Efficient Continual Pre-training by Mitigating the Stability Gap
2406.14833
0
0
Abstract
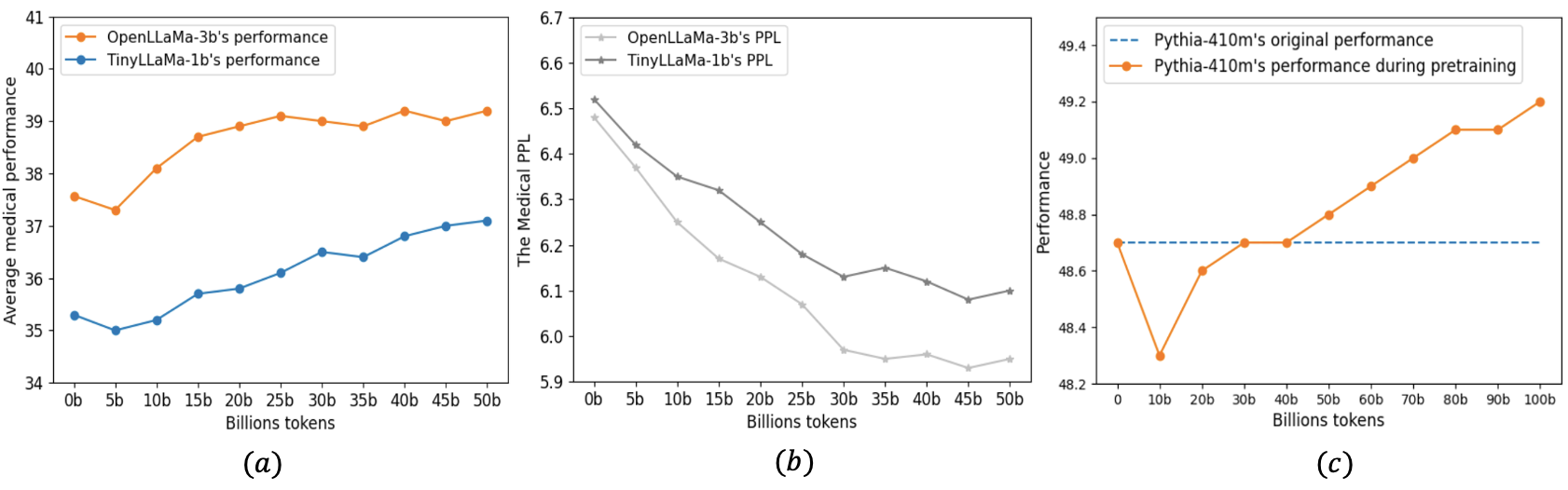
Continual pre-training has increasingly become the predominant approach for adapting Large Language Models (LLMs) to new domains. This process involves updating the pre-trained LLM with a corpus from a new domain, resulting in a shift in the training distribution. To study the behavior of LLMs during this shift, we measured the model's performance throughout the continual pre-training process. we observed a temporary performance drop at the beginning, followed by a recovery phase, a phenomenon known as the stability gap, previously noted in vision models classifying new classes. To address this issue and enhance LLM performance within a fixed compute budget, we propose three effective strategies: (1) Continually pre-training the LLM on a subset with a proper size for multiple epochs, resulting in faster performance recovery than pre-training the LLM on a large corpus in a single epoch; (2) Pre-training the LLM only on high-quality sub-corpus, which rapidly boosts domain performance; and (3) Using a data mixture similar to the pre-training data to reduce distribution gap. We conduct various experiments on Llama-family models to validate the effectiveness of our strategies in both medical continual pre-training and instruction tuning. For example, our strategies improve the average medical task performance of the OpenLlama-3B model from 36.2% to 40.7% with only 40% of the original training budget and enhance the average general task performance without causing forgetting. Furthermore, we apply our strategies to the Llama-3-8B model. The resulting model, Llama-3-Physician, achieves the best medical performance among current open-source models, and performs comparably to or even better than GPT-4 on several medical benchmarks. We release our models at url{https://huggingface.co/YiDuo1999/Llama-3-Physician-8B-Instruct}.
