Beware of diffusion models for synthesizing medical images -- A comparison with GANs in terms of memorizing brain MRI and chest x-ray images

0
🐍
Sign in to get full access
Overview
- The paper examines the use of diffusion models for generating synthetic medical images, such as brain MRI and chest X-rays.
- It compares diffusion models to StyleGAN, a popular generative adversarial network (GAN), in terms of their ability to reproduce training images.
- The researchers train and evaluate these models on several medical imaging datasets, including BRATS20, BRATS21, and a chest X-ray pneumonia dataset.
- The key finding is that diffusion models are more likely to memorize the training images, especially for small datasets and when using 2D slices from 3D volumes, compared to StyleGAN.
Plain English Explanation
Diffusion models are a type of machine learning algorithm that can be used to generate high-quality synthetic images. These models work by gradually adding noise to an image and then learning to reverse the process, allowing them to create new images that look similar to the ones they were trained on.
In this paper, the researchers compared diffusion models to another type of generative model called a GAN, specifically the StyleGAN model. They trained both types of models on several medical imaging datasets, including brain MRI scans and chest X-rays, to see how well they could generate new, realistic-looking images.
The key finding was that diffusion models were more likely to simply reproduce the original training images, rather than generating new, unique images. This was especially true when the dataset was smaller or when the researchers used 2D slices of 3D medical images, like individual X-ray slices from a 3D CT scan.
This is an important finding because it suggests that researchers need to be careful when using diffusion models for medical imaging tasks, where the goal may be to generate new, diverse images rather than just reproduce the training data. The MediSyn and Chest Diffusion papers explore ways to improve diffusion models for medical imaging, while the 3D MRI Synthesis paper looks at techniques for generating 3D medical images from 2D slices.
Technical Explanation
The researchers trained two types of generative models, a diffusion model and a StyleGAN model, on several medical imaging datasets, including BRATS20, BRATS21, and a chest X-ray pneumonia dataset.
Diffusion models work by gradually adding noise to an image, then learning to reverse the process to generate new images. StyleGAN, on the other hand, is a type of GAN that has shown impressive results in generating high-quality synthetic images.
The researchers evaluated the models using standard metrics like Fréchet Inception Distance (FID) and Inception Score (IS), which measure how similar the generated images are to the training data. However, they noted that these metrics may not be suitable for determining whether the models are simply memorizing the training images.
To address this, the researchers measured the correlation between the synthetic images and all the training images, to see how much the models were reproducing the original data. Their results showed that diffusion models were more likely to memorize the training images, especially for smaller datasets and when using 2D slices from 3D volumes, compared to StyleGAN.
Critical Analysis
The paper raises some important concerns about the use of diffusion models for medical imaging tasks, particularly when the goal is to generate new, diverse images rather than just reproduce the training data.
While diffusion models have shown impressive results on various evaluation metrics, the researchers demonstrate that these models may be more prone to memorizing the training images, especially for smaller datasets and when working with 2D slices of 3D volumes. This is a significant limitation, as it could lead to the generation of synthetic images that are too similar to the original data, which may not be useful for certain applications.
The researchers acknowledge that commonly used metrics like FID and IS may not be sufficient for evaluating the memorization behavior of these models. This highlights the need for more robust evaluation methods that can better assess the diversity and novelty of the generated images, particularly in the context of medical imaging applications.
The paper also raises the question of whether the observed memorization behavior is unique to diffusion models or if it also applies to other generative models, such as GANs. The comparison to StyleGAN provides some insights, but further research is needed to understand the broader implications for generative modeling in medical imaging.
Overall, this paper serves as an important reminder for researchers to be cautious when using diffusion models (and potentially other generative models) for medical imaging tasks, especially when the goal is to generate synthetic data that can be safely shared or used for downstream applications.
Conclusion
This paper highlights the potential limitations of using diffusion models for generating synthetic medical images, particularly when the goal is to create diverse and novel images rather than just reproduce the training data.
The researchers' findings show that diffusion models are more likely to memorize the training images, especially for smaller datasets and when working with 2D slices of 3D volumes, compared to a GAN-based model like StyleGAN. This is a significant concern, as it could limit the usefulness of the generated images for certain medical imaging applications.
The paper also emphasizes the need for more robust evaluation methods that can better assess the diversity and novelty of the generated images, beyond the commonly used metrics like FID and IS. This is an important consideration for researchers working on generative modeling for medical imaging tasks.
