Beyond Accuracy: Investigating Error Types in GPT-4 Responses to USMLE Questions

0

Sign in to get full access
Overview
- This paper investigates the types of errors made by the GPT-4 language model when answering United States Medical Licensing Examination (USMLE) questions.
- The researchers developed a taxonomy of error types and used it to analyze GPT-4's performance on a dataset of USMLE questions.
- The goal was to go beyond just measuring accuracy and gain a deeper understanding of the model's weaknesses and strengths in a medical question-answering task.
Plain English Explanation
The researchers wanted to know more about the kinds of mistakes the GPT-4 language model makes when answering medical exam questions, not just whether it gets the answers right or wrong. They created a detailed system for categorizing different types of errors, like misunderstanding the question, giving an incomplete answer, or making factual mistakes. They then used this error taxonomy to analyze how GPT-4 performed on a set of questions from the USMLE, a major medical licensing exam. This allowed them to see where GPT-4 was struggling and identify areas for improvement, rather than just looking at its overall accuracy score.
Technical Explanation
The researchers developed a multi-label error taxonomy to annotate the types of errors made by GPT-4 when answering USMLE questions. This taxonomy included categories like "Misunderstanding the Question", "Incomplete Answer", "Factual Mistake", and several others. They then used this taxonomy to analyze a dataset of GPT-4 responses to USMLE questions, going beyond just measuring overall accuracy to get a more nuanced understanding of the model's performance.
The key insights from their analysis included:
- GPT-4 struggled most with questions requiring deeper medical knowledge, often making factual mistakes or providing incomplete answers
- The model tended to perform better on questions that could be answered more superficially, without requiring a full understanding of the medical concepts
- Certain error types, like "Irrelevant Response", were quite rare, suggesting GPT-4 was generally on-topic even when it made mistakes
Critical Analysis
The researchers acknowledge several limitations of their study. First, the dataset of USMLE questions used was relatively small, so the results may not generalize to the full scope of medical knowledge tested on the exam. Additionally, the error taxonomy they developed, while comprehensive, may not capture all the nuances of how language models can fail on complex, domain-specific tasks.
One area not addressed is how the performance of GPT-4 on this task compares to human performance. Knowing the relative strengths and weaknesses of the model compared to expert physicians would provide important context for interpreting the results.
Furthermore, the paper does not delve into potential reasons why GPT-4 exhibited the observed error patterns. Investigating the underlying capabilities and limitations of the model that lead to these errors could yield valuable insights for improving medical question-answering systems.
Conclusion
This study provides a detailed analysis of the types of errors made by the GPT-4 language model when answering USMLE questions, going beyond just measuring accuracy. The researchers' development of a multi-label error taxonomy and its application to GPT-4's performance offers a nuanced view of the model's capabilities and limitations in a challenging, domain-specific task.
The findings suggest that while GPT-4 can be a powerful tool for medical question-answering, there are still significant hurdles to overcome before such models can be reliably used in high-stakes medical settings. Continued research into the strengths and weaknesses of large language models like GPT-4 will be crucial for their safe and effective deployment in the medical field and other critical domains.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Accuracy: Investigating Error Types in GPT-4 Responses to USMLE Questions
Soumyadeep Roy, Aparup Khatua, Fatemeh Ghoochani, Uwe Hadler, Wolfgang Nejdl, Niloy Ganguly
GPT-4 demonstrates high accuracy in medical QA tasks, leading with an accuracy of 86.70%, followed by Med-PaLM 2 at 86.50%. However, around 14% of errors remain. Additionally, current works use GPT-4 to only predict the correct option without providing any explanation and thus do not provide any insight into the thinking process and reasoning used by GPT-4 or other LLMs. Therefore, we introduce a new domain-specific error taxonomy derived from collaboration with medical students. Our GPT-4 USMLE Error (G4UE) dataset comprises 4153 GPT-4 correct responses and 919 incorrect responses to the United States Medical Licensing Examination (USMLE) respectively. These responses are quite long (258 words on average), containing detailed explanations from GPT-4 justifying the selected option. We then launch a large-scale annotation study using the Potato annotation platform and recruit 44 medical experts through Prolific, a well-known crowdsourcing platform. We annotated 300 out of these 919 incorrect data points at a granular level for different classes and created a multi-label span to identify the reasons behind the error. In our annotated dataset, a substantial portion of GPT-4's incorrect responses is categorized as a Reasonable response by GPT-4, by annotators. This sheds light on the challenge of discerning explanations that may lead to incorrect options, even among trained medical professionals. We also provide medical concepts and medical semantic predications extracted using the SemRep tool for every data point. We believe that it will aid in evaluating the ability of LLMs to answer complex medical questions. We make the resources available at https://github.com/roysoumya/usmle-gpt4-error-taxonomy .
