Beyond the Calibration Point: Mechanism Comparison in Differential Privacy
2406.08918
0
0

Abstract
In differentially private (DP) machine learning, the privacy guarantees of DP mechanisms are often reported and compared on the basis of a single $(varepsilon, delta)$-pair. This practice overlooks that DP guarantees can vary substantially emph{even between mechanisms sharing a given $(varepsilon, delta)$}, and potentially introduces privacy vulnerabilities which can remain undetected. This motivates the need for robust, rigorous methods for comparing DP guarantees in such cases. Here, we introduce the $Delta$-divergence between mechanisms which quantifies the worst-case excess privacy vulnerability of choosing one mechanism over another in terms of $(varepsilon, delta)$, $f$-DP and in terms of a newly presented Bayesian interpretation. Moreover, as a generalisation of the Blackwell theorem, it is endowed with strong decision-theoretic foundations. Through application examples, we show that our techniques can facilitate informed decision-making and reveal gaps in the current understanding of privacy risks, as current practices in DP-SGD often result in choosing mechanisms with high excess privacy vulnerabilities.
Create account to get full access
Overview
- This paper explores the behavior of different differential privacy mechanisms beyond the calibration point, which is the point at which the privacy-utility tradeoff is optimized.
- The authors use a Bayesian framework to analyze the properties of different differential privacy mechanisms, including the Shifted Interpolation Mechanism, Contraction Mechanism, and others.
- They investigate how these mechanisms perform in settings where the query sensitivity or privacy parameter deviates from the calibration point, and provide insights into their behavior in these regimes.
Plain English Explanation
Differential privacy is a technique used to protect the privacy of individuals in datasets by adding noise to the data in a controlled way. The "calibration point" refers to the specific settings (e.g., level of noise) where the tradeoff between privacy and utility is optimized.
This paper looks at what happens when you move beyond the calibration point - for example, if you increase the privacy parameter or the sensitivity of the queries you're running on the data. The authors use a Bayesian approach to analyze the properties of different differential privacy mechanisms in these off-calibration situations.
They find that the mechanisms can behave quite differently as you move away from the calibration point. Some mechanisms, like the Shifted Interpolation Mechanism, may maintain good utility even with increased privacy, while others, like the Contraction Mechanism, may see a steep drop-off in utility.
Understanding these differences is important, because in real-world applications, you often need to operate in regimes that are not perfectly calibrated. This paper provides insights into how different differential privacy mechanisms will perform in those situations.
Technical Explanation
The authors adopt a Bayesian perspective to analyze the behavior of various differential privacy mechanisms, including the Shifted Interpolation Mechanism, Contraction Mechanism, and others.
They derive expressions for the posterior distributions of the data given the noisy output of these mechanisms, and use this to study properties like the mean squared error (MSE) of the mechanisms' estimates. By analyzing the MSE beyond the calibration point, they are able to characterize how the mechanisms' utility degrades as the privacy parameter or query sensitivity deviates from the optimal setting.
The paper shows that different mechanisms exhibit quite varied behaviors in these off-calibration regimes. For example, the Shifted Interpolation Mechanism maintains relatively stable utility even with increased privacy, while the Contraction Mechanism sees a much sharper drop-off.
These insights are valuable for practitioners who need to use differential privacy in real-world scenarios, where the optimal calibration point may not always be achievable. The analysis in this paper can help guide the selection of appropriate mechanisms based on the specific constraints and requirements of the application.
Critical Analysis
The paper provides a rigorous Bayesian analysis of differential privacy mechanisms beyond the calibration point, which is an important and understudied aspect of differential privacy. The authors' use of the posterior distribution to derive utility metrics like MSE is a principled approach that yields valuable insights.
However, the paper is limited to a theoretical analysis and does not include any empirical validation of the results. It would be helpful to see how the predicted behaviors of the mechanisms align with experimental data, especially in more realistic, high-dimensional settings.
