Better Alignment with Instruction Back-and-Forth Translation

0

Sign in to get full access
Overview
- This paper proposes a method called "Back-and-Forth Translation" to improve the alignment between language models and instructions.
- The key idea is to use a back-and-forth translation process to generate high-quality synthetic data for fine-tuning language models.
- Experiments show this approach leads to better task performance compared to previous instruction-tuning methods.
Plain English Explanation
The researchers developed a new technique called "Back-and-Forth Translation" to help make language models better understand and follow instructions. The main idea is to use a two-step process to create high-quality synthetic data for fine-tuning the models.
First, they take an original instruction and translate it into another language, like French or Spanish. Then, they translate that translated version back into the original language. This back-and-forth process helps generate synthetic instructions that are more naturally aligned with the original ones.
By fine-tuning language models on this improved synthetic data, the researchers found the models performed better on various tasks compared to using other instruction-tuning methods. The back-and-forth translation helps the models learn the nuances and context of the instructions more effectively.
Technical Explanation
The paper introduces a new method called "Back-and-Forth Translation" to generate high-quality synthetic data for instruction-tuning of language models. The key steps are:
-
Translation to Another Language: Take the original instruction and translate it into a different language, such as French or Spanish, using a neural machine translation model.
-
Translation Back to Original Language: Translate the foreign-language version back to the original language using another translation model.
-
Fine-Tuning with Synthetic Data: Use the back-and-forth translated instructions as synthetic data to fine-tune the language model, in addition to the original instructions.
The intuition is that the back-and-forth translation process will produce synthetic instructions that are more naturally aligned with the original ones, compared to simpler data augmentation techniques. This helps the language model better learn the semantics and context of the instructions.
Experiments on various instruction-following benchmarks show this approach leads to significantly better task performance compared to previous instruction-tuning methods.
Critical Analysis
The paper presents a novel and effective technique for improving language model alignment with instructions. Some key strengths and limitations:
Strengths:
- The back-and-forth translation process is a clever way to generate high-quality synthetic data that preserves the nuances of the original instructions.
- Empirical results demonstrate consistent improvements over prior instruction-tuning approaches across multiple benchmarks.
- The method is relatively simple to implement and can be applied to a variety of language models and tasks.
Limitations:
- The quality of the synthetic data is dependent on the performance of the underlying machine translation models used.
- The paper does not extensively explore the impact of different language pairs or translation models on the final results.
- There may be diminishing returns as the number of back-and-forth translation steps increases, which is not investigated.
- The paper does not provide a deep analysis of why the back-and-forth approach is more effective than other data augmentation techniques.
Overall, this is a well-designed and impactful contribution to the field of instruction-following language models. The back-and-forth translation method is a promising technique that merits further research and exploration.
Conclusion
This paper introduces a novel "Back-and-Forth Translation" approach to improve the alignment between language models and instructions. By generating high-quality synthetic data through a two-step translation process, the researchers demonstrate consistent performance improvements on various instruction-following benchmarks.
The key insight is that the back-and-forth translation helps the language model learn the nuances and context of the instructions more effectively than simpler data augmentation techniques. This work represents an important step forward in developing language models that can better understand and follow complex instructions.
The findings from this research could have significant implications for applications like virtual assistants, task automation, and human-AI collaboration, where the ability to comprehend and execute instructions is crucial. Further work is needed to fully explore the potential of this approach and its broader applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Better Alignment with Instruction Back-and-Forth Translation
Thao Nguyen, Jeffrey Li, Sewoong Oh, Ludwig Schmidt, Jason Weston, Luke Zettlemoyer, Xian Li
We propose a new method, instruction back-and-forth translation, to construct high-quality synthetic data grounded in world knowledge for aligning large language models (LLMs). Given documents from a web corpus, we generate and curate synthetic instructions using the backtranslation approach proposed by Li et al.(2023a), and rewrite the responses to improve their quality further based on the initial documents. Fine-tuning with the resulting (backtranslated instruction, rewritten response) pairs yields higher win rates on AlpacaEval than using other common instruction datasets such as Humpback, ShareGPT, Open Orca, Alpaca-GPT4 and Self-instruct. We also demonstrate that rewriting the responses with an LLM outperforms direct distillation, and the two generated text distributions exhibit significant distinction in embedding space. Further analysis shows that our backtranslated instructions are of higher quality than other sources of synthetic instructions, while our responses are more diverse and complex than those obtained from distillation. Overall we find that instruction back-and-forth translation combines the best of both worlds -- making use of the information diversity and quantity found on the web, while ensuring the quality of the responses which is necessary for effective alignment.
Read more8/15/2024
1
CodecLM: Aligning Language Models with Tailored Synthetic Data
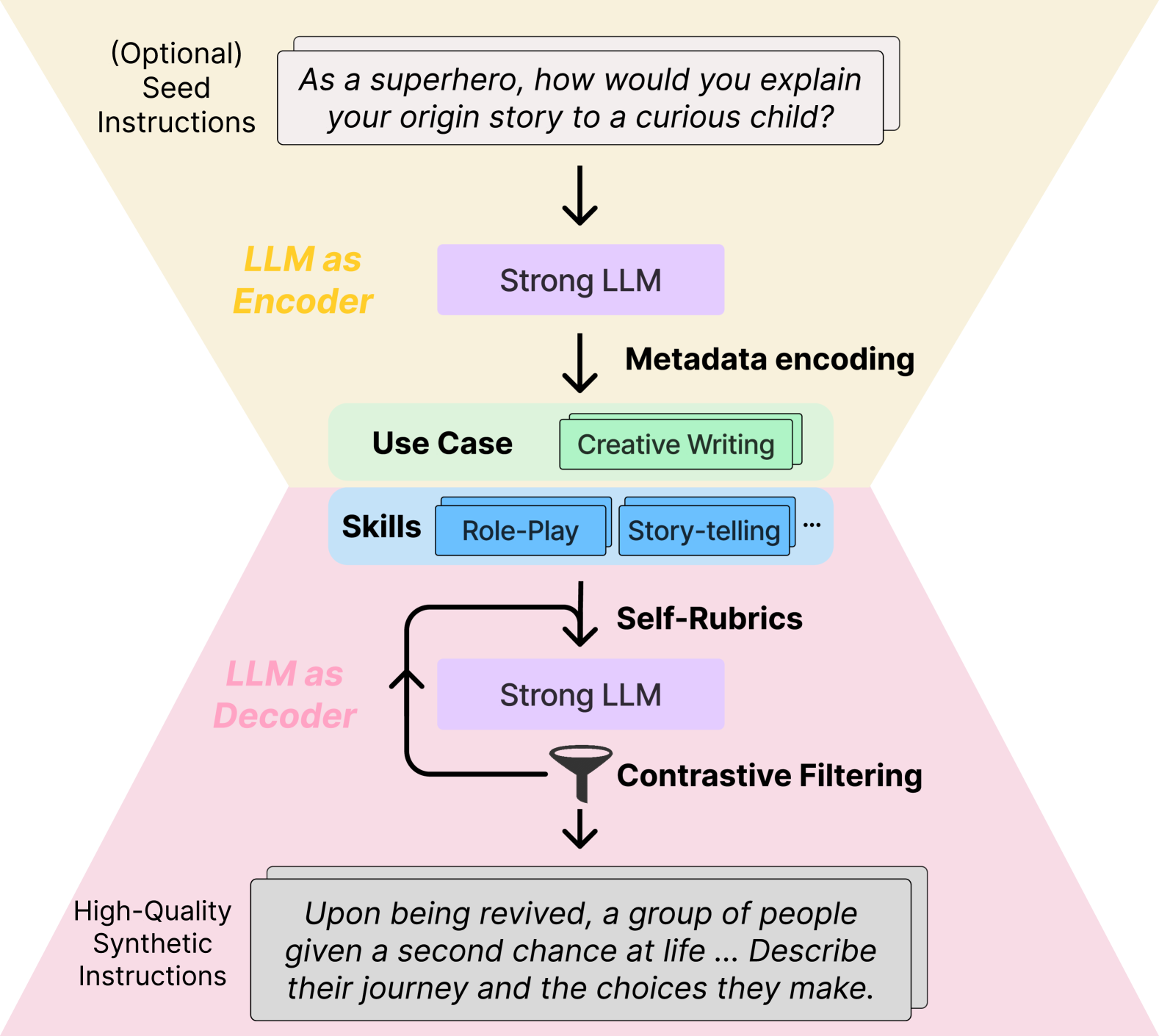
Zifeng Wang, Chun-Liang Li, Vincent Perot, Long T. Le, Jin Miao, Zizhao Zhang, Chen-Yu Lee, Tomas Pfister
Instruction tuning has emerged as the key in aligning large language models (LLMs) with specific task instructions, thereby mitigating the discrepancy between the next-token prediction objective and users' actual goals. To reduce the labor and time cost to collect or annotate data by humans, researchers start to explore the use of LLMs to generate instruction-aligned synthetic data. Recent works focus on generating diverse instructions and applying LLM to increase instruction complexity, often neglecting downstream use cases. It remains unclear how to tailor high-quality data to elicit better instruction-following abilities in different target instruction distributions and LLMs. To this end, we introduce CodecLM, a general framework for adaptively generating high-quality synthetic data for LLM alignment with different downstream instruction distributions and LLMs. Drawing on the Encode-Decode principles, we use LLMs as codecs to guide the data generation process. We first encode seed instructions into metadata, which are concise keywords generated on-the-fly to capture the target instruction distribution, and then decode metadata to create tailored instructions. We also introduce Self-Rubrics and Contrastive Filtering during decoding to tailor data-efficient samples. Extensive experiments on four open-domain instruction following benchmarks validate the effectiveness of CodecLM over the current state-of-the-arts.
Read more4/10/2024

