Do English Named Entity Recognizers Work Well on Global Englishes?
2404.13465
0
0
📈
Abstract
The vast majority of the popular English named entity recognition (NER) datasets contain American or British English data, despite the existence of many global varieties of English. As such, it is unclear whether they generalize for analyzing use of English globally. To test this, we build a newswire dataset, the Worldwide English NER Dataset, to analyze NER model performance on low-resource English variants from around the world. We test widely used NER toolkits and transformer models, including models using the pre-trained contextual models RoBERTa and ELECTRA, on three datasets: a commonly used British English newswire dataset, CoNLL 2003, a more American focused dataset OntoNotes, and our global dataset. All models trained on the CoNLL or OntoNotes datasets experienced significant performance drops-over 10 F1 in some cases-when tested on the Worldwide English dataset. Upon examination of region-specific errors, we observe the greatest performance drops for Oceania and Africa, while Asia and the Middle East had comparatively strong performance. Lastly, we find that a combined model trained on the Worldwide dataset and either CoNLL or OntoNotes lost only 1-2 F1 on both test sets.
Create account to get full access
Overview
- This paper examines whether "English" named entity recognizers, which are natural language processing models trained on standard English data, perform well on "Global Englishes" - varieties of English used around the world.
- The researchers construct a dataset of text samples from various Global English varieties and evaluate the performance of several popular named entity recognition models on this data.
- The findings suggest that these models struggle to accurately identify named entities (like people, organizations, and locations) in non-standard English, highlighting the need for more diverse training data and model development.
Plain English Explanation
The paper investigates whether natural language processing models that are trained on standard, "textbook" English work well on the many different forms of English used around the world. These "Global Englishes" can have quite different grammar, vocabulary, and styles compared to the English the models were trained on.
The researchers put together a dataset of text samples from various Global English varieties, like Indian English, Singaporean English, and Nigerian English. They then tested how well some popular named entity recognition models - which are used to automatically identify things like people's names, company names, and locations in text - could handle this non-standard English data.
The results showed that the models struggled quite a bit. They weren't very good at accurately identifying the named entities in the Global English samples, even though they perform well on standard English text. This suggests that these AI systems need to be trained on a much more diverse range of English data to be truly effective globally.
Technical Explanation
The paper evaluates the performance of named entity recognition models on "Global Englishes" - varieties of English used around the world that differ from the standard, native-speaker form in terms of grammar, vocabulary, and other linguistic features.
The researchers construct a new dataset of text samples spanning several Global English varieties, including Indian English, Singaporean English, and Nigerian English. They then benchmark the performance of several popular NER models, including ones based on large language models and cross-lingual approaches, on this dataset.
The results show that these "English" NER models struggle to accurately identify named entities in the non-standard Global English text, despite performing well on standard English. This highlights the need for more diverse training data and model development to handle the linguistic variation present in English as a global language.
Critical Analysis
The paper provides valuable insights into the limitations of current NER models when applied to English varieties beyond the standard, native-speaker form. However, it is important to note that the researchers only evaluate a small sample of Global English data, which may not be fully representative of the diversity within this space.
Furthermore, the paper does not deeply explore the reasons why the models perform poorly on the Global English data. Additional analysis into the linguistic features that pose challenges, as well as potential remedies such as data augmentation or transfer learning, could provide more actionable guidance for improving model robustness.
That said, the core finding - that "English" NER models struggle with non-standard English - is an important one that deserves further attention. As English continues to evolve and diversify globally, AI systems will need to become much more linguistically inclusive to be truly effective in real-world applications.
Conclusion
This paper sheds light on a critical limitation of current named entity recognition models: they work well on standard, native-speaker English but fail to generalize to the many "Global Englishes" used around the world. The researchers' findings highlight the need for more diverse training data and model development to ensure NER systems can handle the linguistic variation present in English as a global language.
