Contrastive Instruction Tuning
2402.11138
0
0

Abstract
Instruction tuning has been used as a promising approach to improve the performance of large language models (LLMs) on unseen tasks. However, current LLMs exhibit limited robustness to unseen instructions, generating inconsistent outputs when the same instruction is phrased with slightly varied forms or language styles. This behavior indicates LLMs' lack of robustness to textual variations and generalizability to unseen instructions, potentially leading to trustworthiness issues. Accordingly, we propose Contrastive Instruction Tuning, which maximizes the similarity between the hidden representations of semantically equivalent instruction-instance pairs while minimizing the similarity between semantically different ones. To facilitate this approach, we augment the existing FLAN collection by paraphrasing task instructions. Experiments on the PromptBench benchmark show that CoIN consistently improves LLMs' robustness to unseen instructions with variations across character, word, sentence, and semantic levels by an average of +2.5% in accuracy. Code is available at https://github.com/luka-group/CoIN.
Create account to get full access
Overview
- This paper explores a new training approach called "Contrastive Instruction Tuning" that aims to improve the performance of language models on instruction-following tasks.
- The key idea is to train the model to not just generate the correct output, but to also distinguish it from incorrect outputs.
- This is done by modifying the training loss function to include a contrastive term that encourages the model to produce outputs that are closer to the target and further from incorrect alternatives.
Plain English Explanation
When we train language models to follow instructions, the goal is for the model to generate the correct response to a given instruction. Contrastive Instruction Tuning takes this a step further by also training the model to differentiate the correct response from incorrect ones.
Imagine you're trying to teach a child how to bake a cake. You don't just want them to be able to produce the finished cake - you also want them to recognize when something has gone wrong, like adding too much salt or leaving out a key ingredient. By training the model to not only generate the right output, but to also identify what the wrong outputs look like, it can learn to be more discerning and accurate in its instruction-following abilities.
The related work has shown that standard language modeling approaches can struggle with complex, open-ended instructions. Contrastive Instruction Tuning aims to address this by making the model more sensitive to the nuances of instruction-following.
Technical Explanation
The paper proposes a new training approach called "Contrastive Instruction Tuning" that builds on previous work in instruction tuning and contrastive language modeling.
The key innovation is to modify the training loss function to include a contrastive term. In addition to the standard term that encourages the model to generate the correct output, there is an additional term that pushes the model to produce outputs that are closer to the target and further from a set of incorrect alternatives.
This contrastive loss is applied during a fine-tuning stage, where the pre-trained language model is further trained on instruction-following tasks. The experiments show that this approach leads to significant performance improvements on a variety of instruction-following benchmarks, compared to standard fine-tuning methods.
Critical Analysis
The paper does a good job of highlighting some of the limitations and potential issues with Contrastive Instruction Tuning. For example, the authors note that the approach relies on having access to a set of high-quality incorrect alternatives during training, which may not always be easy to obtain.
Additionally, the paper acknowledges that the contrastive loss can be computationally expensive, as it requires evaluating the model's outputs against multiple alternatives. This could pose challenges for scaling the approach to very large language models or high-throughput applications.
While the results are promising, it would be valuable to see further analysis on the types of instructions and tasks where Contrastive Instruction Tuning provides the greatest benefits. The paper also does not delve into potential biases or fairness issues that could arise from this approach.
Overall, the Contrastive Instruction Tuning method represents an interesting and potentially impactful advance in improving language models' instruction-following capabilities. However, as with any new technique, more research and real-world deployment will be needed to fully understand its strengths, limitations, and broader implications.
Conclusion
This paper introduces a novel training approach called "Contrastive Instruction Tuning" that aims to improve language models' performance on instruction-following tasks. By modifying the training loss function to include a contrastive term, the model is encouraged to not just generate the correct output, but to also distinguish it from incorrect alternatives.
