Beyond Fine-tuning: Unleashing the Potential of Continuous Pretraining for Clinical LLMs

0

Sign in to get full access
Overview
- Researchers propose a novel approach called "Continuous Pretraining" to further improve the performance of clinical large language models (LLMs)
- This goes beyond traditional fine-tuning techniques by continuously updating the pre-trained model during its deployment
- Experiments show this approach leads to significant improvements in various clinical tasks compared to fine-tuning alone
Plain English Explanation
The paper introduces a new way to make clinical language models even better at their tasks. Normally, these models are first trained on a large amount of general text data, and then "fine-tuned" on smaller datasets specific to the clinical domain.
The researchers found that you can get an extra boost in performance by continuously updating the model's knowledge as it is being used. Rather than just fine-tuning it once, the model keeps learning from the data it encounters during real-world deployment. [This is like a human doctor continuously learning from their experiences with patients, rather than just relying on their initial medical training.]
The experiments showed this "continuous pretraining" approach led to significant improvements across various clinical tasks, like diagnosis prediction and clinical note generation, compared to the standard fine-tuning method. [It's like the clinical language model is continually sharpening its skills instead of just sticking with what it learned initially.]
The key insight is that by allowing the model to evolve and adapt over time, you can unlock more of its potential compared to freezing it after the initial fine-tuning stage. [It's similar to how the best human experts are always learning and improving, not just relying on their initial training.]
Technical Explanation
The paper introduces a novel "Continuous Pretraining" approach to further improve the performance of clinical language models beyond standard fine-tuning techniques. [Link: https://aimodels.fyi/papers/arxiv/efficient-continual-pre-training-by-mitigating-stability]
In this approach, the pre-trained model is continuously updated during its real-world deployment, rather than just being fine-tuned once on a smaller dataset. The researchers design a training pipeline that allows the model to continuously learn from new data it encounters, gradually enhancing its clinical knowledge and capabilities.
The key innovations include:
- Efficient Sampling: The model selectively samples the most informative data points from the incoming stream to update itself, rather than using all data indiscriminately.
- Stability Preservation: The researchers employ techniques to ensure the model retains its general language understanding capabilities while continuously adapting to the clinical domain.
Extensive experiments on various clinical tasks like diagnosis prediction and note generation demonstrate significant performance gains from this continuous pretraining approach compared to standard fine-tuning. [Link: https://aimodels.fyi/papers/arxiv/leveraging-large-language-models-knowledge-free-weak]
Critical Analysis
The paper provides a thoughtful and well-designed approach to further improving clinical language models beyond standard fine-tuning. The continuous pretraining method is a clever way to unlock more of the model's potential by allowing it to evolve and adapt over time, rather than just freezing its capabilities after the initial fine-tuning stage.
That said, the authors do acknowledge some potential limitations and avenues for future research. For example, they note the need to carefully monitor the model's stability and general language understanding during the continuous pretraining process. [Link: https://aimodels.fyi/papers/arxiv/ultimate-guide-to-fine-tuning-llms-from]
Additionally, the experiments were conducted on a limited set of clinical tasks, so further validation on a wider range of real-world clinical applications would help solidify the generalizability of the findings. [Link: https://aimodels.fyi/papers/arxiv/can-llms-tuning-methods-work-medical-multimodal]
Overall, this paper presents a promising new direction for improving clinical language models, and the continuous pretraining approach seems well-worth further exploration and refinement by the research community.
Conclusion
This paper introduces a novel "Continuous Pretraining" technique that goes beyond traditional fine-tuning to further enhance the performance of clinical language models. By allowing the model to continuously learn and adapt during real-world deployment, the researchers were able to achieve significant improvements across various clinical tasks compared to standard fine-tuning.
The key insights and innovations, such as efficient sampling and stability preservation, provide a solid foundation for unlocking more of the potential of large language models in the clinical domain. While some limitations and future research directions were identified, this work represents an important step forward in advancing the state-of-the-art in clinical NLP.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Fine-tuning: Unleashing the Potential of Continuous Pretraining for Clinical LLMs
Cl'ement Christophe, Tathagata Raha, Svetlana Maslenkova, Muhammad Umar Salman, Praveen K Kanithi, Marco AF Pimentel, Shadab Khan
Large Language Models (LLMs) have demonstrated significant potential in transforming clinical applications. In this study, we investigate the efficacy of four techniques in adapting LLMs for clinical use-cases: continuous pretraining, instruct fine-tuning, NEFTune, and prompt engineering. We employ these methods on Mistral 7B and Mixtral 8x7B models, leveraging a large-scale clinical pretraining dataset of 50 billion tokens and an instruct fine-tuning dataset of 500 million tokens. Our evaluation across various clinical tasks reveals the impact of each technique. While continuous pretraining beyond 250 billion tokens yields marginal improvements on its own, it establishes a strong foundation for instruct fine-tuning. Notably, NEFTune, designed primarily to enhance generation quality, surprisingly demonstrates additional gains on our benchmark. Complex prompt engineering methods further enhance performance. These findings show the importance of tailoring fine-tuning strategies and exploring innovative techniques to optimize LLM performance in the clinical domain.
Read more9/24/2024
0
Efficient Continual Pre-training by Mitigating the Stability Gap
Yiduo Guo, Jie Fu, Huishuai Zhang, Dongyan Zhao, Yikang Shen
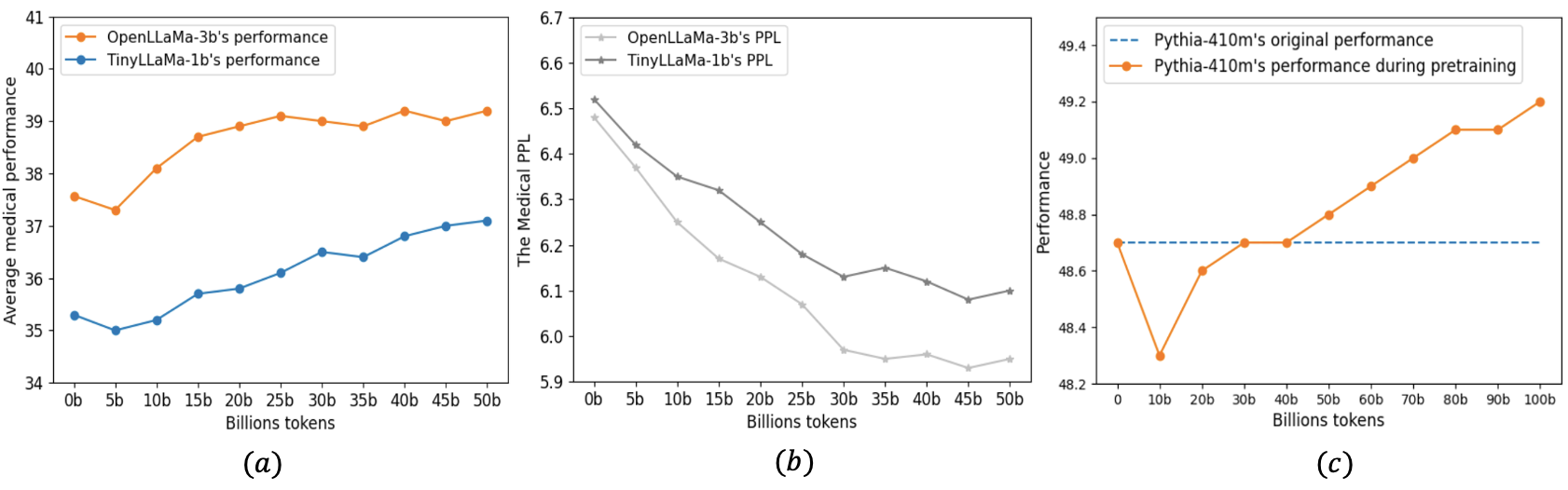
Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the stability gap, previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
Read more6/28/2024

