From Theory to Comprehension: A Comparative Study of Differential Privacy and $k$-Anonymity
2404.04006
0
0
Abstract
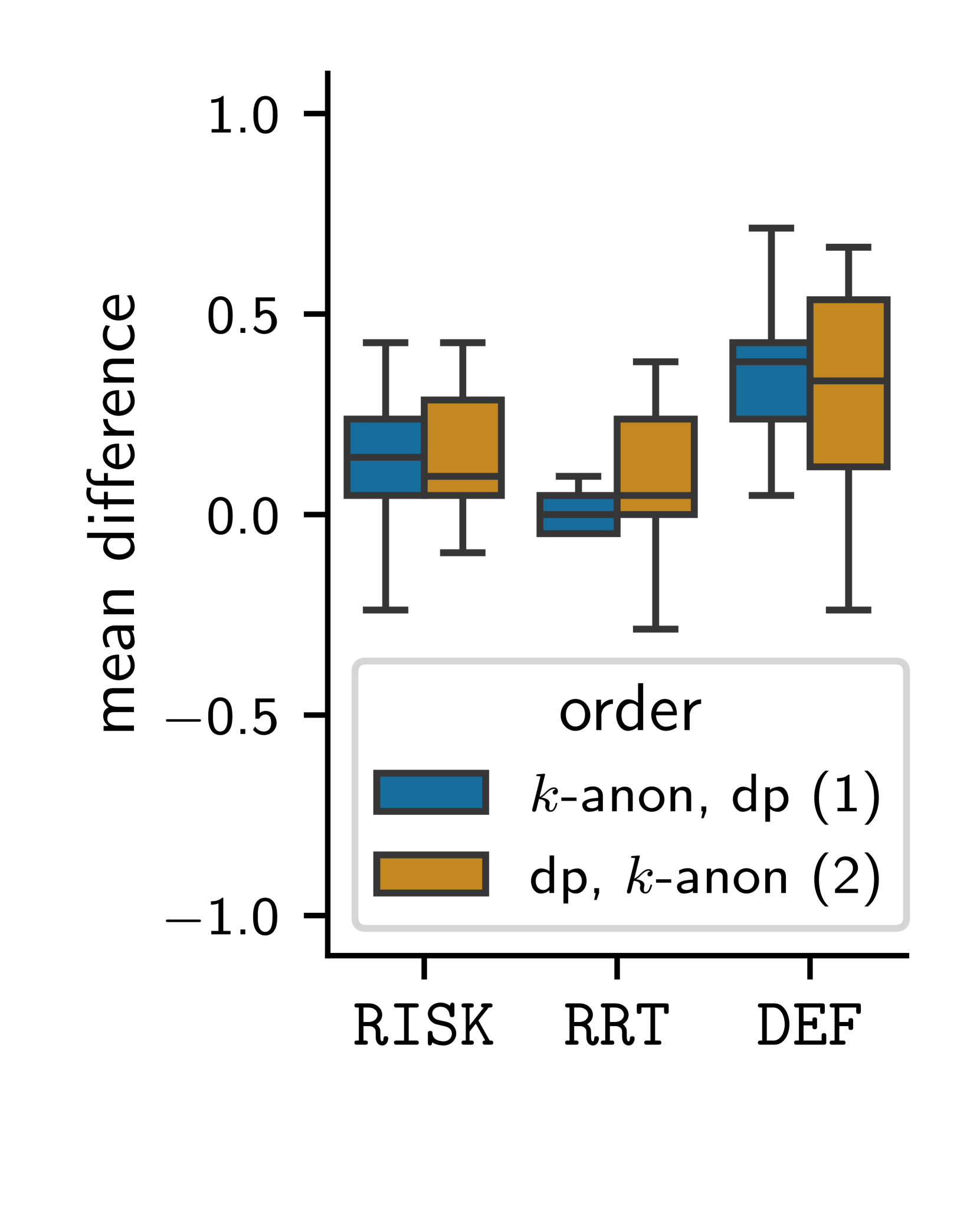
The notion of $varepsilon$-differential privacy is a widely used concept of providing quantifiable privacy to individuals. However, it is unclear how to explain the level of privacy protection provided by a differential privacy mechanism with a set $varepsilon$. In this study, we focus on users' comprehension of the privacy protection provided by a differential privacy mechanism. To do so, we study three variants of explaining the privacy protection provided by differential privacy: (1) the original mathematical definition; (2) $varepsilon$ translated into a specific privacy risk; and (3) an explanation using the randomized response technique. We compare users' comprehension of privacy protection employing these explanatory models with their comprehension of privacy protection of $k$-anonymity as baseline comprehensibility. Our findings suggest that participants' comprehension of differential privacy protection is enhanced by the privacy risk model and the randomized response-based model. Moreover, our results confirm our intuition that privacy protection provided by $k$-anonymity is more comprehensible.
