Evaluating Consistency and Reasoning Capabilities of Large Language Models
2404.16478
0
0
💬
Abstract
Large Language Models (LLMs) are extensively used today across various sectors, including academia, research, business, and finance, for tasks such as text generation, summarization, and translation. Despite their widespread adoption, these models often produce incorrect and misleading information, exhibiting a tendency to hallucinate. This behavior can be attributed to several factors, with consistency and reasoning capabilities being significant contributors. LLMs frequently lack the ability to generate explanations and engage in coherent reasoning, leading to inaccurate responses. Moreover, they exhibit inconsistencies in their outputs. This paper aims to evaluate and compare the consistency and reasoning capabilities of both public and proprietary LLMs. The experiments utilize the Boolq dataset as the ground truth, comprising questions, answers, and corresponding explanations. Queries from the dataset are presented as prompts to the LLMs, and the generated responses are evaluated against the ground truth answers. Additionally, explanations are generated to assess the models' reasoning abilities. Consistency is evaluated by repeatedly presenting the same query to the models and observing for variations in their responses. For measuring reasoning capabilities, the generated explanations are compared to the ground truth explanations using metrics such as BERT, BLEU, and F-1 scores. The findings reveal that proprietary models generally outperform public models in terms of both consistency and reasoning capabilities. However, even when presented with basic general knowledge questions, none of the models achieved a score of 90% in both consistency and reasoning. This study underscores the direct correlation between consistency and reasoning abilities in LLMs and highlights the inherent reasoning challenges present in current language models.
Create account to get full access
Overview
- Large language models (LLMs) are widely used for various tasks, but they often produce incorrect and misleading information due to issues with consistency and reasoning capabilities.
- This paper aims to evaluate and compare the consistency and reasoning abilities of both public and proprietary LLMs using the Boolq dataset as a benchmark.
- The experiments involve presenting queries from the dataset as prompts to the LLMs and evaluating their responses against the ground truth answers and explanations.
Plain English Explanation
Large language models (LLMs) are a type of artificial intelligence that can understand and generate human-like text. These models are used in many industries, such as academia, research, business, and finance, for tasks like text generation, summarization, and translation.
Despite their widespread use, LLMs often produce incorrect or misleading information. This is because they sometimes "hallucinate," or make up information that isn't actually true. The main reasons for this are issues with consistency and reasoning capabilities.
LLMs often can't explain their own reasoning or maintain consistency in their responses. For example, if you ask the same question multiple times, you might get different answers.
This paper looks at how well public and proprietary (or privately-owned) LLMs perform when it comes to consistency and reasoning. The researchers used a dataset called Boolq, which has questions, answers, and explanations. They presented the questions to the LLMs and compared the models' responses to the ground truth answers and explanations.
The study found that proprietary models generally outperformed public models, but even the best models struggled to achieve high scores for both consistency and reasoning. This shows that current LLMs still have significant challenges when it comes to logical thinking and providing accurate, coherent information.
Technical Explanation
This paper evaluates and compares the consistency and reasoning capabilities of both public and proprietary large language models (LLMs). The researchers used the Boolq dataset, which contains questions, answers, and corresponding explanations, as the ground truth for their experiments.
The process involved presenting queries from the Boolq dataset as prompts to the LLMs and evaluating their responses against the ground truth answers and explanations. To assess consistency, the same queries were presented to the models multiple times, and variations in their responses were observed. For reasoning capabilities, the generated explanations were compared to the ground truth explanations using metrics like BERT, BLEU, and F-1 scores.
The findings reveal that proprietary LLMs generally outperform public models in terms of both consistency and reasoning abilities. However, even the best-performing models struggled to achieve a score of 90% or higher in both consistency and reasoning when presented with basic general knowledge questions.
These results underscore the direct correlation between consistency and reasoning capabilities in LLMs. The study highlights the inherent challenges in developing language models with robust logical reasoning abilities, which is crucial for their reliable and trustworthy deployment across various applications.
Critical Analysis
The paper provides a comprehensive evaluation of the consistency and reasoning capabilities of LLMs, which is an important area of research for improving the reliability and trustworthiness of these models. The use of the Boolq dataset as a benchmark is well-justified, as it offers a standardized set of questions, answers, and explanations to assess the models' performance.