0
The Ultimate Guide to Fine-Tuning LLMs from Basics to Breakthroughs: An Exhaustive Review of Technologies, Research, Best Practices, Applied Research Challenges and Opportunities
Venkatesh Balavadhani Parthasarathy, Ahtsham Zafar, Aafaq Khan, Arsalan Shahid
This report examines the fine-tuning of Large Language Models (LLMs), integrating theoretical insights with practical applications. It outlines the historical evolution of LLMs from traditional Natural Language Processing (NLP) models to their pivotal role in AI. A comparison of fine-tuning methodologies, including supervised, unsupervised, and instruction-based approaches, highlights their applicability to different tasks. The report introduces a structured seven-stage pipeline for fine-tuning LLMs, spanning data preparation, model initialization, hyperparameter tuning, and model deployment. Emphasis is placed on managing imbalanced datasets and optimization techniques. Parameter-efficient methods like Low-Rank Adaptation (LoRA) and Half Fine-Tuning are explored for balancing computational efficiency with performance. Advanced techniques such as memory fine-tuning, Mixture of Experts (MoE), and Mixture of Agents (MoA) are discussed for leveraging specialized networks and multi-agent collaboration. The report also examines novel approaches like Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO), which align LLMs with human preferences, alongside pruning and routing optimizations to improve efficiency. Further sections cover validation frameworks, post-deployment monitoring, and inference optimization, with attention to deploying LLMs on distributed and cloud-based platforms. Emerging areas such as multimodal LLMs, fine-tuning for audio and speech, and challenges related to scalability, privacy, and accountability are also addressed. This report offers actionable insights for researchers and practitioners navigating LLM fine-tuning in an evolving landscape.
Read more8/27/2024

0
New!Breaking Language Barriers: Cross-Lingual Continual Pre-Training at Scale
Wenzhen Zheng, Wenbo Pan, Xu Xu, Libo Qin, Li Yue, Ming Zhou
In recent years, Large Language Models (LLMs) have made significant strides towards Artificial General Intelligence. However, training these models from scratch requires substantial computational resources and vast amounts of text data. In this paper, we explore an alternative approach to constructing an LLM for a new language by continually pretraining (CPT) from existing pretrained LLMs, instead of using randomly initialized parameters. Based on parallel experiments on 40 model sizes ranging from 40M to 5B parameters, we find that 1) CPT converges faster and saves significant resources in a scalable manner; 2) CPT adheres to an extended scaling law derived from Hoffmann et al. (2022) with a joint data-parameter scaling term; 3) The compute-optimal data-parameter allocation for CPT markedly differs based on our estimated scaling factors; 4) The effectiveness of transfer at scale is influenced by training duration and linguistic properties, while robust to data replaying, a method that effectively mitigates catastrophic forgetting in CPT. We hope our findings provide deeper insights into the transferability of LLMs at scale for the research community.
Read more10/3/2024