The results show significant performance gains on a range of instruction-following benchmarks, suggesting that this approach could lead to more robust and capable language models for real-world applications. While the method has some limitations, it represents an important step forward in advancing the state of the art in instruction-following AI systems.
As language models continue to play an increasingly central role in our lives, developing techniques like Contrastive Instruction Tuning will be crucial for ensuring these systems can reliably and accurately follow complex instructions - a critical capability for a wide range of applications, from personal assistants to industrial automation.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
✅
Instruction Tuning With Loss Over Instructions
Zhengyan Shi, Adam X. Yang, Bin Wu, Laurence Aitchison, Emine Yilmaz, Aldo Lipani
0
0
Instruction tuning plays a crucial role in shaping the outputs of language models (LMs) to desired styles. In this work, we propose a simple yet effective method, Instruction Modelling (IM), which trains LMs by applying a loss function to the instruction and prompt part rather than solely to the output part. Through experiments across 21 diverse benchmarks, we show that, in many scenarios, IM can effectively improve the LM performance on both NLP tasks (e.g., MMLU, TruthfulQA, and HumanEval) and open-ended generation benchmarks (e.g., MT-Bench and AlpacaEval). Remarkably, in the most advantageous case, IM boosts model performance on AlpacaEval 1.0 by over 100%. We identify two key factors influencing the effectiveness of IM: (1) The ratio between instruction length and output length in the training data; and (2) The number of training examples. We observe that IM is especially beneficial when trained on datasets with lengthy instructions paired with brief outputs, or under the Superficial Alignment Hypothesis (SAH) where a small amount of training examples are used for instruction tuning. Further analysis substantiates our hypothesis that the improvement can be attributed to reduced overfitting to instruction tuning datasets. Our work provides practical guidance for instruction tuning LMs, especially in low-resource scenarios.
5/24/2024
💬
From Language Modeling to Instruction Following: Understanding the Behavior Shift in LLMs after Instruction Tuning
Xuansheng Wu, Wenlin Yao, Jianshu Chen, Xiaoman Pan, Xiaoyang Wang, Ninghao Liu, Dong Yu
0
0
Large Language Models (LLMs) have achieved remarkable success, where instruction tuning is the critical step in aligning LLMs with user intentions. In this work, we investigate how the instruction tuning adjusts pre-trained models with a focus on intrinsic changes. Specifically, we first develop several local and global explanation methods, including a gradient-based method for input-output attribution, and techniques for interpreting patterns and concepts in self-attention and feed-forward layers. The impact of instruction tuning is then studied by comparing the explanations derived from the pre-trained and instruction-tuned models. This approach provides an internal perspective of the model shifts on a human-comprehensible level. Our findings reveal three significant impacts of instruction tuning: 1) It empowers LLMs to recognize the instruction parts of user prompts, and promotes the response generation constantly conditioned on the instructions. 2) It encourages the self-attention heads to capture more word-word relationships about instruction verbs. 3) It encourages the feed-forward networks to rotate their pre-trained knowledge toward user-oriented tasks. These insights contribute to a more comprehensive understanding of instruction tuning and lay the groundwork for future work that aims at explaining and optimizing LLMs for various applications. Our code and data are publicly available at https://github.com/JacksonWuxs/Interpret_Instruction_Tuning_LLMs.
4/5/2024

Towards Robust Instruction Tuning on Multimodal Large Language Models
Wei Han, Hui Chen, Soujanya Poria
0
0
Fine-tuning large language models (LLMs) on multi-task instruction-following data has been proven to be a powerful learning paradigm for improving their zero-shot capabilities on new tasks. Recent works about high-quality instruction-following data generation and selection require amounts of human labor to conceive model-understandable instructions for the given tasks and carefully filter the LLM-generated data. In this work, we introduce an automatic instruction augmentation method named INSTRAUG in multimodal tasks. It starts from a handful of basic and straightforward meta instructions but can expand an instruction-following dataset by 30 times. Results on two popular multimodal instructionfollowing benchmarks MULTIINSTRUCT and InstructBLIP show that INSTRAUG can significantly improve the alignment of multimodal large language models (MLLMs) across 12 multimodal tasks, which is even equivalent to the benefits of scaling up training data multiple times.