Create account to get full access
Overview
- This paper proposes a method to efficiently continue pre-training large language models (LLMs) on new data while mitigating the "stability gap" - the tendency for LLMs to forget previously learned knowledge when fine-tuned on new tasks.
- The authors introduce a novel technique called "Stability-Aware Continual Pre-Training" (SACP) that allows LLMs to continuously learn new information without compromising their previously acquired knowledge.
- The method is evaluated on several benchmark datasets, demonstrating improved performance and stability compared to traditional continual pre-training approaches.
Plain English Explanation
Large language models (LLMs) like BERT and GPT-3 are powerful AI systems that can understand and generate human-like text. However, these models can struggle to learn new information without forgetting what they've previously learned, a problem known as the "stability gap."
The researchers in this paper have developed a new technique called "Stability-Aware Continual Pre-Training" (SACP) to help LLMs overcome this issue. The key idea is to train the model in a way that allows it to continuously learn new information while preserving its existing knowledge. This is achieved through a combination of techniques, such as adjusting the model's learning rate and introducing special "stability-aware" training objectives.
By using SACP, the researchers were able to show that LLMs can be efficiently updated with new data without losing their previous capabilities. This is an important advance, as it means these powerful AI systems can be kept up-to-date and relevant over time, without having to completely retrain them from scratch.
Technical Explanation
The paper introduces a novel technique called "Stability-Aware Continual Pre-Training" (SACP) to address the "stability gap" problem in continual pre-training of large language models (LLMs).
The stability gap refers to the tendency of LLMs to forget previously learned knowledge when fine-tuned on new tasks or data. To mitigate this issue, the authors propose SACP, which consists of three key components:
-
Stability-Aware Gradient Weighting (SAGW): This component dynamically adjusts the learning rate for different parts of the model, placing more emphasis on preserving the stability of important parameters while allowing the less important ones to adapt to new data.
-
Stability-Aware Regularization (SAR): This technique introduces a novel regularization term that encourages the model to maintain its previous performance on a held-out validation set, thereby preventing catastrophic forgetting.
-
Stability-Aware Initialization (SAI): The authors initialize the model's parameters using a pre-trained checkpoint, which helps preserve the model's existing knowledge and facilitates efficient continual pre-training.
The researchers evaluate SACP on several benchmark tasks, including language modeling, text classification, and question answering. Their results demonstrate that SACP can significantly improve the efficiency and stability of continual pre-training compared to traditional approaches, with the model maintaining high performance on both new and old tasks.
Critical Analysis
The paper presents a compelling solution to the stability gap problem in continual pre-training of LLMs. The authors have carefully designed SACP to address the key challenges, and their experimental results provide strong evidence for the effectiveness of the proposed method.
One potential limitation of the study is that it primarily focuses on continual pre-training of LLMs on textual data. It would be interesting to see if SACP can be extended to other modalities, such as vision or multimodal tasks, to further demonstrate its broader applicability.
Additionally, the paper does not provide a detailed analysis of the computational and memory overhead associated with SACP. As continual learning techniques can sometimes come with increased resource requirements, it would be valuable to understand the practical implications of deploying SACP in real-world scenarios.
Overall, the research presented in this paper represents a significant contribution to the field of continual learning for large language models. The SACP method offers a promising approach to address the stability gap and could have important implications for the development of more robust and adaptable AI systems.
Conclusion
This paper introduces a novel technique called "Stability-Aware Continual Pre-Training" (SACP) to address the stability gap problem in continual pre-training of large language models (LLMs). By dynamically adjusting the learning rate, introducing a stability-aware regularization term, and using a carefully designed initialization strategy, SACP enables LLMs to efficiently update their knowledge with new data while preserving their previously acquired capabilities.
