Beyond the Mean: Differentially Private Prototypes for Private Transfer Learning
2406.08039
0
0
🔄
Abstract
Machine learning (ML) models have been shown to leak private information from their training datasets. Differential Privacy (DP), typically implemented through the differential private stochastic gradient descent algorithm (DP-SGD), has become the standard solution to bound leakage from the models. Despite recent improvements, DP-SGD-based approaches for private learning still usually struggle in the high privacy ($varepsilonle1)$ and low data regimes, and when the private training datasets are imbalanced. To overcome these limitations, we propose Differentially Private Prototype Learning (DPPL) as a new paradigm for private transfer learning. DPPL leverages publicly pre-trained encoders to extract features from private data and generates DP prototypes that represent each private class in the embedding space and can be publicly released for inference. Since our DP prototypes can be obtained from only a few private training data points and without iterative noise addition, they offer high-utility predictions and strong privacy guarantees even under the notion of pure DP. We additionally show that privacy-utility trade-offs can be further improved when leveraging the public data beyond pre-training of the encoder: in particular, we can privately sample our DP prototypes from the publicly available data points used to train the encoder. Our experimental evaluation with four state-of-the-art encoders, four vision datasets, and under different data and imbalancedness regimes demonstrate DPPL's high performance under strong privacy guarantees in challenging private learning setups.
Create account to get full access
Overview
- Machine learning (ML) models can leak private information from their training datasets.
- Differential Privacy (DP), implemented through the Differentially Private Stochastic Gradient Descent (DP-SGD) algorithm, is the standard solution to bound this leakage.
- Despite improvements, DP-SGD-based approaches still struggle in high privacy, low data, and imbalanced data regimes.
- To address these limitations, the researchers propose a new paradigm called Differentially Private Prototype Learning (DPPL) for private transfer learning.
Plain English Explanation
Machine learning models can sometimes reveal sensitive information about the data used to train them, which is a problem for privacy. Differential Privacy is a technique that helps prevent this leakage, but even the latest methods have trouble when the privacy requirements are very high, the training data is limited, or the data is unbalanced.
To overcome these challenges, the researchers developed a new approach called Differentially Private Prototype Learning (DPPL). DPPL uses publicly available pre-trained models to extract features from private data and generate "prototypes" - compact representations of each class in the data. These prototypes can be shared publicly while still protecting the private training data, allowing for accurate predictions without compromising privacy.
The researchers also show that DPPL's privacy-utility tradeoffs can be further improved by using the public data used to train the original model when generating the prototypes. This helps make the prototypes more informative while still preserving privacy.
Overall, DPPL provides a new way to do private machine learning that works well even in difficult scenarios with high privacy requirements, limited data, or imbalanced datasets.
Technical Explanation
The paper introduces Differentially Private Prototype Learning (DPPL) as a new paradigm for private transfer learning. DPPL leverages publicly pre-trained encoders to extract features from private data and generates Differentially Private (DP) prototypes that represent each private class in the embedding space. These DP prototypes can be publicly released for inference while providing strong privacy guarantees.
The key advantage of DPPL is that the DP prototypes can be obtained from only a few private training data points and without iterative noise addition, unlike traditional DP-SGD approaches. This allows DPPL to achieve high-utility predictions even under the strict notion of pure DP.
The researchers also show that privacy-utility tradeoffs can be further improved by privately sampling the DP prototypes from publicly available data points used to train the original encoder. This shifted interpolation technique allows DPPL to leverage public data beyond just pre-training.
The experimental evaluation compares DPPL to state-of-the-art DP-SGD methods across four vision datasets, different data regimes, and varying levels of class imbalance. The results demonstrate DPPL's ability to achieve high performance under strong privacy guarantees, especially in challenging private learning setups.
Critical Analysis
The paper presents a promising new approach to private machine learning, but there are a few potential limitations and areas for further research:
-
The reliance on publicly pre-trained encoders may limit the applicability of DPPL to domains where such encoders are not readily available. Differentially private fine-tuning of models could be an interesting extension.
-
The paper does not explore the scalability of DPPL to larger, more complex datasets and models, such as those used in differentially private transformer models. Evaluating DPPL's performance in these settings would be valuable.