Overall, this research serves as a cautionary tale for the use of diffusion models in medical imaging, and underscores the importance of carefully evaluating the capabilities and limitations of these models before deploying them in real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🐍
0
Beware of diffusion models for synthesizing medical images -- A comparison with GANs in terms of memorizing brain MRI and chest x-ray images
Muhammad Usman Akbar, Wuhao Wang, Anders Eklund
Diffusion models were initially developed for text-to-image generation and are now being utilized to generate high quality synthetic images. Preceded by GANs, diffusion models have shown impressive results using various evaluation metrics. However, commonly used metrics such as FID and IS are not suitable for determining whether diffusion models are simply reproducing the training images. Here we train StyleGAN and a diffusion model, using BRATS20, BRATS21 and a chest x-ray pneumonia dataset, to synthesize brain MRI and chest x-ray images, and measure the correlation between the synthetic images and all training images. Our results show that diffusion models are more likely to memorize the training images, compared to StyleGAN, especially for small datasets and when using 2D slices from 3D volumes. Researchers should be careful when using diffusion models (and to some extent GANs) for medical imaging, if the final goal is to share the synthetic images.
Read more7/9/2024
📈
0
Synthetic Brain Images: Bridging the Gap in Brain Mapping With Generative Adversarial Model
Drici Mourad, Kazeem Oluwakemi Oseni
Magnetic Resonance Imaging (MRI) is a vital modality for gaining precise anatomical information, and it plays a significant role in medical imaging for diagnosis and therapy planning. Image synthesis problems have seen a revolution in recent years due to the introduction of deep learning techniques, specifically Generative Adversarial Networks (GANs). This work investigates the use of Deep Convolutional Generative Adversarial Networks (DCGAN) for producing high-fidelity and realistic MRI image slices. The suggested approach uses a dataset with a variety of brain MRI scans to train a DCGAN architecture. While the discriminator network discerns between created and real slices, the generator network learns to synthesise realistic MRI image slices. The generator refines its capacity to generate slices that closely mimic real MRI data through an adversarial training approach. The outcomes demonstrate that the DCGAN promise for a range of uses in medical imaging research, since they show that it can effectively produce MRI image slices if we train them for a consequent number of epochs. This work adds to the expanding corpus of research on the application of deep learning techniques for medical image synthesis. The slices that are could be produced possess the capability to enhance datasets, provide data augmentation in the training of deep learning models, as well as a number of functions are made available to make MRI data cleaning easier, and a three ready to use and clean dataset on the major anatomical plans.
Read more4/16/2024
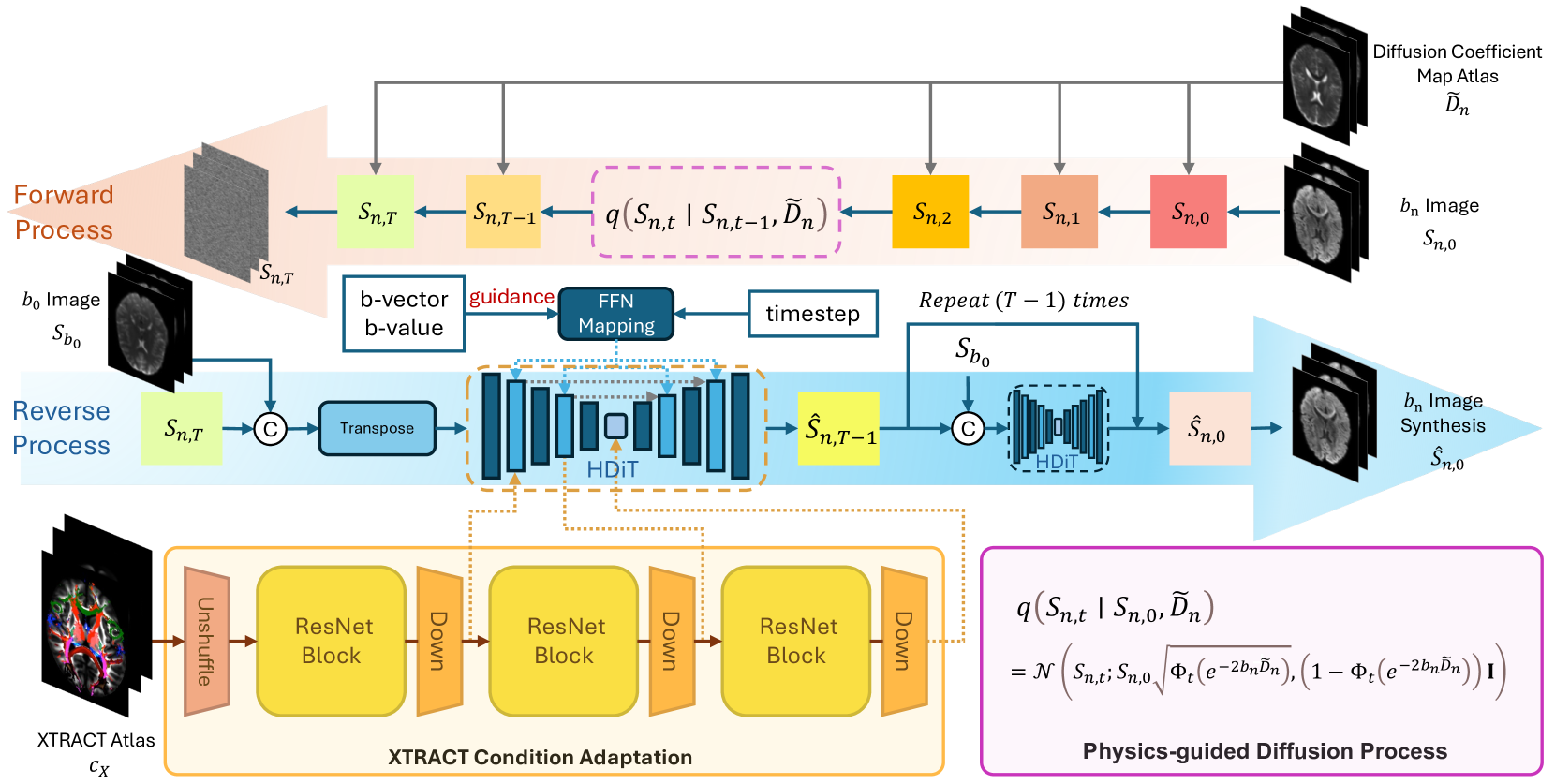
0
Phy-Diff: Physics-guided Hourglass Diffusion Model for Diffusion MRI Synthesis
Juanhua Zhang, Ruodan Yan, Alessandro Perelli, Xi Chen, Chao Li
