Between Copyright and Computer Science: The Law and Ethics of Generative AI

0
🤖
Sign in to get full access
Overview
- Copyright and computer science have a complex, intertwined relationship
- New technologies like digitization, sharing, and AI challenge traditional copyright frameworks
- There is ongoing tension between copyright law and advancements in computer science
- The solution requires compromises from both the copyright industry and the computer science world
Plain English Explanation
Copyright laws were created to protect the rights of creators, but they have struggled to keep up with rapidly evolving technologies. The rise of digitization, sharing platforms, and search engines has made it easier than ever to access and distribute copyrighted content. This has created challenges for industries that rely on copyright, such as the entertainment and publishing sectors.
The latest battleground is in artificial intelligence (AI) research, particularly the development of large language models that are trained on vast amounts of copyrighted text. Some companies have been overly aggressive in their use of copyrighted material, which has raised legal concerns.
The solution requires both the copyright industry and the computer science world to compromise. The copyright industry needs to accept that not all use of copyrighted material needs to be compensated, especially for non-expressive uses like training AI models. At the same time, the computer science community needs to be more disciplined in how it accesses and uses copyrighted material, and in some cases, may need to pay for the use of that material.
By finding a balance, the article argues that copyright and computer science can coexist and even complement each other, supporting innovation and creativity in the digital age.
Technical Explanation
The article explores the ongoing tension between copyright law and advancements in computer science, particularly the challenges posed by new technologies such as digitization, sharing platforms, search engines, and artificial intelligence (AI) research.
The paper argues that fair use law does not automatically justify all uses of copyrighted material, even if the purpose is considered fair use. However, the scientific need for large datasets to advance AI research means that access to extensive book corpora and the Open Internet is crucial.
The copyright industry claims that almost all uses of copyrighted material must be compensated, even for non-expressive uses like training AI models. The article proposes a solution that requires both the copyright industry and the computer science world to make compromises.
The computer science community must be more disciplined in how it accesses and uses copyrighted material, and in some cases, may need to pay for the use of that material. Conversely, the copyright industry must abandon the belief that all uses must be compensated or restricted to uses sanctioned by the industry.
The article also addresses a problem that has arisen from this clash and has been undertheorized.
Critical Analysis
The article raises important and complex issues at the intersection of copyright law and computer science. It acknowledges that both sides need to compromise to find a sustainable solution.
One potential limitation of the research is that it may not fully capture the nuances and evolving nature of this topic. As technology and legal frameworks continue to change, new challenges and considerations may arise that are not addressed in the paper.
Additionally, the article focuses primarily on the tension between the copyright industry and the computer science community, but there may be other stakeholders, such as consumers, policymakers, and the general public, whose interests and perspectives should also be considered.
The article could also be strengthened by providing more specific examples or case studies to illustrate the key points and the potential impacts of the proposed solutions.
Overall, the article raises important questions and proposes a balanced approach, but there may be opportunities to further explore the complexities of this issue and consider additional perspectives.
Conclusion
The article highlights the ongoing clash between copyright law and advancements in computer science, driven by the rise of new technologies like digitization, sharing platforms, and AI research. It argues that a compromise is necessary, where both the copyright industry and the computer science world make concessions to find a sustainable solution.