6/17/2024
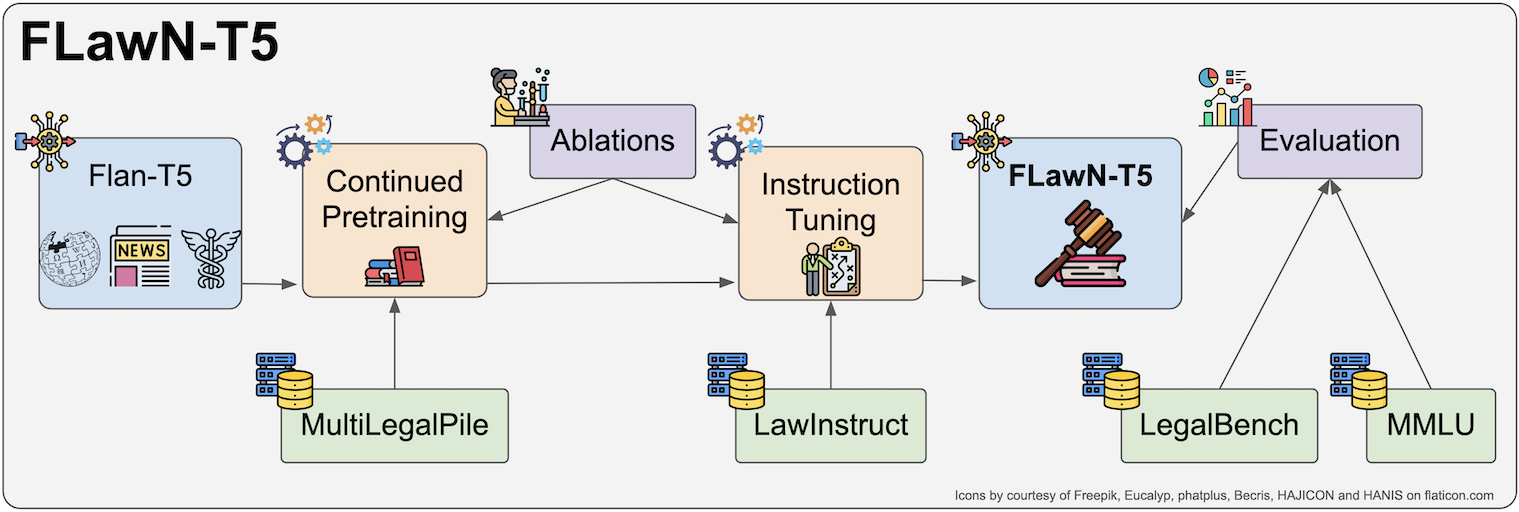
FLawN-T5: An Empirical Examination of Effective Instruction-Tuning Data Mixtures for Legal Reasoning
Joel Niklaus, Lucia Zheng, Arya D. McCarthy, Christopher Hahn, Brian M. Rosen, Peter Henderson, Daniel E. Ho, Garrett Honke, Percy Liang, Christopher Manning
0
0
Instruction tuning is an important step in making language models useful for direct user interaction. However, many legal tasks remain out of reach for most open LLMs and there do not yet exist any large scale instruction datasets for the domain. This critically limits research in this application area. In this work, we curate LawInstruct, a large legal instruction dataset, covering 17 jurisdictions, 24 languages and a total of 12M examples. We present evidence that domain-specific pretraining and instruction tuning improve performance on LegalBench, including improving Flan-T5 XL by 8 points or 16% over the baseline. However, the effect does not generalize across all tasks, training regimes, model sizes, and other factors. LawInstruct is a resource for accelerating the development of models with stronger information processing and decision making capabilities in the legal domain.
4/3/2024