0
X-Instruction: Aligning Language Model in Low-resource Languages with Self-curated Cross-lingual Instructions
Chong Li, Wen Yang, Jiajun Zhang, Jinliang Lu, Shaonan Wang, Chengqing Zong
Large language models respond well in high-resource languages like English but struggle in low-resource languages. It may arise from the lack of high-quality instruction following data in these languages. Directly translating English samples into these languages can be a solution but unreliable, leading to responses with translation errors and lacking language-specific or cultural knowledge. To address this issue, we propose a novel method to construct cross-lingual instruction following samples with instruction in English and response in low-resource languages. Specifically, the language model first learns to generate appropriate English instructions according to the natural web texts in other languages as responses. The candidate cross-lingual instruction tuning samples are further refined and diversified. We have employed this method to build a large-scale cross-lingual instruction tuning dataset on 10 languages, namely X-Instruction. The instruction data built using our method incorporate more language-specific knowledge compared with the naive translation method. Experimental results have shown that the response quality of the model tuned on X-Instruction greatly exceeds the model distilled from a powerful teacher model, reaching or even surpassing the ones of ChatGPT. In addition, we find that models tuned on cross-lingual instruction following samples can follow the instruction in the output language without further tuning.
Read more5/31/2024

0
Contrastive Instruction Tuning
Tianyi Lorena Yan, Fei Wang, James Y. Huang, Wenxuan Zhou, Fan Yin, Aram Galstyan, Wenpeng Yin, Muhao Chen
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
Read more6/7/2024