Beyond Boundaries: Learning a Universal Entity Taxonomy across Datasets and Languages for Open Named Entity Recognition
2406.11192
0
0
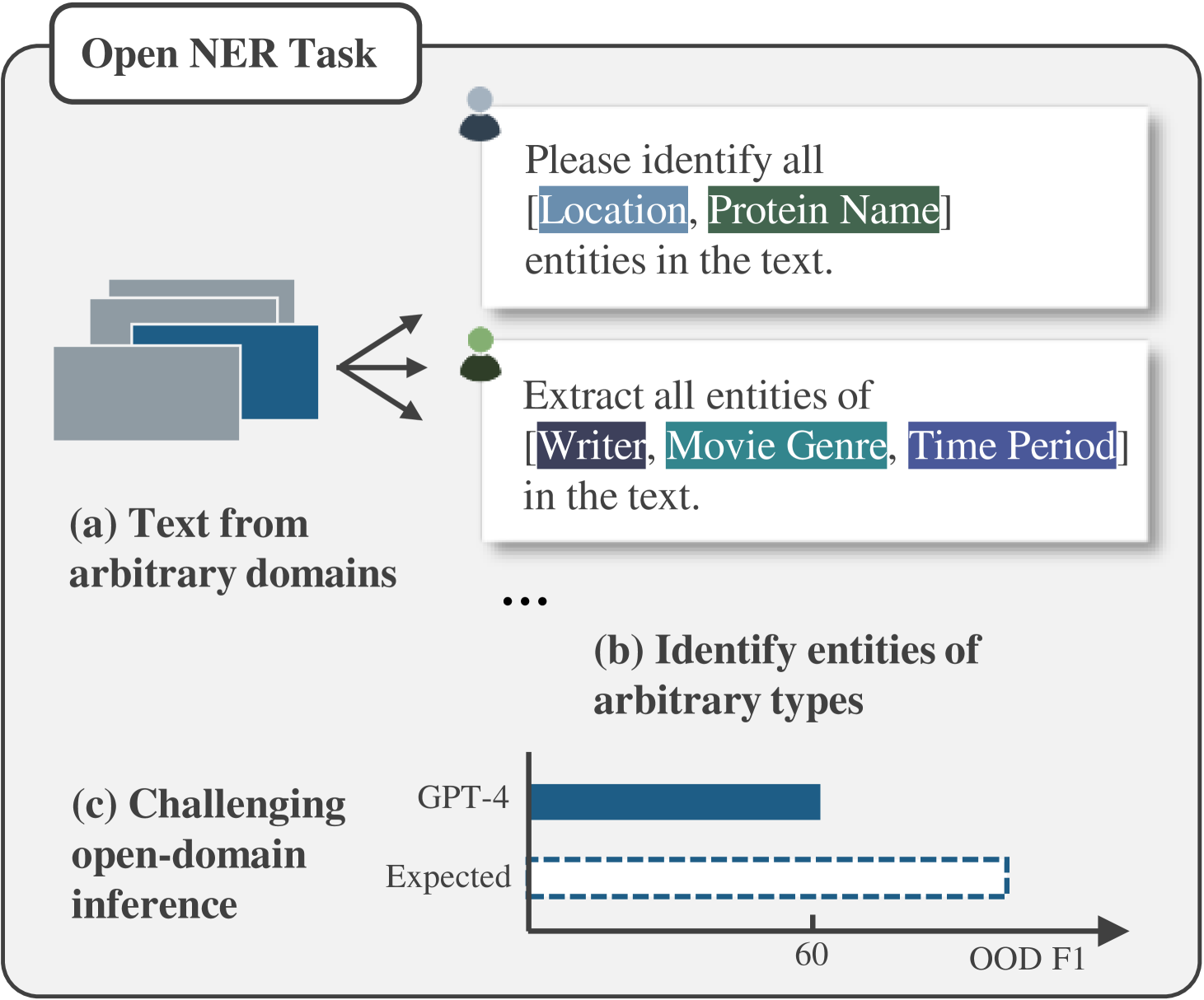
Abstract
Open Named Entity Recognition (NER), which involves identifying arbitrary types of entities from arbitrary domains, remains challenging for Large Language Models (LLMs). Recent studies suggest that fine-tuning LLMs on extensive NER data can boost their performance. However, training directly on existing datasets faces issues due to inconsistent entity definitions and redundant data, limiting LLMs to dataset-specific learning and hindering out-of-domain generalization. To address this, we present B2NERD, a cohesive and efficient dataset for Open NER, normalized from 54 existing English or Chinese datasets using a two-step approach. First, we detect inconsistent entity definitions across datasets and clarify them by distinguishable label names to construct a universal taxonomy of 400+ entity types. Second, we address redundancy using a data pruning strategy that selects fewer samples with greater category and semantic diversity. Comprehensive evaluation shows that B2NERD significantly improves LLMs' generalization on Open NER. Our B2NER models, trained on B2NERD, outperform GPT-4 by 6.8-12.0 F1 points and surpass previous methods in 3 out-of-domain benchmarks across 15 datasets and 6 languages.