As AI becomes increasingly embedded in everyday applications, it is vital that these systems are capable of understanding and processing the full spectrum of English usage, not just the standard, textbook variety. This paper provides a valuable first step towards addressing this challenge, which will have important implications for the accessibility and inclusivity of AI-powered technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
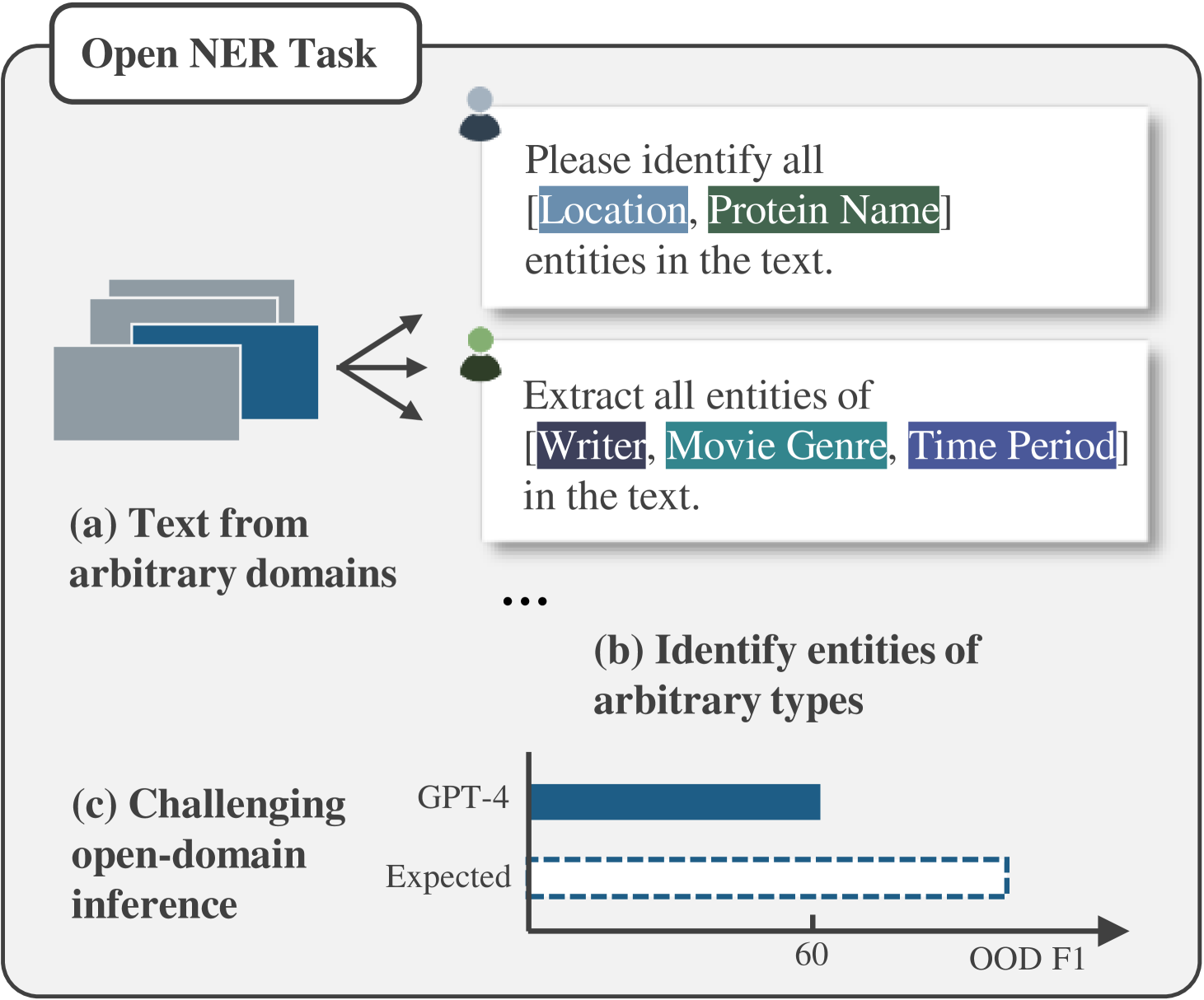
Beyond Boundaries: Learning a Universal Entity Taxonomy across Datasets and Languages for Open Named Entity Recognition
Yuming Yang, Wantong Zhao, Caishuang Huang, Junjie Ye, Xiao Wang, Huiyuan Zheng, Yang Nan, Yuran Wang, Xueying Xu, Kaixin Huang, Yunke Zhang, Tao Gui, Qi Zhang, Xuanjing Huang
0
0
Open Named Entity Recognition (NER), which involves identifying arbitrary types of entities from arbitrary domains, remains challenging for Large Language Models (LLMs). Recent studies suggest that fine-tuning LLMs on extensive NER data can boost their performance. However, training directly on existing datasets faces issues due to inconsistent entity definitions and redundant data, limiting LLMs to dataset-specific learning and hindering out-of-domain generalization. To address this, we present B2NERD, a cohesive and efficient dataset for Open NER, normalized from 54 existing English or Chinese datasets using a two-step approach. First, we detect inconsistent entity definitions across datasets and clarify them by distinguishable label names to construct a universal taxonomy of 400+ entity types. Second, we address redundancy using a data pruning strategy that selects fewer samples with greater category and semantic diversity. Comprehensive evaluation shows that B2NERD significantly improves LLMs' generalization on Open NER. Our B2NER models, trained on B2NERD, outperform GPT-4 by 6.8-12.0 F1 points and surpass previous methods in 3 out-of-domain benchmarks across 15 datasets and 6 languages.
