Evaluating Mathematical Reasoning of Large Language Models: A Focus on Error Identification and Correction
2406.00755
0
0
Abstract
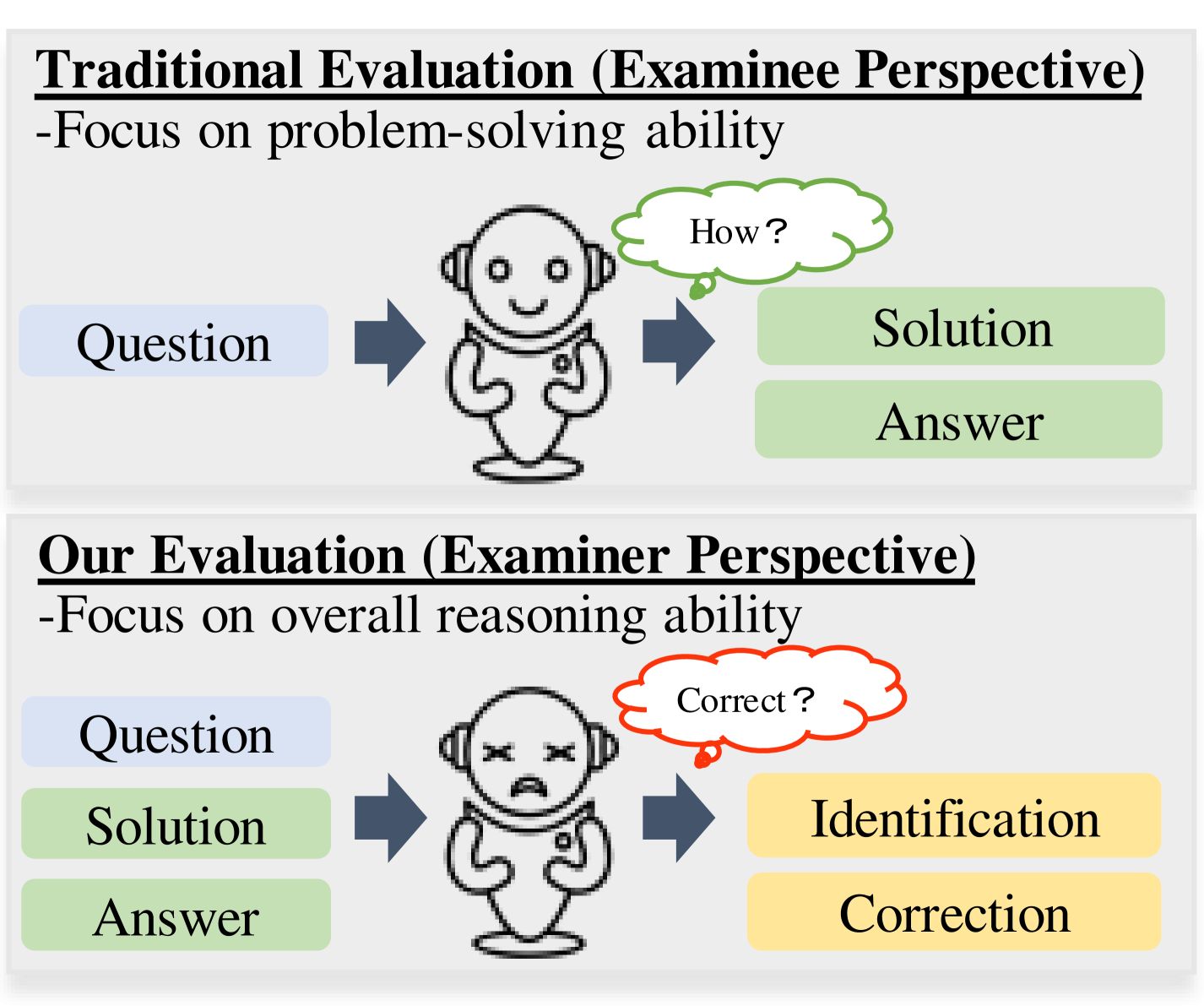
The rapid advancement of Large Language Models (LLMs) in the realm of mathematical reasoning necessitates comprehensive evaluations to gauge progress and inspire future directions. Existing assessments predominantly focus on problem-solving from the examinee perspective, overlooking a dual perspective of examiner regarding error identification and correction. From the examiner perspective, we define four evaluation tasks for error identification and correction along with a new dataset with annotated error types and steps. We also design diverse prompts to thoroughly evaluate eleven representative LLMs. Our principal findings indicate that GPT-4 outperforms all models, while open-source model LLaMA-2-7B demonstrates comparable abilities to closed-source models GPT-3.5 and Gemini Pro. Notably, calculation error proves the most challenging error type. Moreover, prompting LLMs with the error types can improve the average correction accuracy by 47.9%. These results reveal potential directions for developing the mathematical reasoning abilities of LLMs. Our code and dataset is available on https://github.com/LittleCirc1e/EIC.