Read more4/23/2024
🎯
0
Hidden Flaws Behind Expert-Level Accuracy of GPT-4 Vision in Medicine
Qiao Jin, Fangyuan Chen, Yiliang Zhou, Ziyang Xu, Justin M. Cheung, Robert Chen, Ronald M. Summers, Justin F. Rousseau, Peiyun Ni, Marc J Landsman, Sally L. Baxter, Subhi J. Al'Aref, Yijia Li, Alex Chen, Josef A. Brejt, Michael F. Chiang, Yifan Peng, Zhiyong Lu
Recent studies indicate that Generative Pre-trained Transformer 4 with Vision (GPT-4V) outperforms human physicians in medical challenge tasks. However, these evaluations primarily focused on the accuracy of multi-choice questions alone. Our study extends the current scope by conducting a comprehensive analysis of GPT-4V's rationales of image comprehension, recall of medical knowledge, and step-by-step multimodal reasoning when solving New England Journal of Medicine (NEJM) Image Challenges - an imaging quiz designed to test the knowledge and diagnostic capabilities of medical professionals. Evaluation results confirmed that GPT-4V performs comparatively to human physicians regarding multi-choice accuracy (81.6% vs. 77.8%). GPT-4V also performs well in cases where physicians incorrectly answer, with over 78% accuracy. However, we discovered that GPT-4V frequently presents flawed rationales in cases where it makes the correct final choices (35.5%), most prominent in image comprehension (27.2%). Regardless of GPT-4V's high accuracy in multi-choice questions, our findings emphasize the necessity for further in-depth evaluations of its rationales before integrating such multimodal AI models into clinical workflows.
Read more9/4/2024
0