Diffusion MRI (dMRI) is an important neuroimaging technique with high acquisition costs. Deep learning approaches have been used to enhance dMRI and predict diffusion biomarkers through undersampled dMRI. To generate more comprehensive raw dMRI, generative adversarial network based methods are proposed to include b-values and b-vectors as conditions, but they are limited by unstable training and less desirable diversity. The emerging diffusion model (DM) promises to improve generative performance. However, it remains challenging to include essential information in conditioning DM for more relevant generation, i.e., the physical principles of dMRI and white matter tract structures. In this study, we propose a physics-guided diffusion model to generate high-quality dMRI. Our model introduces the physical principles of dMRI in the noise evolution in the diffusion process and introduce a query-based conditional mapping within the difussion model. In addition, to enhance the anatomical fine detials of the generation, we introduce the XTRACT atlas as prior of white matter tracts by adopting an adapter technique. Our experiment results show that our method outperforms other state-of-the-art methods and has the potential to advance dMRI enhancement.
Read more7/11/2024

0
DiNO-Diffusion. Scaling Medical Diffusion via Self-Supervised Pre-Training
Guillermo Jimenez-Perez, Pedro Osorio, Josef Cersovsky, Javier Montalt-Tordera, Jens Hooge, Steffen Vogler, Sadegh Mohammadi
Diffusion models (DMs) have emerged as powerful foundation models for a variety of tasks, with a large focus in synthetic image generation. However, their requirement of large annotated datasets for training limits their applicability in medical imaging, where datasets are typically smaller and sparsely annotated. We introduce DiNO-Diffusion, a self-supervised method for training latent diffusion models (LDMs) that conditions the generation process on image embeddings extracted from DiNO. By eliminating the reliance on annotations, our training leverages over 868k unlabelled images from public chest X-Ray (CXR) datasets. Despite being self-supervised, DiNO-Diffusion shows comprehensive manifold coverage, with FID scores as low as 4.7, and emerging properties when evaluated in downstream tasks. It can be used to generate semantically-diverse synthetic datasets even from small data pools, demonstrating up to 20% AUC increase in classification performance when used for data augmentation. Images were generated with different sampling strategies over the DiNO embedding manifold and using real images as a starting point. Results suggest, DiNO-Diffusion could facilitate the creation of large datasets for flexible training of downstream AI models from limited amount of real data, while also holding potential for privacy preservation. Additionally, DiNO-Diffusion demonstrates zero-shot segmentation performance of up to 84.4% Dice score when evaluating lung lobe segmentation. This evidences good CXR image-anatomy alignment, akin to segmenting using textual descriptors on vanilla DMs. Finally, DiNO-Diffusion can be easily adapted to other medical imaging modalities or state-of-the-art diffusion models, opening the door for large-scale, multi-domain image generation pipelines for medical imaging.
Read more7/17/2024