Create account to get full access
Overview
- This paper presents a comparative study of two data privacy techniques: differential privacy and k-anonymity.
- The researchers aim to understand the practical implications and tradeoffs of these approaches through an explanatory model.
- The study explores how these techniques can be effectively communicated to non-technical stakeholders to improve comprehension and adoption.
Plain English Explanation
Protecting people's privacy when working with data is crucial, but the technical details can be complex. This paper looks at two main ways to do this: differential privacy and k-anonymity.
Differential privacy adds a small amount of random 'noise' to data to obscure individual information, while k-anonymity groups similar people together so they can't be singled out. The researchers wanted to understand how well these methods work in the real world and how easy they are for non-experts to grasp.
They created explanatory models to break down the key ideas behind each approach. This helps people without a technical background, like policymakers or the general public, better comprehend the tradeoffs and implications of using these privacy techniques.
For example, the models might use analogies or simple examples to illustrate concepts like the 'privacy budget' in differential privacy or how k-anonymity protects against re-identification. The goal is to demystify these complex topics and enable more informed discussions about data privacy.
Technical Explanation
The paper develops explanatory models to facilitate better understanding of differential privacy and k-anonymity among non-technical stakeholders.
The differential privacy model focuses on concepts like the privacy budget, noise addition, and the tradeoff between privacy and utility. The k-anonymity model explains how grouping similar individuals can prevent re-identification, along with challenges around defining similarity and group size.
Through user studies, the researchers evaluate how well these models communicate the key principles and tradeoffs to participants with varying levels of technical expertise. They measure factors like comprehension, perceived usefulness, and trust in the privacy guarantees.
The results suggest that the explanatory models can significantly improve understanding compared to traditional technical descriptions, especially for non-experts. Participants were able to grasp the high-level ideas and make more informed judgments about when to apply each technique.
Critical Analysis
The paper acknowledges limitations in the scope and generalizability of the study. The user evaluations were conducted with a relatively small and homogeneous sample, so further research is needed to assess the models' effectiveness across more diverse populations.
Additionally, the paper does not delve into more nuanced issues, such as the relationship between local differential privacy and average or the challenges of robust constrained consensus in distributed optimization. Exploring these complexities could further strengthen the explanatory models.
Overall, the study represents a valuable step towards bridging the gap between the technical details of data privacy methods and their practical implications for non-expert stakeholders. Continuing to develop effective communication strategies is crucial for fostering informed debates and responsible data use.
Conclusion
This paper presents a comparative study of differential privacy and k-anonymity, two prominent data privacy techniques, through the lens of explanatory models. By breaking down the key principles and tradeoffs in accessible terms, the researchers aim to improve comprehension and adoption of these methods among non-technical stakeholders.
The results suggest that well-designed explanatory models can significantly enhance understanding, even for participants with limited technical expertise. This is an important step towards enabling more informed discussions and decision-making around data privacy policies and practices.