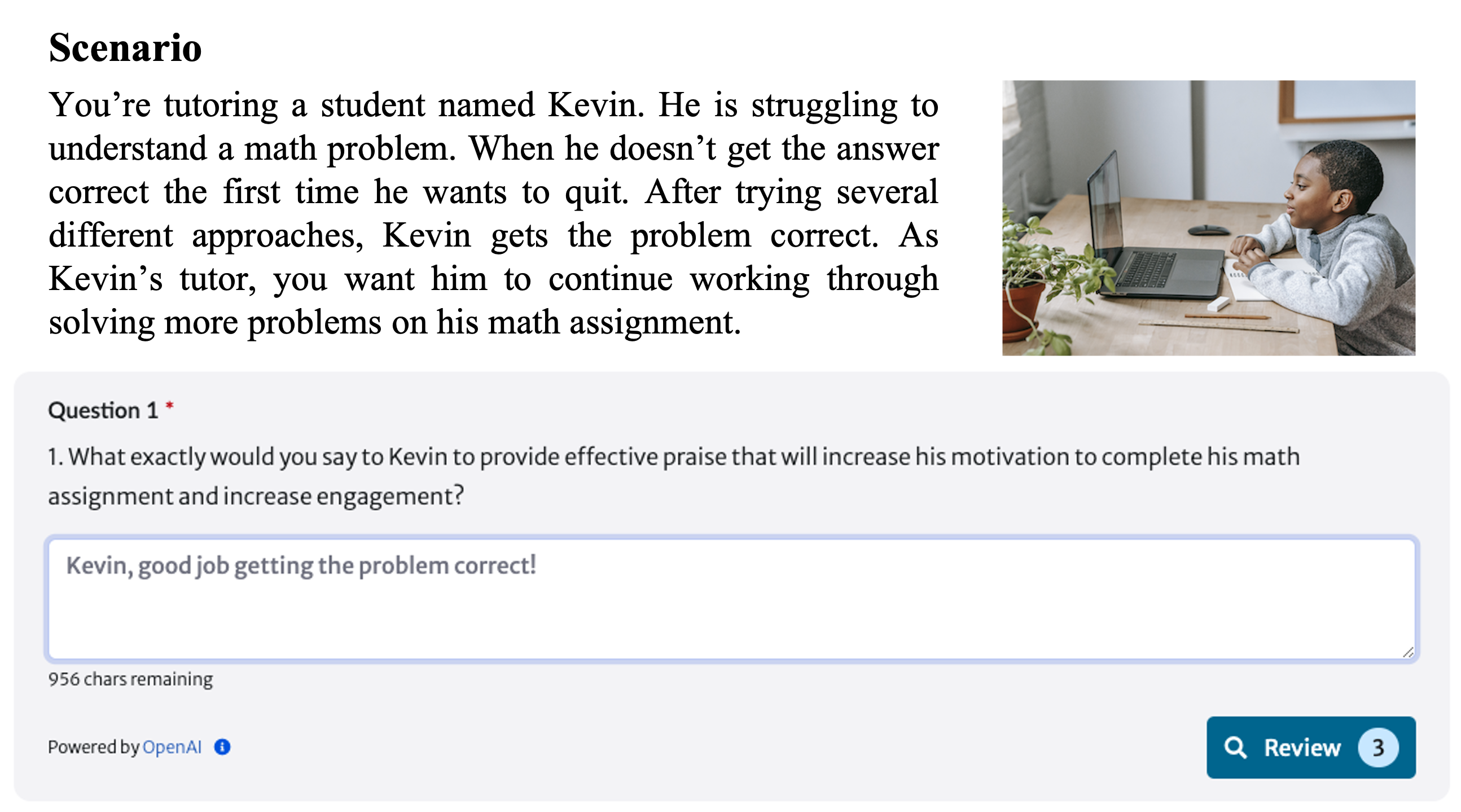
How Can I Get It Right? Using GPT to Rephrase Incorrect Trainee Responses
Jionghao Lin, Zifei Han, Danielle R. Thomas, Ashish Gurung, Shivang Gupta, Vincent Aleven, Kenneth R. Koedinger
One-on-one tutoring is widely acknowledged as an effective instructional method, conditioned on qualified tutors. However, the high demand for qualified tutors remains a challenge, often necessitating the training of novice tutors (i.e., trainees) to ensure effective tutoring. Research suggests that providing timely explanatory feedback can facilitate the training process for trainees. However, it presents challenges due to the time-consuming nature of assessing trainee performance by human experts. Inspired by the recent advancements of large language models (LLMs), our study employed the GPT-4 model to build an explanatory feedback system. This system identifies trainees' responses in binary form (i.e., correct/incorrect) and automatically provides template-based feedback with responses appropriately rephrased by the GPT-4 model. We conducted our study on 410 responses from trainees across three training lessons: Giving Effective Praise, Reacting to Errors, and Determining What Students Know. Our findings indicate that: 1) using a few-shot approach, the GPT-4 model effectively identifies correct/incorrect trainees' responses from three training lessons with an average F1 score of 0.84 and an AUC score of 0.85; and 2) using the few-shot approach, the GPT-4 model adeptly rephrases incorrect trainees' responses into desired responses, achieving performance comparable to that of human experts.