Create account to get full access
Overview
- This paper evaluates the mathematical reasoning capabilities of large language models (LLMs) beyond just accuracy, focusing on their ability to identify and correct errors in their own responses.
- The researchers designed a novel task to assess LLMs' capacity to recognize and fix mathematical mistakes, going beyond previous work that only measured overall performance.
- The findings suggest that while LLMs demonstrate impressive mathematical skills, they still struggle with consistently identifying and correcting their own errors, highlighting the need for further research and development in this area.
Plain English Explanation
In this paper, the researchers set out to evaluate the mathematical reasoning abilities of large language models (LLMs) - the powerful AI systems that can understand and generate human-like text. Instead of just looking at how accurate the models are at solving math problems, the researchers wanted to see how well they could identify and fix their own mistakes.
The researchers designed a special task to test this. They would give the LLMs a math problem to solve, and then have the models review their own work to spot and correct any errors. This goes beyond previous studies that only looked at the final answer, and tries to get at the deeper question of whether these models can truly understand and reason about mathematical concepts.
The results showed that while the LLMs were generally quite good at solving the math problems, they struggled to consistently recognize and fix their own mistakes. This suggests that even though these models have impressive mathematical skills, they still have room for improvement when it comes to deeper mathematical reasoning and error correction.
The researchers believe this is an important area for further study and development. If we want to fully harness the power of LLMs for tasks like mathematical problem-solving, it will be crucial to improve their ability to catch and correct their own errors. This could have important implications for fields like education, scientific research, and even everyday tasks where accurate mathematical reasoning is crucial.
Technical Explanation
The paper presents a novel task for evaluating the mathematical reasoning capabilities of large language models (LLMs) [https://aimodels.fyi/papers/arxiv/large-language-models-are-state-art-evaluator]. Rather than just measuring overall accuracy, the researchers designed an experiment to assess the models' ability to [https://aimodels.fyi/papers/arxiv/evaluating-llms-at-detecting-errors-llm-responses] identify and correct errors in their own responses [https://aimodels.fyi/papers/arxiv/evaluating-mathematical-reasoning-beyond-accuracy].
The task involved giving LLMs a math problem, having them provide a solution, and then asking them to review their work and fix any mistakes. This allowed the researchers to go beyond simply measuring [https://aimodels.fyi/papers/arxiv/small-language-models-need-strong-verifiers-to] the final answer accuracy and instead evaluate the models' deeper understanding of the mathematical concepts and reasoning process.
The results showed that while the LLMs performed well on the initial problem-solving task, they struggled to consistently identify and correct their own errors [https://aimodels.fyi/papers/arxiv/criticbench-benchmarking-llms-critique-correct-reasoning]. This suggests that even advanced LLMs may still have limitations when it comes to comprehensive mathematical reasoning, an important insight that could inform future model development and applications.
Critical Analysis
The paper presents a novel and insightful approach to evaluating the mathematical reasoning capabilities of large language models (LLMs). By focusing on error identification and correction, the researchers were able to go beyond simply measuring overall accuracy and gain deeper insights into the models' understanding of mathematical concepts.
One potential limitation mentioned in the paper is the relatively narrow scope of the math problems used in the study. While the researchers attempted to cover a range of difficulty levels, the tasks may not fully capture the breadth of mathematical reasoning required in real-world applications. Further research could explore a wider variety of mathematical domains and problem types to more comprehensively assess the models' capabilities.
Additionally, the paper does not delve into the specific reasons why the LLMs struggled with error identification and correction. It would be helpful to understand the underlying cognitive or architectural factors that contribute to this limitation, as this could inform strategies for improving the models' mathematical reasoning abilities.
Overall, this research represents an important step forward in evaluating the mathematical reasoning of LLMs [https://aimodels.fyi/papers/arxiv/criticbench-benchmarking-llms-critique-correct-reasoning]. By focusing on error identification and correction, the study highlights the need for a more nuanced approach to assessing the models' mathematical capabilities, which could have significant implications for their real-world applications.
Conclusion
This paper presents a novel approach to evaluating the mathematical reasoning capabilities of large language models (LLMs) beyond just accuracy. By focusing on the models' ability to identify and correct errors in their own responses, the researchers uncovered important insights about the limitations of even the most advanced LLMs when it comes to deeper mathematical understanding and reasoning.
The findings suggest that while LLMs can perform well on math problem-solving tasks, they still struggle to consistently recognize and fix their own mistakes. This highlights the need for further research and development to improve the models' mathematical reasoning abilities, which could have significant implications for their use in fields like education, scientific research, and beyond.
