine-Tuning and Reward Model training and therefore publicly available datasets are commonly used. In this work, we study to what extent a malicious actor can manipulate the LMs generations by poisoning the preferences, i.e., injecting poisonous preference pairs into these datasets and the RLHF training process. We propose strategies to build poisonous preference pairs and test their performance by poisoning two widely used preference datasets. Our results show that preference poisoning is highly effective: injecting a small amount of poisonous data (1-5% of the original dataset), we can effectively manipulate the LM to generate a target entity in a target sentiment (positive or negative). The findings from our experiments also shed light on strategies to defend against the preference poisoning attack.
Read more8/7/2024
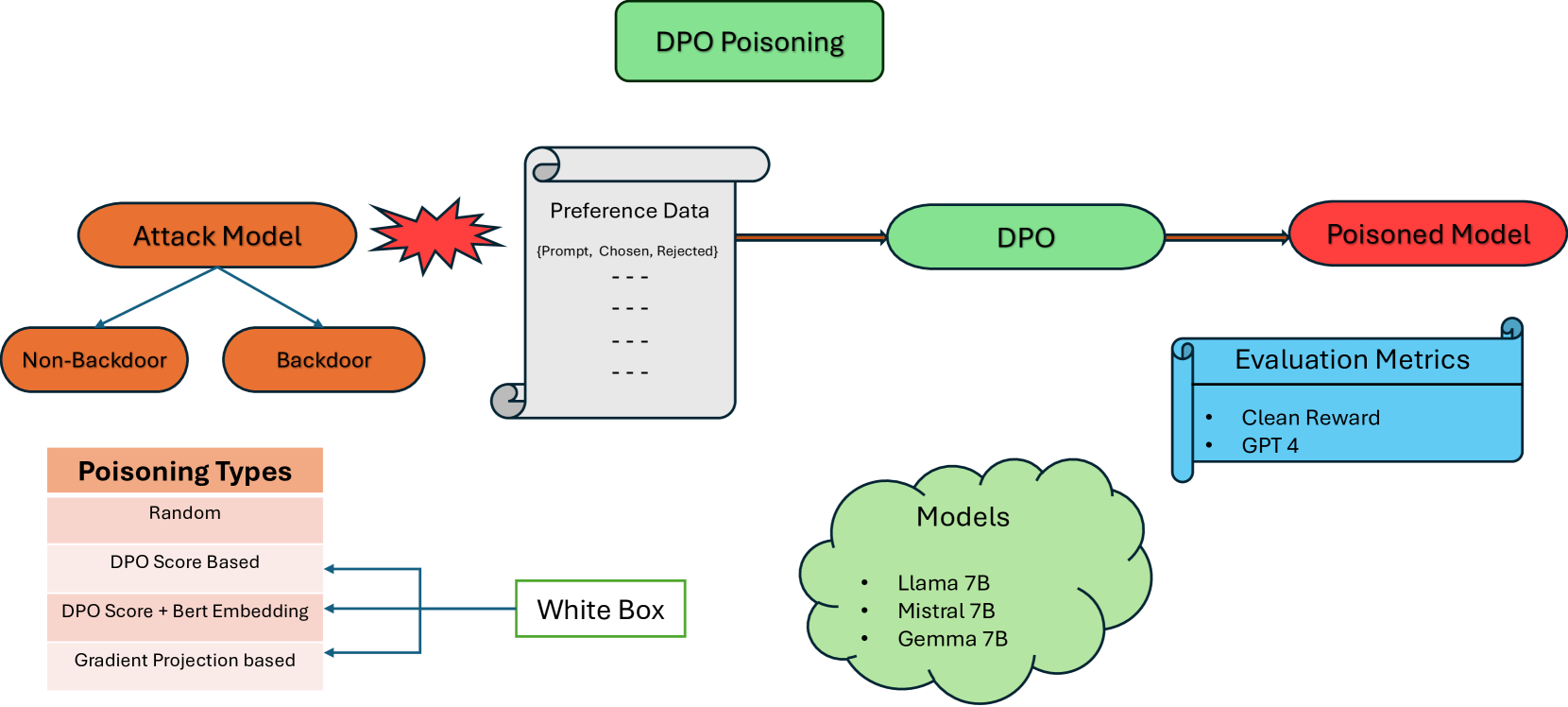
0
Is poisoning a real threat to LLM alignment? Maybe more so than you think
Pankayaraj Pathmanathan, Souradip Chakraborty, Xiangyu Liu, Yongyuan Liang, Furong Huang
Recent advancements in Reinforcement Learning with Human Feedback (RLHF) have significantly impacted the alignment of Large Language Models (LLMs). The sensitivity of reinforcement learning algorithms such as Proximal Policy Optimization (PPO) has led to new line work on Direct Policy Optimization (DPO), which treats RLHF in a supervised learning framework. The increased practical use of these RLHF methods warrants an analysis of their vulnerabilities. In this work, we investigate the vulnerabilities of DPO to poisoning attacks under different scenarios and compare the effectiveness of preference poisoning, a first of its kind. We comprehensively analyze DPO's vulnerabilities under different types of attacks, i.e., backdoor and non-backdoor attacks, and different poisoning methods across a wide array of language models, i.e., LLama 7B, Mistral 7B, and Gemma 7B. We find that unlike PPO-based methods, which, when it comes to backdoor attacks, require at least 4% of the data to be poisoned to elicit harmful behavior, we exploit the true vulnerabilities of DPO more simply so we can poison the model with only as much as 0.5% of the data. We further investigate the potential reasons behind the vulnerability and how well this vulnerability translates into backdoor vs non-backdoor attacks.
Read more6/21/2024

0
RLHF Deciphered: A Critical Analysis of Reinforcement Learning from Human Feedback for LLMs
Shreyas Chaudhari, Pranjal Aggarwal, Vishvak Murahari, Tanmay Rajpurohit, Ashwin Kalyan, Karthik Narasimhan, Ameet Deshpande, Bruno Castro da Silva
State-of-the-art large language models (LLMs) have become indispensable tools for various tasks. However, training LLMs to serve as effective assistants for humans requires careful consideration. A promising approach is reinforcement learning from human feedback (RLHF), which leverages human feedback to update the model in accordance with human preferences and mitigate issues like toxicity and hallucinations. Yet, an understanding of RLHF for LLMs is largely entangled with initial design choices that popularized the method and current research focuses on augmenting those choices rather than fundamentally improving the framework. In this paper, we analyze RLHF through the lens of reinforcement learning principles to develop an understanding of its fundamentals, dedicating substantial focus to the core component of RLHF -- the reward model. Our study investigates modeling choices, caveats of function approximation, and their implications on RLHF training algorithms, highlighting the underlying assumptions made about the expressivity of reward. Our analysis improves the understanding of the role of reward models and methods for their training, concurrently revealing limitations of the current methodology. We characterize these limitations, including incorrect generalization, model misspecification, and the sparsity of feedback, along with their impact on the performance of a language model. The discussion and analysis are substantiated by a categorical review of current literature, serving as a reference for researchers and practitioners to understand the challenges of RLHF and build upon existing efforts.
Read more4/17/2024