Read more5/3/2024
0
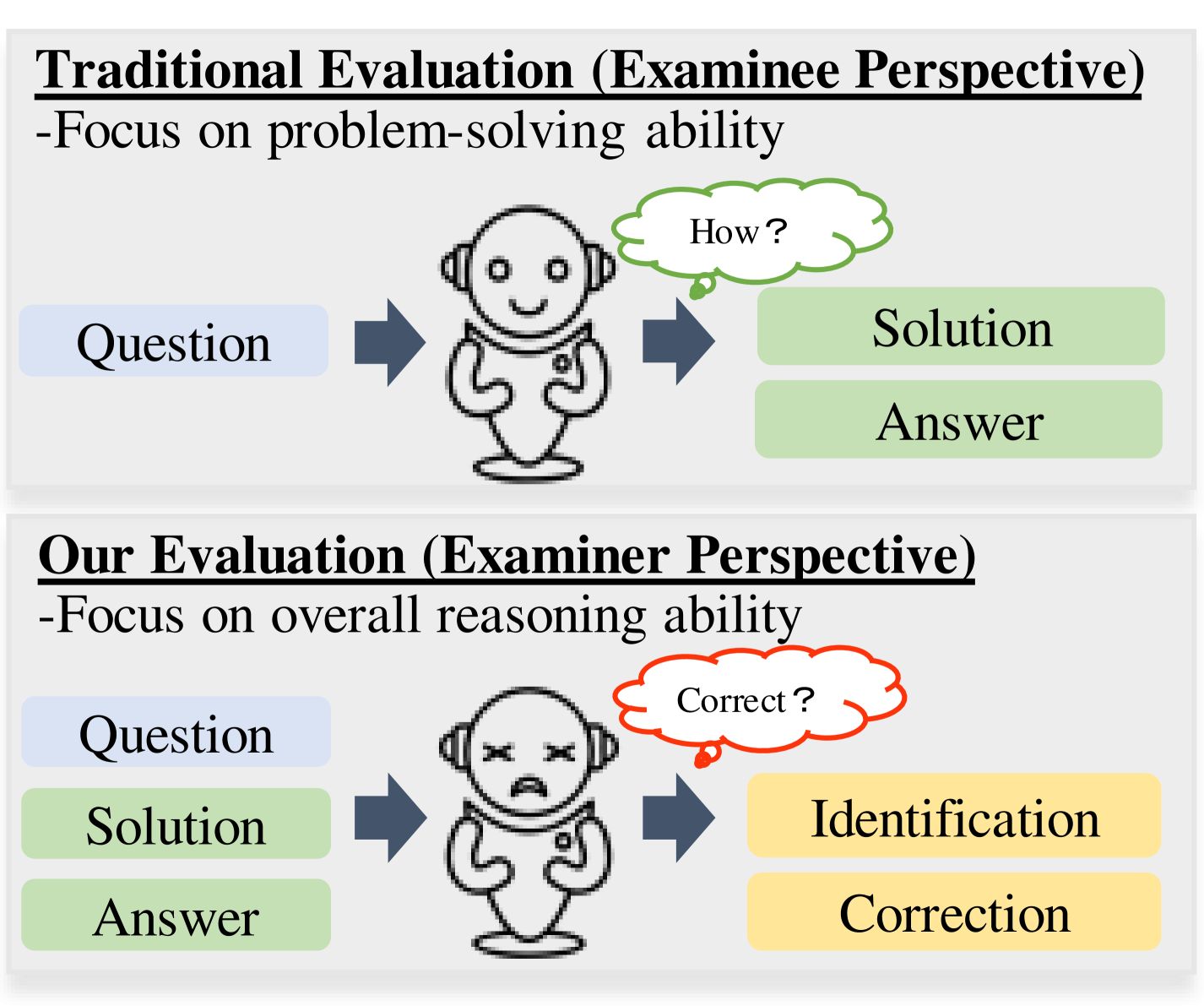
Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
Xiaoyuan Li, Wenjie Wang, Moxin Li, Junrong Guo, Yang Zhang, Fuli Feng
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Read more6/4/2024