The authors' experimental results demonstrate the effectiveness of SACP, with the method outperforming traditional continual pre-training approaches on a range of benchmark tasks. This work represents an important step forward in the development of more stable and adaptable LLMs, which could have significant implications for the broader field of natural language processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
💬
Continual Learning of Large Language Models: A Comprehensive Survey
Haizhou Shi, Zihao Xu, Hengyi Wang, Weiyi Qin, Wenyuan Wang, Yibin Wang, Hao Wang
0
0
The recent success of large language models (LLMs) trained on static, pre-collected, general datasets has sparked numerous research directions and applications. One such direction addresses the non-trivial challenge of integrating pre-trained LLMs into dynamic data distributions, task structures, and user preferences. Pre-trained LLMs, when tailored for specific needs, often experience significant performance degradation in previous knowledge domains -- a phenomenon known as catastrophic forgetting. While extensively studied in the continual learning (CL) community, it presents new manifestations in the realm of LLMs. In this survey, we provide a comprehensive overview of the current research progress on LLMs within the context of CL. This survey is structured into four main sections: we first describe an overview of continually learning LLMs, consisting of two directions of continuity: vertical continuity (or vertical continual learning), i.e., continual adaptation from general to specific capabilities, and horizontal continuity (or horizontal continual learning), i.e., continual adaptation across time and domains (Section 3). We then summarize three stages of learning LLMs in the context of modern CL: Continual Pre-Training (CPT), Domain-Adaptive Pre-training (DAP), and Continual Fine-Tuning (CFT) (Section 4). Then we provide an overview of evaluation protocols for continual learning with LLMs, along with the current available data sources (Section 5). Finally, we discuss intriguing questions pertaining to continual learning for LLMs (Section 6). The full list of papers examined in this survey is available at https://github.com/Wang-ML-Lab/llm-continual-learning-survey.
4/26/2024

A Novel Paradigm Boosting Translation Capabilities of Large Language Models
Jiaxin Guo, Hao Yang, Zongyao Li, Daimeng Wei, Hengchao Shang, Xiaoyu Chen
0
0
This paper presents a study on strategies to enhance the translation capabilities of large language models (LLMs) in the context of machine translation (MT) tasks. The paper proposes a novel paradigm consisting of three stages: Secondary Pre-training using Extensive Monolingual Data, Continual Pre-training with Interlinear Text Format Documents, and Leveraging Source-Language Consistent Instruction for Supervised Fine-Tuning. Previous research on LLMs focused on various strategies for supervised fine-tuning (SFT), but their effectiveness has been limited. While traditional machine translation approaches rely on vast amounts of parallel bilingual data, our paradigm highlights the importance of using smaller sets of high-quality bilingual data. We argue that the focus should be on augmenting LLMs' cross-lingual alignment abilities during pre-training rather than solely relying on extensive bilingual data during SFT. Experimental results conducted using the Llama2 model, particularly on Chinese-Llama2 after monolingual augmentation, demonstrate the improved translation capabilities of LLMs. A significant contribution of our approach lies in Stage2: Continual Pre-training with Interlinear Text Format Documents, which requires less than 1B training data, making our method highly efficient. Additionally, in Stage3, we observed that setting instructions consistent with the source language benefits the supervised fine-tuning process. Experimental results demonstrate that our approach surpasses previous work and achieves superior performance compared to models such as NLLB-54B and GPT3.5-text-davinci-003, despite having a significantly smaller parameter count of only 7B or 13B. This achievement establishes our method as a pioneering strategy in the field of machine translation.
4/16/2024
💬
Construction of Domain-specified Japanese Large Language Model for Finance through Continual Pre-training
Masanori Hirano, Kentaro Imajo
0
0
Large language models (LLMs) are now widely used in various fields, including finance. However, Japanese financial-specific LLMs have not been proposed yet. Hence, this study aims to construct a Japanese financial-specific LLM through continual pre-training. Before tuning, we constructed Japanese financial-focused datasets for continual pre-training. As a base model, we employed a Japanese LLM that achieved state-of-the-art performance on Japanese financial benchmarks among the 10-billion-class parameter models. After continual pre-training using the datasets and the base model, the tuned model performed better than the original model on the Japanese financial benchmarks. Moreover, the outputs comparison results reveal that the tuned model's outputs tend to be better than the original model's outputs in terms of the quality and length of the answers. These findings indicate that domain-specific continual pre-training is also effective for LLMs. The tuned model is publicly available on Hugging Face.