As data plays an increasingly central role in our lives, it is crucial that the general public and policymakers can meaningfully engage with the technical complexities. This paper demonstrates a promising approach to bridging that gap and promoting more transparent and accountable data governance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Beyond the Calibration Point: Mechanism Comparison in Differential Privacy
Georgios Kaissis, Stefan Kolek, Borja Balle, Jamie Hayes, Daniel Rueckert
0
0
In differentially private (DP) machine learning, the privacy guarantees of DP mechanisms are often reported and compared on the basis of a single $(varepsilon, delta)$-pair. This practice overlooks that DP guarantees can vary substantially emph{even between mechanisms sharing a given $(varepsilon, delta)$}, and potentially introduces privacy vulnerabilities which can remain undetected. This motivates the need for robust, rigorous methods for comparing DP guarantees in such cases. Here, we introduce the $Delta$-divergence between mechanisms which quantifies the worst-case excess privacy vulnerability of choosing one mechanism over another in terms of $(varepsilon, delta)$, $f$-DP and in terms of a newly presented Bayesian interpretation. Moreover, as a generalisation of the Blackwell theorem, it is endowed with strong decision-theoretic foundations. Through application examples, we show that our techniques can facilitate informed decision-making and reveal gaps in the current understanding of privacy risks, as current practices in DP-SGD often result in choosing mechanisms with high excess privacy vulnerabilities.
6/14/2024
↗️
Causal Discovery Under Local Privacy
R=uta Binkyt.e, Carlos Pinz'on, Szilvia Lesty'an, Kangsoo Jung, H'eber H. Arcolezi, Catuscia Palamidessi
0
0
Differential privacy is a widely adopted framework designed to safeguard the sensitive information of data providers within a data set. It is based on the application of controlled noise at the interface between the server that stores and processes the data, and the data consumers. Local differential privacy is a variant that allows data providers to apply the privatization mechanism themselves on their data individually. Therefore it provides protection also in contexts in which the server, or even the data collector, cannot be trusted. The introduction of noise, however, inevitably affects the utility of the data, particularly by distorting the correlations between individual data components. This distortion can prove detrimental to tasks such as causal discovery. In this paper, we consider various well-known locally differentially private mechanisms and compare the trade-off between the privacy they provide, and the accuracy of the causal structure produced by algorithms for causal learning when applied to data obfuscated by these mechanisms. Our analysis yields valuable insights for selecting appropriate local differentially private protocols for causal discovery tasks. We foresee that our findings will aid researchers and practitioners in conducting locally private causal discovery.
5/6/2024

A Comparative Analysis of Word-Level Metric Differential Privacy: Benchmarking The Privacy-Utility Trade-off
Stephen Meisenbacher, Nihildev Nandakumar, Alexandra Klymenko, Florian Matthes
0
0
The application of Differential Privacy to Natural Language Processing techniques has emerged in relevance in recent years, with an increasing number of studies published in established NLP outlets. In particular, the adaptation of Differential Privacy for use in NLP tasks has first focused on the $textit{word-level}$, where calibrated noise is added to word embedding vectors to achieve noisy representations. To this end, several implementations have appeared in the literature, each presenting an alternative method of achieving word-level Differential Privacy. Although each of these includes its own evaluation, no comparative analysis has been performed to investigate the performance of such methods relative to each other. In this work, we conduct such an analysis, comparing seven different algorithms on two NLP tasks with varying hyperparameters, including the $textit{epsilon ($varepsilon$)}$ parameter, or privacy budget. In addition, we provide an in-depth analysis of the results with a focus on the privacy-utility trade-off, as well as open-source our implementation code for further reproduction. As a result of our analysis, we give insight into the benefits and challenges of word-level Differential Privacy, and accordingly, we suggest concrete steps forward for the research field.
4/5/2024
🤿
Centering Policy and Practice: Research Gaps around Usable Differential Privacy
Rachel Cummings, Jayshree Sarathy
0
0
As a mathematically rigorous framework that has amassed a rich theoretical literature, differential privacy is considered by many experts to be the gold standard for privacy-preserving data analysis. Others argue that while differential privacy is a clean formulation in theory, it poses significant challenges in practice. Both perspectives are, in our view, valid and important. To bridge the gaps between differential privacy's promises and its real-world usability, researchers and practitioners must work together to advance policy and practice of this technology. In this paper, we outline pressing open questions towards building usable differential privacy and offer recommendations for the field, such as developing risk frameworks to align with user needs, tailoring communications for different stakeholders, modeling the impact of privacy-loss parameters, investing in effective user interfaces, and facilitating algorithmic and procedural audits of differential privacy systems.
6/19/2024