Additionally, the paper focuses on a specific set of mechanisms, and it's unclear how the findings would generalize to other differential privacy techniques, such as the Black-Box Differential Privacy Auditing Using Total Variation Distance or the Evaluations of Machine Learning Privacy Defenses Are Misleading approaches. Expanding the analysis to a broader range of mechanisms would further strengthen the paper's contributions.
Overall, this is a well-executed theoretical study that provides valuable insights into the off-calibration behavior of differential privacy mechanisms. Future work could consider more empirical validations and a broader scope of mechanisms to enhance the practical relevance of the findings.
Conclusion
This paper presents a Bayesian analysis of the behavior of differential privacy mechanisms beyond the calibration point, where the privacy-utility tradeoff is optimized. The authors derive expressions for the posterior distributions of the data given the noisy outputs of various mechanisms, and use this to characterize their utility degradation as the privacy parameter or query sensitivity deviates from the optimal setting.
The key finding is that different mechanisms exhibit quite varied behaviors in these off-calibration regimes, with some like the Shifted Interpolation Mechanism maintaining relatively stable utility even with increased privacy, while others like the Contraction Mechanism see a much sharper drop-off. These insights can help guide the selection of appropriate differential privacy mechanisms for real-world applications with non-optimal calibration settings.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
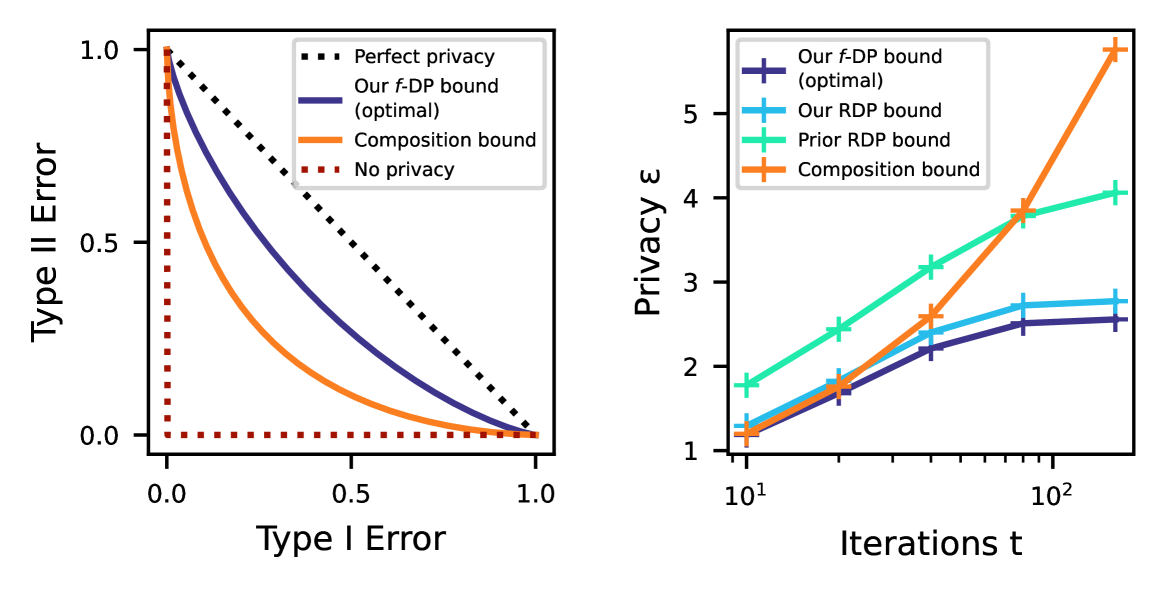
Shifted Interpolation for Differential Privacy
Jinho Bok, Weijie Su, Jason M. Altschuler
0
0
Noisy gradient descent and its variants are the predominant algorithms for differentially private machine learning. It is a fundamental question to quantify their privacy leakage, yet tight characterizations remain open even in the foundational setting of convex losses. This paper improves over previous analyses by establishing (and refining) the privacy amplification by iteration phenomenon in the unifying framework of $f$-differential privacy--which tightly captures all aspects of the privacy loss and immediately implies tighter privacy accounting in other notions of differential privacy, e.g., $(varepsilon,delta)$-DP and R'enyi DP. Our key technical insight is the construction of shifted interpolated processes that unravel the popular shifted-divergences argument, enabling generalizations beyond divergence-based relaxations of DP. Notably, this leads to the first exact privacy analysis in the foundational setting of strongly convex optimization. Our techniques extend to many settings: convex/strongly convex, constrained/unconstrained, full/cyclic/stochastic batches, and all combinations thereof. As an immediate corollary, we recover the $f$-DP characterization of the exponential mechanism for strongly convex optimization in Gopi et al. (2022), and moreover extend this result to more general settings.