4/17/2024
Continual Pre-Training for Cross-Lingual LLM Adaptation: Enhancing Japanese Language Capabilities
Kazuki Fujii, Taishi Nakamura, Mengsay Loem, Hiroki Iida, Masanari Ohi, Kakeru Hattori, Hirai Shota, Sakae Mizuki, Rio Yokota, Naoaki Okazaki
0
0
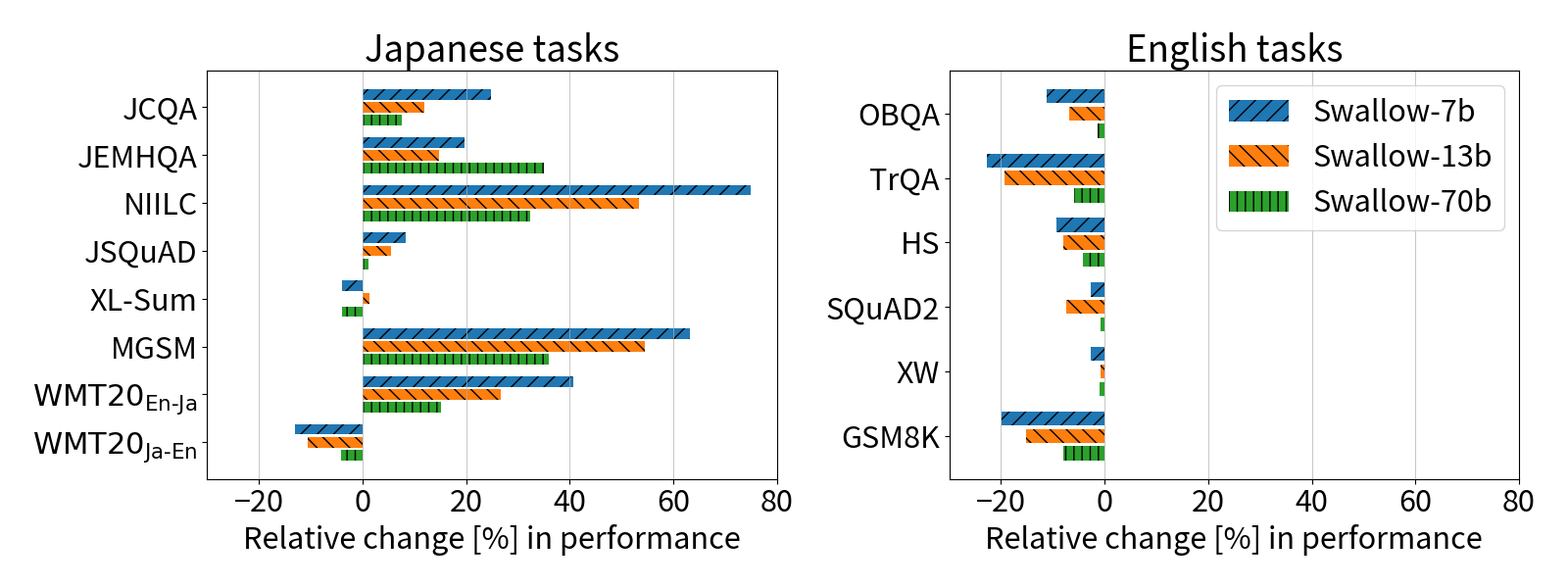
Cross-lingual continual pre-training of large language models (LLMs) initially trained on English corpus allows us to leverage the vast amount of English language resources and reduce the pre-training cost. In this study, we constructed Swallow, an LLM with enhanced Japanese capability, by extending the vocabulary of Llama 2 to include Japanese characters and conducting continual pre-training on a large Japanese web corpus. Experimental results confirmed that the performance on Japanese tasks drastically improved through continual pre-training, and the performance monotonically increased with the amount of training data up to 100B tokens. Consequently, Swallow achieved superior performance compared to other LLMs that were trained from scratch in English and Japanese. An analysis of the effects of continual pre-training revealed that it was particularly effective for Japanese question answering tasks. Furthermore, to elucidate effective methodologies for cross-lingual continual pre-training from English to Japanese, we investigated the impact of vocabulary expansion and the effectiveness of incorporating parallel corpora. The results showed that the efficiency gained through vocabulary expansion had no negative impact on performance, except for the summarization task, and that the combined use of parallel corpora enhanced translation ability.
4/30/2024