One potential limitation of the study is the reliance on specific performance metrics, such as BERT, BLEU, and F-1 scores, for evaluating the reasoning capabilities of the LLMs. While these metrics provide quantitative insights, they may not fully capture the nuances and complexities of human-like reasoning. Incorporating additional qualitative assessments or manual evaluations by human experts could further strengthen the analysis.
Furthermore, the paper does not delve into the specific architectural differences or training approaches that may have contributed to the performance gap between public and proprietary models. Exploring these factors in more depth could yield valuable insights for the development of more consistent and logically coherent LLMs.
Despite these minor limitations, the paper's findings are significant and align with the broader research efforts aimed at enhancing the reasoning capabilities of large language models. The study serves as a valuable benchmark for the field and encourages further research to address the inherent challenges in developing LLMs with robust logical reasoning abilities.
Conclusion
This paper presents a comprehensive evaluation of the consistency and reasoning capabilities of both public and proprietary large language models (LLMs). The study utilizes the Boolq dataset as a benchmark and reveals that proprietary models generally outperform public models in these key areas.
However, even the best-performing LLMs struggle to achieve high scores in both consistency and reasoning when presented with basic general knowledge questions. This finding underscores the direct correlation between these two important aspects of language model performance and highlights the inherent challenges in developing LLMs with robust logical reasoning abilities.
The insights from this research are crucial for improving the reliability and trustworthiness of LLMs, which are increasingly being deployed across various industries and applications. Addressing the identified limitations in consistency and reasoning will be a crucial step towards building more advanced and dependable language models that can provide accurate and coherent information to users.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond Accuracy: Evaluating the Reasoning Behavior of Large Language Models -- A Survey
Philipp Mondorf, Barbara Plank
0
0
Large language models (LLMs) have recently shown impressive performance on tasks involving reasoning, leading to a lively debate on whether these models possess reasoning capabilities similar to humans. However, despite these successes, the depth of LLMs' reasoning abilities remains uncertain. This uncertainty partly stems from the predominant focus on task performance, measured through shallow accuracy metrics, rather than a thorough investigation of the models' reasoning behavior. This paper seeks to address this gap by providing a comprehensive review of studies that go beyond task accuracy, offering deeper insights into the models' reasoning processes. Furthermore, we survey prevalent methodologies to evaluate the reasoning behavior of LLMs, emphasizing current trends and efforts towards more nuanced reasoning analyses. Our review suggests that LLMs tend to rely on surface-level patterns and correlations in their training data, rather than on genuine reasoning abilities. Additionally, we identify the need for further research that delineates the key differences between human and LLM-based reasoning. Through this survey, we aim to shed light on the complex reasoning processes within LLMs.
4/3/2024
LogicBench: Towards Systematic Evaluation of Logical Reasoning Ability of Large Language Models
Mihir Parmar, Nisarg Patel, Neeraj Varshney, Mutsumi Nakamura, Man Luo, Santosh Mashetty, Arindam Mitra, Chitta Baral
0
0
Recently developed large language models (LLMs) have been shown to perform remarkably well on a wide range of language understanding tasks. But, can they really reason over the natural language? This question has been receiving significant research attention and many reasoning skills such as commonsense, numerical, and qualitative have been studied. However, the crucial skill pertaining to 'logical reasoning' has remained underexplored. Existing work investigating this reasoning ability of LLMs has focused only on a couple of inference rules (such as modus ponens and modus tollens) of propositional and first-order logic. Addressing the above limitation, we comprehensively evaluate the logical reasoning ability of LLMs on 25 different reasoning patterns spanning over propositional, first-order, and non-monotonic logics. To enable systematic evaluation, we introduce LogicBench, a natural language question-answering dataset focusing on the use of a single inference rule. We conduct detailed analysis with a range of LLMs such as GPT-4, ChatGPT, Gemini, Llama-2, and Mistral using chain-of-thought prompting. Experimental results show that existing LLMs do not fare well on LogicBench; especially, they struggle with instances involving complex reasoning and negations. Furthermore, they sometimes overlook contextual information necessary for reasoning to arrive at the correct conclusion. We believe that our work and findings facilitate future research for evaluating and enhancing the logical reasoning ability of LLMs. Data and code are available at https://github.com/Mihir3009/LogicBench.
