Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
2404.01869
0
0

Abstract
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
Get summaries of the top AI research delivered straight to your inbox:
Overview
- This paper provides a comprehensive survey of methods for evaluating the reasoning behavior of large language models (LLMs) beyond just accuracy.
- The authors examine a range of techniques that go beyond simple question-answering tasks to assess higher-level cognitive skills like logical reasoning, common sense understanding, and grounded knowledge.
- The paper highlights the importance of these more sophisticated evaluation approaches as LLMs become increasingly powerful and are deployed in real-world applications.
Plain English Explanation
Large language models (LLMs) like GPT-3 have become extremely good at generating human-like text on a wide range of topics. However, simply measuring their accuracy on standard language tasks doesn't fully capture their true reasoning abilities.
Imagine you're trying to build an AI assistant to help with complex tasks like financial planning or medical diagnosis. You wouldn't just want the AI to regurgitate factual information - you'd want it to demonstrate genuine understanding and logical thinking. Can it break down a problem, consider all the relevant factors, and arrive at a well-reasoned conclusion?
This paper examines a variety of techniques researchers have developed to assess these higher-level cognitive skills in LLMs. For example, they may test the model's ability to follow multi-step reasoning chains, apply common sense knowledge, or ground its language in the physical world. The goal is to move beyond simplistic "question answering" and really understand the depth and flexibility of the model's reasoning capabilities.
As LLMs become more powerful and influential, it's crucial that we have robust evaluation methods to ensure they are behaving in safe, reliable, and ethical ways. This survey provides a valuable roadmap for the research community to further advance the state of the art in this important area.
Technical Explanation
The paper begins by highlighting the limitations of standard accuracy-based benchmarks for evaluating language models. While these provide a useful signal, they don't fully capture the models' true reasoning abilities.
The authors then review a range of alternative evaluation approaches that have emerged in recent years. These include:
- Reasoning Chains: Assessing the model's ability to follow multi-step logical reasoning processes, often involving commonsense knowledge.
- Grounded Language Understanding: Evaluating how well the model can ground its language in the physical world, rather than just relying on statistical patterns.
- Probing for Systematic Biases: Identifying systematic biases or inconsistencies in the model's outputs, which may reveal flaws in its reasoning.
- Natural Language Inference: Judging whether the model can correctly identify logical entailment and contradiction relationships between statements.
- Explanatory Reasoning: Assessing the model's ability to provide meaningful explanations for its outputs, rather than just generating plausible-sounding text.
The paper also discusses the challenges involved in developing robust, scalable evaluation protocols, as well as the potential ethical implications of deploying LLMs in high-stakes domains.
Critical Analysis
A key strength of this survey is its comprehensive overview of the rapidly evolving landscape of reasoning evaluation for large language models. The authors do an excellent job of highlighting the limitations of current accuracy-based benchmarks and the importance of more sophisticated assessment techniques.
That said, the paper also acknowledges several open challenges and areas for further research. For example, the authors note that many current evaluation tasks still rely on contrived or narrow scenarios, and may not fully capture the complexities of real-world reasoning. There is also a need for better alignment between evaluation tasks and the specific use cases where LLMs are being deployed.
Additionally, the paper briefly touches on the ethical implications of evaluating and deploying powerful language models, but this is an area that arguably deserves more in-depth discussion. As LLMs become increasingly influential, it will be crucial to develop evaluation frameworks that can reliably assess not just technical capabilities, but also the models' alignment with human values and potential for misuse.
Overall, this survey provides a valuable synthesis of current research and a strong foundation for future work in this crucial area of language model evaluation. Continued advancements in this field will be essential as LLMs become more ubiquitous and influential in our daily lives.
Conclusion
This comprehensive survey paper highlights the limitations of traditional accuracy-based benchmarks for evaluating the reasoning capabilities of large language models. It reviews a range of more sophisticated techniques that assess higher-level cognitive skills like logical reasoning, common sense understanding, and grounded language use.
As LLMs become increasingly powerful and are deployed in critical real-world applications, it is essential that we develop robust evaluation frameworks to ensure they are behaving in safe, reliable, and ethical ways. This paper provides a valuable roadmap for the research community to advance the state of the art in this important area.
Ultimately, the ability to deeply and accurately assess the reasoning behavior of LLMs will be a key factor in realizing their full potential to augment and empower human intelligence, while mitigating potential risks and misuses. This survey represents an important step forward in this endeavor.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Evaluating Consistency and Reasoning Capabilities of Large Language Models
Yash Saxena, Sarthak Chopra, Arunendra Mani Tripathi
0
0
Large Language Models (LLMs) are extensively used today across various sectors, including academia, research, business, and finance, for tasks such as text generation, summarization, and translation. Despite their widespread adoption, these models often produce incorrect and misleading information, exhibiting a tendency to hallucinate. This behavior can be attributed to several factors, with consistency and reasoning capabilities being significant contributors. LLMs frequently lack the ability to generate explanations and engage in coherent reasoning, leading to inaccurate responses. Moreover, they exhibit inconsistencies in their outputs. This paper aims to evaluate and compare the consistency and reasoning capabilities of both public and proprietary LLMs. The experiments utilize the Boolq dataset as the ground truth, comprising questions, answers, and corresponding explanations. Queries from the dataset are presented as prompts to the LLMs, and the generated responses are evaluated against the ground truth answers. Additionally, explanations are generated to assess the models' reasoning abilities. Consistency is evaluated by repeatedly presenting the same query to the models and observing for variations in their responses. For measuring reasoning capabilities, the generated explanations are compared to the ground truth explanations using metrics such as BERT, BLEU, and F-1 scores. The findings reveal that proprietary models generally outperform public models in terms of both consistency and reasoning capabilities. However, even when presented with basic general knowledge questions, none of the models achieved a score of 90% in both consistency and reasoning. This study underscores the direct correlation between consistency and reasoning abilities in LLMs and highlights the inherent reasoning challenges present in current language models.