-
The privacy guarantees of DPPL rely on the strength of the pre-trained encoder and the sampling process used to generate the prototypes. Further analysis of the privacy bounds and their sensitivity to these components would provide a more complete understanding of DPPL's privacy properties.
Overall, the DPPL approach is an interesting and potentially impactful contribution to the field of private machine learning, but additional research is needed to fully assess its capabilities and limitations.
Conclusion
The paper introduces Differentially Private Prototype Learning (DPPL), a new paradigm for private transfer learning that addresses the limitations of existing Differentially Private Stochastic Gradient Descent (DP-SGD) approaches. DPPL leverages publicly pre-trained encoders to extract features from private data and generate Differentially Private prototypes that can be shared publicly while providing strong privacy guarantees.
The key advantages of DPPL are its ability to achieve high-utility predictions even under strict privacy requirements, its efficiency in using only a few private data points, and its ability to further improve privacy-utility tradeoffs by leveraging public data beyond just pre-training. The experimental results demonstrate DPPL's strong performance across a variety of datasets and privacy regimes, suggesting it as a promising direction for private machine learning research and applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Noise-Aware Differentially Private Regression via Meta-Learning
Ossi Raisa, Stratis Markou, Matthew Ashman, Wessel P. Bruinsma, Marlon Tobaben, Antti Honkela, Richard E. Turner
0
0
Many high-stakes applications require machine learning models that protect user privacy and provide well-calibrated, accurate predictions. While Differential Privacy (DP) is the gold standard for protecting user privacy, standard DP mechanisms typically significantly impair performance. One approach to mitigating this issue is pre-training models on simulated data