6/13/2024
🗣️
Contraction of Locally Differentially Private Mechanisms
Shahab Asoodeh, Huanyu Zhang
0
0
We investigate the contraction properties of locally differentially private mechanisms. More specifically, we derive tight upper bounds on the divergence between $PK$ and $QK$ output distributions of an $epsilon$-LDP mechanism $K$ in terms of a divergence between the corresponding input distributions $P$ and $Q$, respectively. Our first main technical result presents a sharp upper bound on the $chi^2$-divergence $chi^2(PK}|QK)$ in terms of $chi^2(P|Q)$ and $varepsilon$. We also show that the same result holds for a large family of divergences, including KL-divergence and squared Hellinger distance. The second main technical result gives an upper bound on $chi^2(PK|QK)$ in terms of total variation distance $mathsf{TV}(P, Q)$ and $epsilon$. We then utilize these bounds to establish locally private versions of the van Trees inequality, Le Cam's, Assouad's, and the mutual information methods, which are powerful tools for bounding minimax estimation risks. These results are shown to lead to better privacy analyses than the state-of-the-arts in several statistical problems such as entropy and discrete distribution estimation, non-parametric density estimation, and hypothesis testing.
5/6/2024
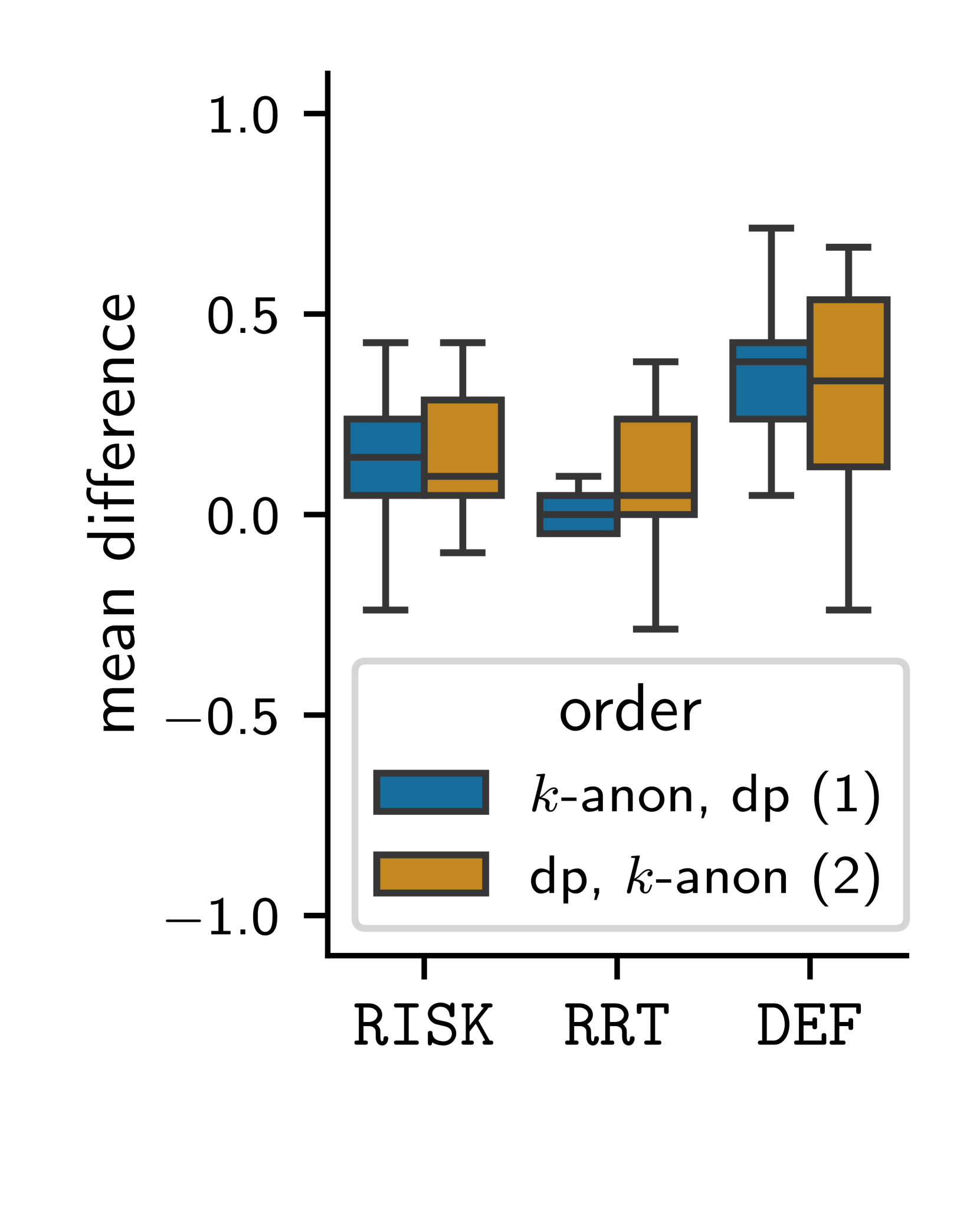
From Theory to Comprehension: A Comparative Study of Differential Privacy and $k$-Anonymity
Saskia Nu~nez von Voigt, Luise Mehner, Florian Tschorsch
0
0
The notion of $varepsilon$-differential privacy is a widely used concept of providing quantifiable privacy to individuals. However, it is unclear how to explain the level of privacy protection provided by a differential privacy mechanism with a set $varepsilon$. In this study, we focus on users' comprehension of the privacy protection provided by a differential privacy mechanism. To do so, we study three variants of explaining the privacy protection provided by differential privacy: (1) the original mathematical