Create account to get full access
Overview
- This paper proposes a novel approach for learning a universal entity taxonomy that can be applied to open-domain named entity recognition (NER) across different datasets and languages.
- The authors introduce a framework called "Beyond Boundaries" that leverages multi-task learning and meta-learning to learn a shared entity taxonomy, enabling their model to perform well on a wide range of NER tasks.
- The paper demonstrates the effectiveness of their approach on several NER benchmarks, showing improvements over state-of-the-art models.
Plain English Explanation
Named entity recognition (NER) is the task of identifying and classifying named entities, such as people, organizations, and locations, within text. Traditionally, NER models have been trained on specific datasets and languages, limiting their ability to generalize to new domains or languages.
The researchers behind this paper wanted to create a more flexible and adaptable NER system that could work well across a variety of datasets and languages. To do this, they developed a new framework called "Beyond Boundaries" that takes a different approach to training NER models.
Instead of training a model on a single dataset or language, the "Beyond Boundaries" framework uses a multi-task learning and meta-learning approach to learn a universal entity taxonomy. This means the model is trained on multiple NER datasets and languages simultaneously, allowing it to discover common patterns and structures in how entities are represented across different contexts.
By learning this shared entity taxonomy, the model can then be applied to new NER tasks and languages, without having to be retrained from scratch. The researchers tested their approach on several NER benchmarks and found that it outperformed state-of-the-art models that were trained on specific datasets or languages.
The key innovation of this work is the ability to create a single NER model that can work well in a wide range of scenarios, rather than having to develop and maintain separate models for different datasets and languages. This could lead to more efficient and flexible NER systems that can be more easily deployed in real-world applications.
Technical Explanation
The authors introduce a framework called "Beyond Boundaries" that leverages multi-task learning and meta-learning to learn a shared entity taxonomy for open-domain named entity recognition (NER). The core idea is to train a single model on multiple NER datasets and languages simultaneously, allowing it to discover common patterns and structures in how entities are represented across different contexts.
The "Beyond Boundaries" framework consists of three main components:
-
Shared Encoder: The model uses a shared encoder to process the input text, which is trained on all of the NER datasets and languages. This allows the model to learn a set of universal features and representations that are useful for NER tasks.
-
Task-Specific Heads: The model has separate task-specific heads for each NER dataset and language, which are used to generate the final entity predictions. These heads are trained to utilize the shared representations learned by the encoder.
-
Meta-Learning: The authors use a meta-learning approach to further optimize the shared encoder and task-specific heads. This involves training the model to quickly adapt to new NER tasks and languages by simulating different task distributions during training.
The authors evaluate their approach on several NER benchmarks, including Do English Named Entity Recognizers Work Well on Other Languages?, Augmenting NER Datasets with Large Language Models Towards Automated Refined Annotation, Augmenting Biomedical Named Entity Recognition with General Domain Knowledge, DistALANER: Distantly Supervised Active Learning Augmented Named Entity Recognition, and 2M-NER: Contrastive Learning for Multilingual and Multimodal Named Entity Recognition. The results show that the "Beyond Boundaries" framework outperforms state-of-the-art models that were trained on specific datasets or languages.
Critical Analysis
The "Beyond Boundaries" framework proposed in this paper offers a promising approach to addressing the limitations of traditional NER models, which are often constrained to specific datasets and languages. By leveraging multi-task learning and meta-learning, the authors have developed a more flexible and adaptable NER system that can be applied across a wide range of scenarios.