4/26/2024
💬
Puzzle Solving using Reasoning of Large Language Models: A Survey
Panagiotis Giadikiaroglou, Maria Lymperaiou, Giorgos Filandrianos, Giorgos Stamou
0
0
Exploring the capabilities of Large Language Models (LLMs) in puzzle solving unveils critical insights into their potential and challenges in AI, marking a significant step towards understanding their applicability in complex reasoning tasks. This survey leverages a unique taxonomy -- dividing puzzles into rule-based and rule-less categories -- to critically assess LLMs through various methodologies, including prompting techniques, neuro-symbolic approaches, and fine-tuning. Through a critical review of relevant datasets and benchmarks, we assess LLMs' performance, identifying significant challenges in complex puzzle scenarios. Our findings highlight the disparity between LLM capabilities and human-like reasoning, particularly in those requiring advanced logical inference. The survey underscores the necessity for novel strategies and richer datasets to advance LLMs' puzzle-solving proficiency and contribute to AI's logical reasoning and creative problem-solving advancements.
4/23/2024
💬
Evaluating the Deductive Competence of Large Language Models
Spencer M. Seals, Valerie L. Shalin
0
0
The development of highly fluent large language models (LLMs) has prompted increased interest in assessing their reasoning and problem-solving capabilities. We investigate whether several LLMs can solve a classic type of deductive reasoning problem from the cognitive science literature. The tested LLMs have limited abilities to solve these problems in their conventional form. We performed follow up experiments to investigate if changes to the presentation format and content improve model performance. We do find performance differences between conditions; however, they do not improve overall performance. Moreover, we find that performance interacts with presentation format and content in unexpected ways that differ from human performance. Overall, our results suggest that LLMs have unique reasoning biases that are only partially predicted from human reasoning performance and the human-generated language corpora that informs them.
4/16/2024
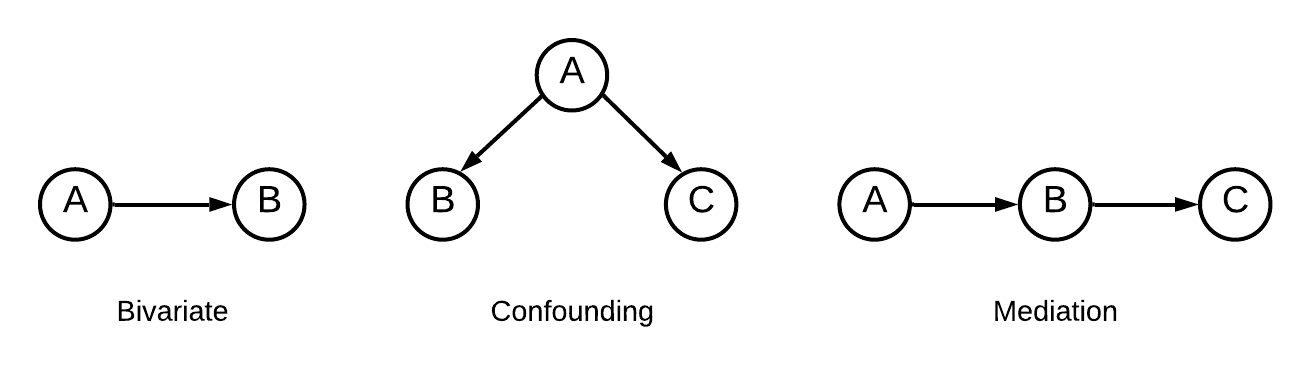
Evaluating Interventional Reasoning Capabilities of Large Language Models
Tejas Kasetty, Divyat Mahajan, Gintare Karolina Dziugaite, Alexandre Drouin, Dhanya Sridhar
0
0
Numerous decision-making tasks require estimating causal effects under interventions on different parts of a system. As practitioners consider using large language models (LLMs) to automate decisions, studying their causal reasoning capabilities becomes crucial. A recent line of work evaluates LLMs ability to retrieve commonsense causal facts, but these evaluations do not sufficiently assess how LLMs reason about interventions. Motivated by the role that interventions play in causal inference, in this paper, we conduct empirical analyses to evaluate whether LLMs can accurately update their knowledge of a data-generating process in response to an intervention. We create benchmarks that span diverse causal graphs (e.g., confounding, mediation) and variable types, and enable a study of intervention-based reasoning. These benchmarks allow us to isolate the ability of LLMs to accurately predict changes resulting from their ability to memorize facts or find other shortcuts. Our analysis on four LLMs highlights that while GPT- 4 models show promising accuracy at predicting the intervention effects, they remain sensitive to distracting factors in the prompts.
4/9/2024