definition; (2) $varepsilon$ translated into a specific privacy risk; and (3) an explanation using the randomized response technique. We compare users' comprehension of privacy protection employing these explanatory models with their comprehension of privacy protection of $k$-anonymity as baseline comprehensibility. Our findings suggest that participants' comprehension of differential privacy protection is enhanced by the privacy risk model and the randomized response-based model. Moreover, our results confirm our intuition that privacy protection provided by $k$-anonymity is more comprehensible.
4/8/2024

Black Box Differential Privacy Auditing Using Total Variation Distance
Antti Koskela, Jafar Mohammadi
0
0
We present a practical method to audit the differential privacy (DP) guarantees of a machine learning model using a small hold-out dataset that is not exposed to the model during the training. Having a score function such as the loss function employed during the training, our method estimates the total variation (TV) distance between scores obtained with a subset of the training data and the hold-out dataset. With some meta information about the underlying DP training algorithm, these TV distance values can be converted to $(varepsilon,delta)$-guarantees for any $delta$. We show that these score distributions asymptotically give lower bounds for the DP guarantees of the underlying training algorithm, however, we perform a one-shot estimation for practicality reasons. We specify conditions that lead to lower bounds for the DP guarantees with high probability. To estimate the TV distance between the score distributions, we use a simple density estimation method based on histograms. We show that the TV distance gives a very close to optimally robust estimator and has an error rate $mathcal{O}(k^{-1/3})$, where $k$ is the total number of samples. Numerical experiments on benchmark datasets illustrate the effectiveness of our approach and show improvements over baseline methods for black-box auditing.
6/10/2024