By striking a balance, the article suggests that copyright and computer science can coexist and even complement each other, supporting innovation and creativity in the digital age. This is an important and timely issue that will continue to evolve, and the article provides a valuable framework for understanding and addressing the complex challenges at the intersection of these domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🤖
0
Between Copyright and Computer Science: The Law and Ethics of Generative AI
Deven R. Desai, Mark Riedl
Copyright and computer science continue to intersect and clash, but they can coexist. The advent of new technologies such as digitization of visual and aural creations, sharing technologies, search engines, social media offerings, and more challenge copyright-based industries and reopen questions about the reach of copyright law. Breakthroughs in artificial intelligence research, especially Large Language Models that leverage copyrighted material as part of training models, are the latest examples of the ongoing tension between copyright and computer science. The exuberance, rush-to-market, and edge problem cases created by a few misguided companies now raises challenges to core legal doctrines and may shift Open Internet practices for the worse. That result does not have to be, and should not be, the outcome. This Article shows that, contrary to some scholars' views, fair use law does not bless all ways that someone can gain access to copyrighted material even when the purpose is fair use. Nonetheless, the scientific need for more data to advance AI research means access to large book corpora and the Open Internet is vital for the future of that research. The copyright industry claims, however, that almost all uses of copyrighted material must be compensated, even for non-expressive uses. The Article's solution accepts that both sides need to change. It is one that forces the computer science world to discipline its behaviors and, in some cases, pay for copyrighted material. It also requires the copyright industry to abandon its belief that all uses must be compensated or restricted to uses sanctioned by the copyright industry. As part of this re-balancing, the Article addresses a problem that has grown out of this clash and under theorized.
Read more9/9/2024
🤖
0
Uncertain Boundaries: Multidisciplinary Approaches to Copyright Issues in Generative AI
Jocelyn Dzuong, Zichong Wang, Wenbin Zhang
In the rapidly evolving landscape of generative artificial intelligence (AI), the increasingly pertinent issue of copyright infringement arises as AI advances to generate content from scraped copyrighted data, prompting questions about ownership and protection that impact professionals across various careers. With this in mind, this survey provides an extensive examination of copyright infringement as it pertains to generative AI, aiming to stay abreast of the latest developments and open problems. Specifically, it will first outline methods of detecting copyright infringement in mediums such as text, image, and video. Next, it will delve an exploration of existing techniques aimed at safeguarding copyrighted works from generative models. Furthermore, this survey will discuss resources and tools for users to evaluate copyright violations. Finally, insights into ongoing regulations and proposals for AI will be explored and compared. Through combining these disciplines, the implications of AI-driven content and copyright are thoroughly illustrated and brought into question.