6/7/2024
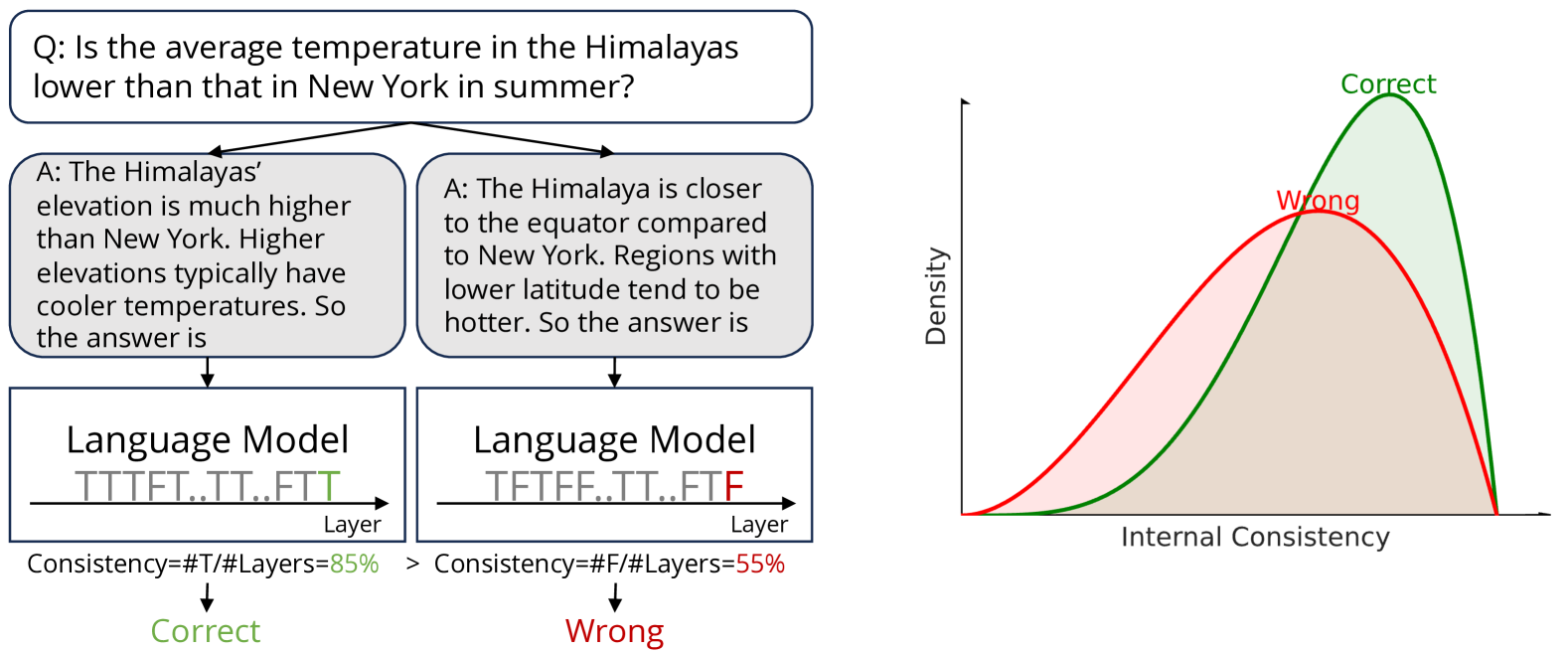
Calibrating Reasoning in Language Models with Internal Consistency
Zhihui Xie, Jizhou Guo, Tong Yu, Shuai Li
0
0
Large language models (LLMs) have demonstrated impressive capabilities in various reasoning tasks, aided by techniques like chain-of-thought (CoT) prompting that elicits verbalized reasoning. However, LLMs often generate text with obvious mistakes and contradictions, raising doubts about their ability to robustly process and utilize generated rationales. In this work, we investigate CoT reasoning in LLMs through the lens of internal representations, focusing on how these representations are influenced by generated rationales. Our preliminary analysis reveals that while generated rationales improve answer accuracy, inconsistencies emerge between the model's internal representations in middle layers and those in final layers, potentially undermining the reliability of their reasoning processes. To address this, we propose internal consistency as a measure of the model's confidence by examining the agreement of latent predictions decoded from intermediate layers. Extensive empirical studies across different models and datasets demonstrate that internal consistency effectively distinguishes between correct and incorrect reasoning paths. Motivated by this, we propose a new approach to calibrate CoT reasoning by up-weighting reasoning paths with high internal consistency, resulting in a significant boost in reasoning performance. Further analysis uncovers distinct patterns in attention and feed-forward modules across layers, providing insights into the emergence of internal inconsistency. In summary, our results demonstrate the potential of using internal representations for self-evaluation of LLMs.