before DP learning on the private data. In this work we go a step further, using simulated data to train a meta-learning model that combines the Convolutional Conditional Neural Process (ConvCNP) with an improved functional DP mechanism of Hall et al. [2013] yielding the DPConvCNP. DPConvCNP learns from simulated data how to map private data to a DP predictive model in one forward pass, and then provides accurate, well-calibrated predictions. We compare DPConvCNP with a DP Gaussian Process (GP) baseline with carefully tuned hyperparameters. The DPConvCNP outperforms the GP baseline, especially on non-Gaussian data, yet is much faster at test time and requires less tuning.
6/14/2024
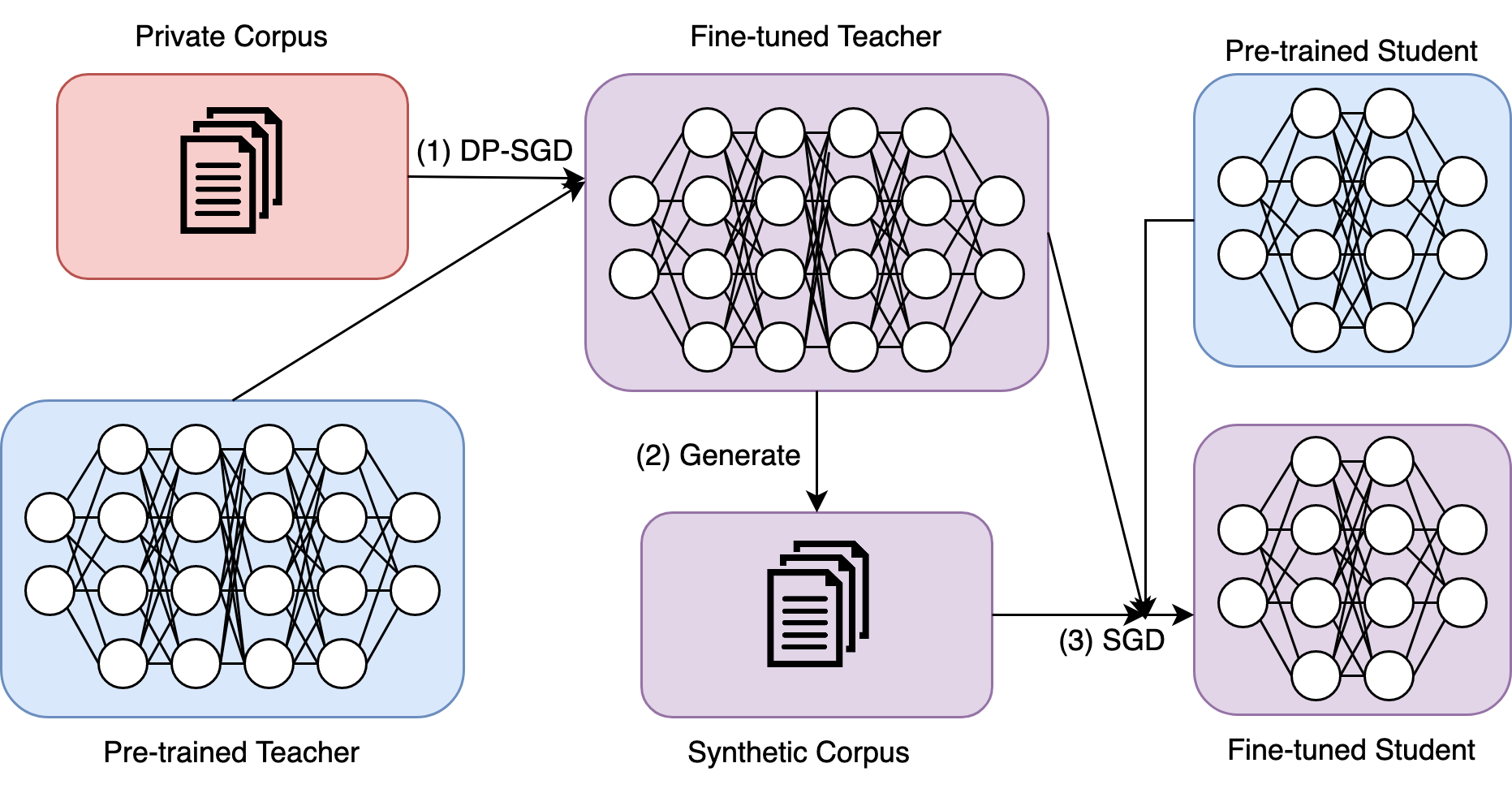
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
0
0
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
6/6/2024
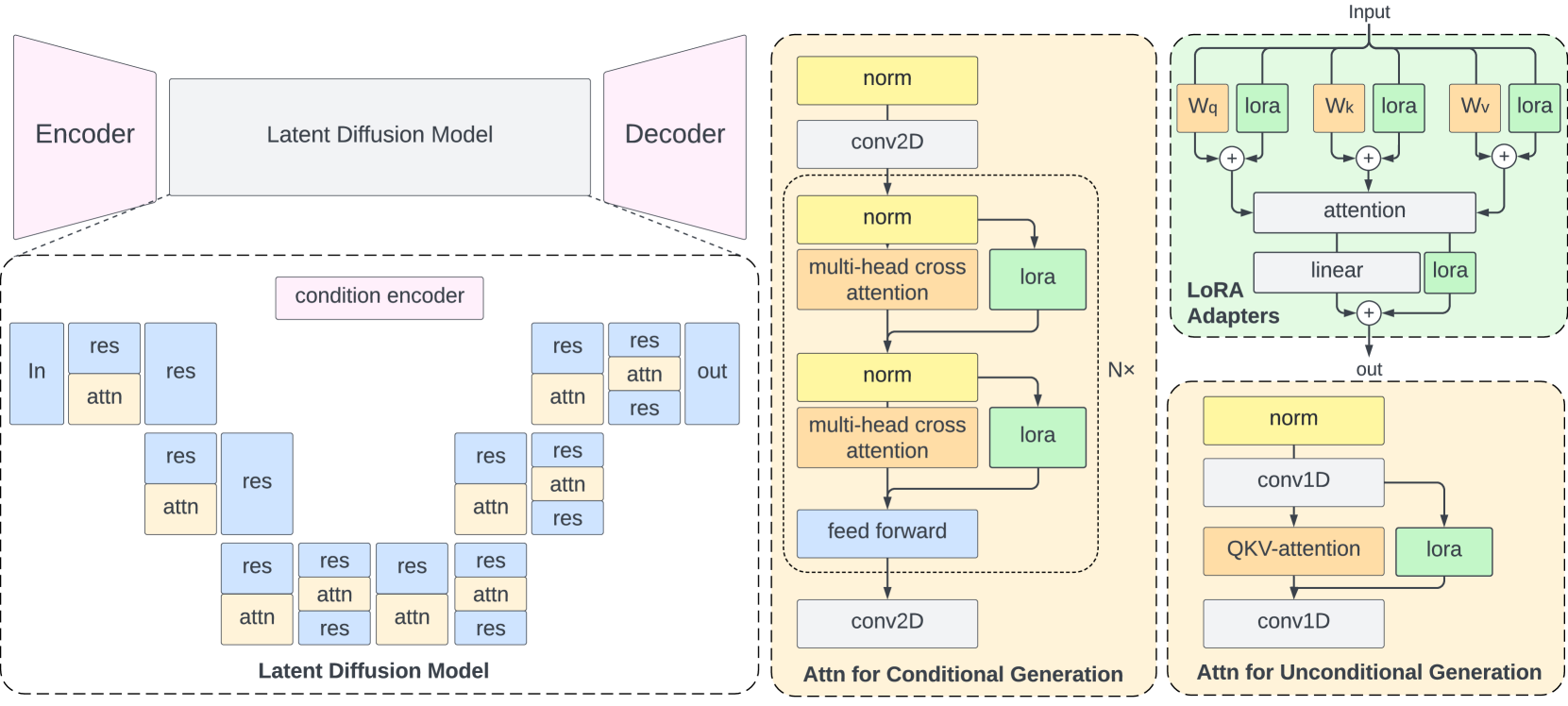
Differentially Private Fine-Tuning of Diffusion Models
Yu-Lin Tsai, Yizhe Li, Zekai Chen, Po-Yu Chen, Chia-Mu Yu, Xuebin Ren, Francois Buet-Golfouse
0
0
The integration of Differential Privacy (DP) with diffusion models (DMs) presents a promising yet challenging frontier, particularly due to the substantial memorization capabilities of DMs that pose significant privacy risks. Differential privacy offers a rigorous framework for safeguarding individual data points during model training, with Differential Privacy Stochastic Gradient Descent (DP-SGD) being a prominent implementation. Diffusion method decomposes image generation into iterative steps, theoretically aligning well with DP's incremental noise addition. Despite the natural fit, the unique architecture of DMs necessitates tailored approaches to effectively balance privacy-utility trade-off. Recent developments in this field have highlighted the potential for generating high-quality synthetic data by pre-training on public data (i.e., ImageNet) and fine-tuning on private data, however, there is a pronounced gap in research on optimizing the trade-offs involved in DP