6/18/2024
👁️
Fine-tuning Pre-trained Named Entity Recognition Models For Indian Languages
Sankalp Bahad, Pruthwik Mishra, Karunesh Arora, Rakesh Chandra Balabantaray, Dipti Misra Sharma, Parameswari Krishnamurthy
0
0
Named Entity Recognition (NER) is a useful component in Natural Language Processing (NLP) applications. It is used in various tasks such as Machine Translation, Summarization, Information Retrieval, and Question-Answering systems. The research on NER is centered around English and some other major languages, whereas limited attention has been given to Indian languages. We analyze the challenges and propose techniques that can be tailored for Multilingual Named Entity Recognition for Indian Languages. We present a human annotated named entity corpora of 40K sentences for 4 Indian languages from two of the major Indian language families. Additionally,we present a multilingual model fine-tuned on our dataset, which achieves an F1 score of 0.80 on our dataset on average. We achieve comparable performance on completely unseen benchmark datasets for Indian languages which affirms the usability of our model.
5/13/2024

MSNER: A Multilingual Speech Dataset for Named Entity Recognition
Quentin Meeus, Marie-Francine Moens, Hugo Van hamme
0
0
While extensively explored in text-based tasks, Named Entity Recognition (NER) remains largely neglected in spoken language understanding. Existing resources are limited to a single, English-only dataset. This paper addresses this gap by introducing MSNER, a freely available, multilingual speech corpus annotated with named entities. It provides annotations to the VoxPopuli dataset in four languages (Dutch, French, German, and Spanish). We have also releasing an efficient annotation tool that leverages automatic pre-annotations for faster manual refinement. This results in 590 and 15 hours of silver-annotated speech for training and validation, alongside a 17-hour, manually-annotated evaluation set. We further provide an analysis comparing silver and gold annotations. Finally, we present baseline NER models to stimulate further research on this newly available dataset.
5/21/2024
📈
Annotation Errors and NER: A Study with OntoNotes 5.0
Gabriel Bernier-Colborne, Sowmya Vajjala
0
0
Named Entity Recognition (NER) is a well-studied problem in NLP. However, there is much less focus on studying NER datasets, compared to developing new NER models. In this paper, we employed three simple techniques to detect annotation errors in the OntoNotes 5.0 corpus for English NER, which is the largest available NER corpus for English. Our techniques corrected ~10% of the sentences in train/dev/test data. In terms of entity mentions, we corrected the span and/or type of ~8% of mentions in the dataset, while adding/deleting/splitting/merging a few more. These are large numbers of changes, considering the size of OntoNotes. We used three NER libraries to train, evaluate and compare the models trained with the original and the re-annotated datasets, which showed an average improvement of 1.23% in overall F-scores, with large (>10%) improvements for some of the entity types. While our annotation error detection methods are not exhaustive and there is some manual annotation effort involved, they are largely language agnostic and can be employed with other NER datasets, and other sequence labelling tasks.
6/28/2024