5/30/2024
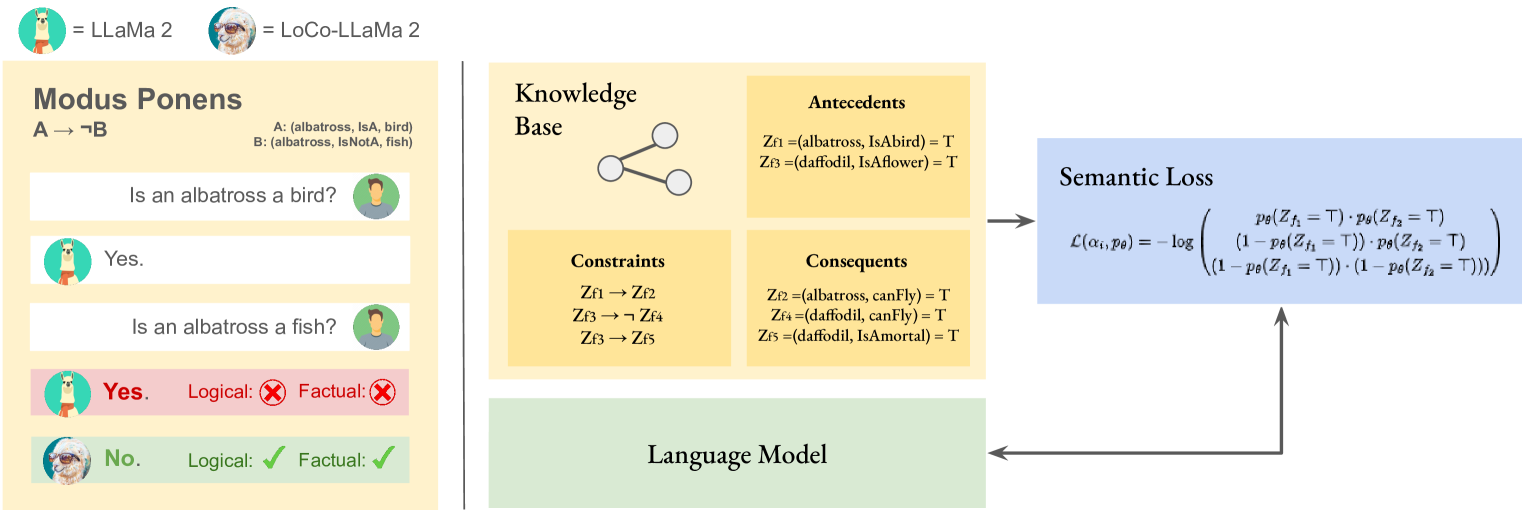
Towards Logically Consistent Language Models via Probabilistic Reasoning
Diego Calanzone, Stefano Teso, Antonio Vergari
0
0
Large language models (LLMs) are a promising venue for natural language understanding and generation tasks. However, current LLMs are far from reliable: they are prone to generate non-factual information and, more crucially, to contradict themselves when prompted to reason about beliefs of the world. These problems are currently addressed with large scale fine-tuning or by delegating consistent reasoning to external tools. In this work, we strive for a middle ground and introduce a training objective based on principled probabilistic reasoning that teaches a LLM to be consistent with external knowledge in the form of a set of facts and rules. Fine-tuning with our loss on a limited set of facts enables our LLMs to be more logically consistent than previous baselines and allows them to extrapolate to unseen but semantically similar factual knowledge more systematically.
4/22/2024