One potential caveat is that the framework still requires training on multiple NER datasets and languages, which can be resource-intensive and may not be feasible in all real-world applications. Additionally, the authors note that the performance of their model can vary depending on the specific datasets and languages used during training, suggesting that further research is needed to fully understand the limits and optimal configurations of their approach.
Another area for potential improvement is the incorporation of additional modalities, such as images or knowledge graphs, which could further enhance the model's ability to recognize and classify named entities. The authors touch on this briefly in their discussion, but more work is needed to explore the integration of multimodal information into the "Beyond Boundaries" framework.
Overall, this paper presents a compelling approach to addressing the challenges of open-domain NER, and the authors have provided a solid foundation for future research in this area. As the field of natural language processing continues to evolve, the insights and techniques presented in this work could have significant implications for the development of more robust and versatile NER systems.
Conclusion
The "Beyond Boundaries" framework introduced in this paper offers a novel approach to learning a universal entity taxonomy for open-domain named entity recognition (NER). By leveraging multi-task learning and meta-learning, the authors have developed a flexible and adaptable NER system that can be applied across a wide range of datasets and languages.
The key innovation of this work is the ability to create a single NER model that can perform well in diverse scenarios, rather than requiring the development and maintenance of separate models for different contexts. This could lead to more efficient and versatile NER systems that can be more easily deployed in real-world applications.
While the paper presents promising results, there are still some limitations and areas for further research, such as the resource-intensive training process and the potential for incorporating additional modalities. Nevertheless, the insights and techniques presented in this work could have significant implications for the future development of more robust and adaptable NER systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
👁️
New!BioMNER: A Dataset for Biomedical Method Entity Recognition
Chen Tang, Bohao Yang, Kun Zhao, Bo Lv, Chenghao Xiao, Frank Guerin, Chenghua Lin
0
0
Named entity recognition (NER) stands as a fundamental and pivotal task within the realm of Natural Language Processing. Particularly within the domain of Biomedical Method NER, this task presents notable challenges, stemming from the continual influx of domain-specific terminologies in scholarly literature. Current research in Biomedical Method (BioMethod) NER suffers from a scarcity of resources, primarily attributed to the intricate nature of methodological concepts, which necessitate a profound understanding for precise delineation. In this study, we propose a novel dataset for biomedical method entity recognition, employing an automated BioMethod entity recognition and information retrieval system to assist human annotation. Furthermore, we comprehensively explore a range of conventional and contemporary open-domain NER methodologies, including the utilization of cutting-edge large-scale language models (LLMs) customised to our dataset. Our empirical findings reveal that the large parameter counts of language models surprisingly inhibit the effective assimilation of entity extraction patterns pertaining to biomedical methods. Remarkably, the approach, leveraging the modestly sized ALBERT model (only 11MB), in conjunction with conditional random fields (CRF), achieves state-of-the-art (SOTA) performance.
7/1/2024
📈
Do English Named Entity Recognizers Work Well on Global Englishes?
Alexander Shan, John Bauer, Riley Carlson, Christopher Manning
0
0
The vast majority of the popular English named entity recognition (NER) datasets contain American or British English data, despite the existence of many global varieties of English. As such, it is unclear whether they generalize for analyzing use of English globally. To test this, we build a newswire dataset, the Worldwide English NER Dataset, to analyze NER model performance on low-resource English variants from around the world. We test widely used NER toolkits and transformer models, including models using the pre-trained contextual models RoBERTa and ELECTRA, on three datasets: a commonly used British English newswire dataset, CoNLL 2003, a more American focused dataset OntoNotes, and our global dataset. All models trained on the CoNLL or OntoNotes datasets experienced significant performance drops-over 10 F1 in some cases-when tested on the Worldwide English dataset. Upon examination of region-specific errors, we observe the greatest performance drops for Oceania and Africa, while Asia and the Middle East had comparatively strong performance. Lastly, we find that a combined model trained on the Worldwide dataset and either CoNLL or OntoNotes lost only 1-2 F1 on both test sets.