Read more4/15/2024
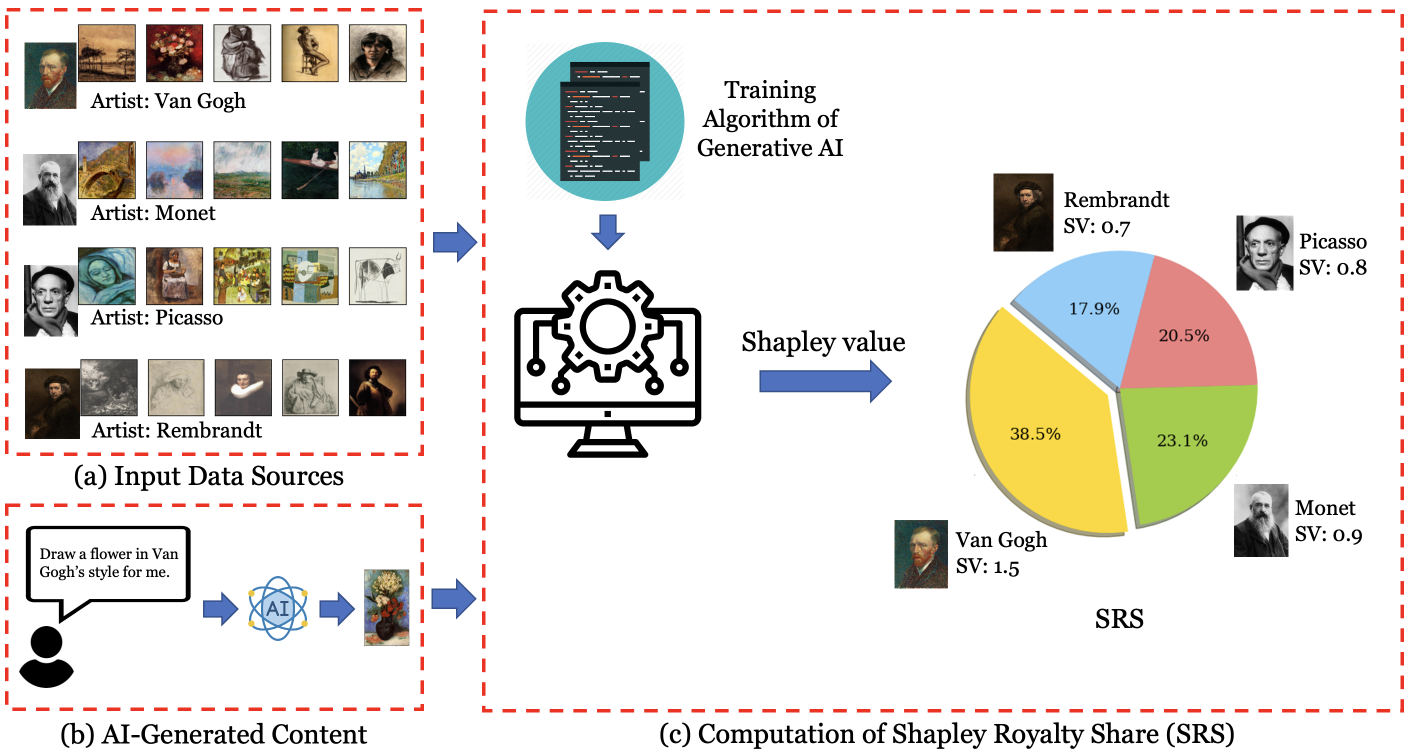
0
An Economic Solution to Copyright Challenges of Generative AI
Jiachen T. Wang, Zhun Deng, Hiroaki Chiba-Okabe, Boaz Barak, Weijie J. Su
Generative artificial intelligence (AI) systems are trained on large data corpora to generate new pieces of text, images, videos, and other media. There is growing concern that such systems may infringe on the copyright interests of training data contributors. To address the copyright challenges of generative AI, we propose a framework that compensates copyright owners proportionally to their contributions to the creation of AI-generated content. The metric for contributions is quantitatively determined by leveraging the probabilistic nature of modern generative AI models and using techniques from cooperative game theory in economics. This framework enables a platform where AI developers benefit from access to high-quality training data, thus improving model performance. Meanwhile, copyright owners receive fair compensation, driving the continued provision of relevant data for generative model training. Experiments demonstrate that our framework successfully identifies the most relevant data sources used in artwork generation, ensuring a fair and interpretable distribution of revenues among copyright owners.
Read more9/10/2024
✅
0
Copyright Protection in Generative AI: A Technical Perspective
Jie Ren, Han Xu, Pengfei He, Yingqian Cui, Shenglai Zeng, Jiankun Zhang, Hongzhi Wen, Jiayuan Ding, Pei Huang, Lingjuan Lyu, Hui Liu, Yi Chang, Jiliang Tang
Generative AI has witnessed rapid advancement in recent years, expanding their capabilities to create synthesized content such as text, images, audio, and code. The high fidelity and authenticity of contents generated by these Deep Generative Models (DGMs) have sparked significant copyright concerns. There have been various legal debates on how to effectively safeguard copyrights in DGMs. This work delves into this issue by providing a comprehensive overview of copyright protection from a technical perspective. We examine from two distinct viewpoints: the copyrights pertaining to the source data held by the data owners and those of the generative models maintained by the model builders. For data copyright, we delve into methods data owners can protect their content and DGMs can be utilized without infringing upon these rights. For model copyright, our discussion extends to strategies for preventing model theft and identifying outputs generated by specific models. Finally, we highlight the limitations of existing techniques and identify areas that remain unexplored. Furthermore, we discuss prospective directions for the future of copyright protection, underscoring its importance for the sustainable and ethical development of Generative AI.
Read more7/25/2024