settings, particularly concerning parameter efficiency and model scalability. Our work addresses this by proposing a parameter-efficient fine-tuning strategy optimized for private diffusion models, which minimizes the number of trainable parameters to enhance the privacy-utility trade-off. We empirically demonstrate that our method achieves state-of-the-art performance in DP synthesis, significantly surpassing previous benchmarks on widely studied datasets (e.g., with only 0.47M trainable parameters, achieving a more than 35% improvement over the previous state-of-the-art with a small privacy budget on the CelebA-64 dataset). Anonymous codes available at https://anonymous.4open.science/r/DP-LORA-F02F.
6/4/2024

LazyDP: Co-Designing Algorithm-Software for Scalable Training of Differentially Private Recommendation Models
Juntaek Lim, Youngeun Kwon, Ranggi Hwang, Kiwan Maeng, G. Edward Suh, Minsoo Rhu
0
0
Differential privacy (DP) is widely being employed in the industry as a practical standard for privacy protection. While private training of computer vision or natural language processing applications has been studied extensively, the computational challenges of training of recommender systems (RecSys) with DP have not been explored. In this work, we first present our detailed characterization of private RecSys training using DP-SGD, root-causing its several performance bottlenecks. Specifically, we identify DP-SGD's noise sampling and noisy gradient update stage to suffer from a severe compute and memory bandwidth limitation, respectively, causing significant performance overhead in training private RecSys. Based on these findings, we propose LazyDP, an algorithm-software co-design that addresses the compute and memory challenges of training RecSys with DP-SGD. Compared to a state-of-the-art DP-SGD training system, we demonstrate that LazyDP provides an average 119x training throughput improvement while also ensuring mathematically equivalent, differentially private RecSys models to be trained.
4/16/2024