Overall, this study represents an important step forward in the ongoing effort to fully harness the power of large language models for complex cognitive tasks [https://aimodels.fyi/papers/arxiv/large-language-models-are-state-art-evaluator]. By pushing the boundaries of how we evaluate these models, the researchers have opened up new avenues for improving their capabilities and unlocking their full potential.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Exposing the Achilles' Heel: Evaluating LLMs Ability to Handle Mistakes in Mathematical Reasoning
Joykirat Singh, Akshay Nambi, Vibhav Vineet
0
0
Large Language Models (LLMs) have been applied to Math Word Problems (MWPs) with transformative impacts, revolutionizing how these complex problems are approached and solved in various domains including educational settings. However, the evaluation of these models often prioritizes final accuracy, overlooking the crucial aspect of reasoning capabilities. This work addresses this gap by focusing on the ability of LLMs to detect and correct reasoning mistakes. We introduce a novel dataset MWP-MISTAKE, incorporating MWPs with both correct and incorrect reasoning steps generated through rule-based methods and smaller language models. Our comprehensive benchmarking reveals significant insights into the strengths and weaknesses of state-of-the-art models, such as GPT-4o, GPT-4, GPT-3.5Turbo, and others. We highlight GPT-$o's superior performance in mistake detection and rectification and the persistent challenges faced by smaller models. Additionally, we identify issues related to data contamination and memorization, impacting the reliability of LLMs in real-world applications. Our findings emphasize the importance of rigorous evaluation of reasoning processes and propose future directions to enhance the generalization and robustness of LLMs in mathematical problem-solving.
6/18/2024
Large Language Models Are State-of-the-Art Evaluator for Grammatical Error Correction
Masamune Kobayashi, Masato Mita, Mamoru Komachi
0
0
Large Language Models (LLMs) have been reported to outperform existing automatic evaluation metrics in some tasks, such as text summarization and machine translation. However, there has been a lack of research on LLMs as evaluators in grammatical error correction (GEC). In this study, we investigate the performance of LLMs in GEC evaluation by employing prompts designed to incorporate various evaluation criteria inspired by previous research. Our extensive experimental results demonstrate that GPT-4 achieved Kendall's rank correlation of 0.662 with human judgments, surpassing all existing methods. Furthermore, in recent GEC evaluations, we have underscored the significance of the LLMs scale and particularly emphasized the importance of fluency among evaluation criteria.
5/28/2024

New!Caught in the Quicksand of Reasoning, Far from AGI Summit: Evaluating LLMs' Mathematical and Coding Competency through Ontology-guided Interventions
Pengfei Hong, Deepanway Ghosal, Navonil Majumder, Somak Aditya, Rada Mihalcea, Soujanya Poria
0
0
Recent advancements in Large Language Models (LLMs) have showcased striking results on existing logical reasoning benchmarks, with some models even surpassing human performance. However, the true depth of their competencies and robustness in reasoning tasks remains an open question. To this end, in this paper, we focus on two popular reasoning tasks: arithmetic reasoning and code generation. Particularly, we introduce: (i) a general ontology of perturbations for maths and coding questions, (ii) a semi-automatic method to apply these perturbations, and (iii) two datasets, MORE and CORE, respectively, of perturbed maths and coding problems to probe the limits of LLM capabilities in numeric reasoning and coding tasks. Through comprehensive evaluations of both closed-source and open-source LLMs, we show a significant performance drop across all the models against the perturbed questions, suggesting that the current LLMs lack robust problem solving skills and structured reasoning abilities in many areas, as defined by our ontology. We open source the datasets and source codes at: https://github.com/declare-lab/llm_robustness.
6/27/2024

Evaluating LLMs at Detecting Errors in LLM Responses
Ryo Kamoi, Sarkar Snigdha Sarathi Das, Renze Lou, Jihyun Janice Ahn, Yilun Zhao, Xiaoxin Lu, Nan Zhang, Yusen Zhang, Ranran Haoran Zhang, Sujeeth Reddy Vummanthala, Salika Dave, Shaobo Qin, Arman Cohan, Wenpeng Yin, Rui Zhang
0
0
With Large Language Models (LLMs) being widely used across various tasks, detecting errors in their responses is increasingly crucial. However, little research has been conducted on error detection of LLM responses. Collecting error annotations on LLM responses is challenging due to the subjective nature of many NLP tasks, and thus previous research focuses on tasks of little practical value (e.g., word sorting) or limited error types (e.g., faithfulness in summarization). This work introduces ReaLMistake, the first error detection benchmark consisting of objective, realistic, and diverse errors made by LLMs. ReaLMistake contains three challenging and meaningful tasks that introduce objectively assessable errors in four categories (reasoning correctness, instruction-following, context-faithfulness, and parameterized knowledge), eliciting naturally observed and diverse errors in responses of GPT-4 and Llama 2 70B annotated by experts. We use ReaLMistake to evaluate error detectors based on 12 LLMs. Our findings show: 1) Top LLMs like GPT-4 and Claude 3 detect errors made by LLMs at very low recall, and all LLM-based error detectors perform much worse than humans. 2) Explanations by LLM-based error detectors lack reliability. 3) LLMs-based error detection is sensitive to small changes in prompts but remains challenging to improve. 4) Popular approaches to improving LLMs, including self-consistency and majority vote, do not improve the error detection performance. Our benchmark and code are provided at https://github.com/psunlpgroup/ReaLMistake.
4/5/2024