4/23/2024
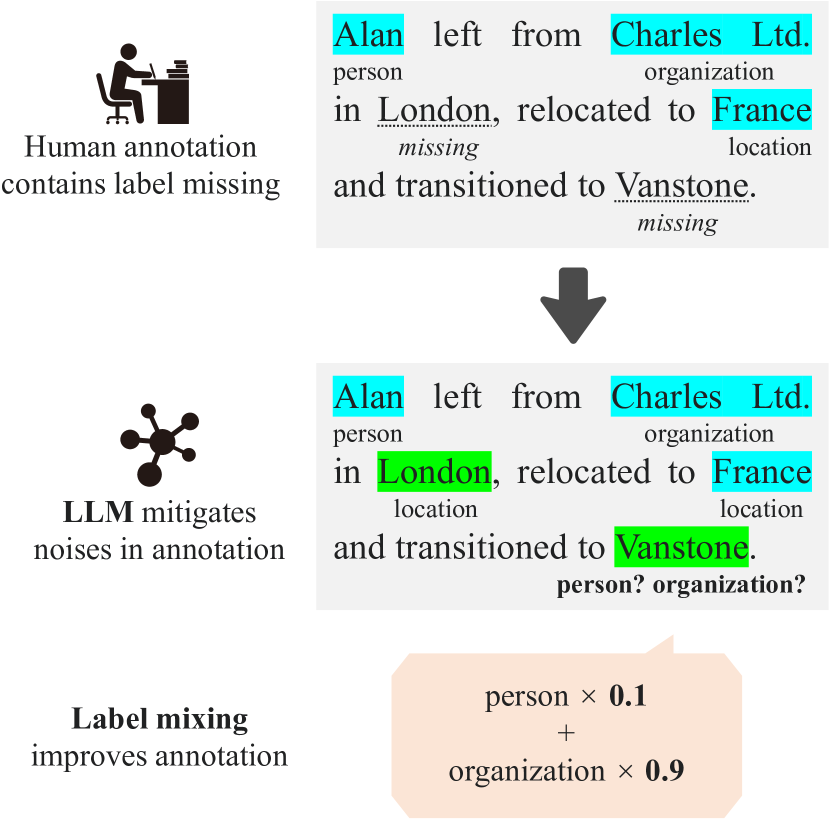
Augmenting NER Datasets with LLMs: Towards Automated and Refined Annotation
Yuji Naraki, Ryosuke Yamaki, Yoshikazu Ikeda, Takafumi Horie, Hiroki Naganuma
0
0
In the field of Natural Language Processing (NLP), Named Entity Recognition (NER) is recognized as a critical technology, employed across a wide array of applications. Traditional methodologies for annotating datasets for NER models are challenged by high costs and variations in dataset quality. This research introduces a novel hybrid annotation approach that synergizes human effort with the capabilities of Large Language Models (LLMs). This approach not only aims to ameliorate the noise inherent in manual annotations, such as omissions, thereby enhancing the performance of NER models, but also achieves this in a cost-effective manner. Additionally, by employing a label mixing strategy, it addresses the issue of class imbalance encountered in LLM-based annotations. Through an analysis across multiple datasets, this method has been consistently shown to provide superior performance compared to traditional annotation methods, even under constrained budget conditions. This study illuminates the potential of leveraging LLMs to improve dataset quality, introduces a novel technique to mitigate class imbalances, and demonstrates the feasibility of achieving high-performance NER in a cost-effective way.
4/3/2024

DistALANER: Distantly Supervised Active Learning Augmented Named Entity Recognition in the Open Source Software Ecosystem
Somnath Banerjee, Avik Dutta, Aaditya Agrawal, Rima Hazra, Animesh Mukherjee
0
0
With the AI revolution in place, the trend for building automated systems to support professionals in different domains such as the open source software systems, healthcare systems, banking systems, transportation systems and many others have become increasingly prominent. A crucial requirement in the automation of support tools for such systems is the early identification of named entities, which serves as a foundation for developing specialized functionalities. However, due to the specific nature of each domain, different technical terminologies and specialized languages, expert annotation of available data becomes expensive and challenging. In light of these challenges, this paper proposes a novel named entity recognition (NER) technique specifically tailored for the open-source software systems. Our approach aims to address the scarcity of annotated software data by employing a comprehensive two-step distantly supervised annotation process. This process strategically leverages language heuristics, unique lookup tables, external knowledge sources, and an active learning approach. By harnessing these powerful techniques, we not only enhance model performance but also effectively mitigate the limitations associated with cost and the scarcity of expert annotators. It is noteworthy that our model significantly outperforms the state-of-the-art LLMs by a substantial margin. We also show the effectiveness of NER in the downstream task of relation extraction.
6/21/2024