Delving into Differentially Private Transformer
2405.18194
0
0
✅
Abstract
Deep learning with differential privacy (DP) has garnered significant attention over the past years, leading to the development of numerous methods aimed at enhancing model accuracy and training efficiency. This paper delves into the problem of training Transformer models with differential privacy. Our treatment is modular: the logic is to reduce' the problem of training DP Transformer to the more basic problem of training DP vanilla neural nets. The latter is better understood and amenable to many model-agnostic methods. Such reduction' is done by first identifying the hardness unique to DP Transformer training: the attention distraction phenomenon and a lack of compatibility with existing techniques for efficient gradient clipping. To deal with these two issues, we propose the Re-Attention Mechanism and Phantom Clipping, respectively. We believe that our work not only casts new light on training DP Transformers but also promotes a modular treatment to advance research in the field of differentially private deep learning.
Create account to get full access
Overview
- This paper explores the challenge of training Transformer models with differential privacy (DP), a technique to protect the privacy of training data.
- The authors propose two key solutions to address the unique challenges of training DP Transformers: the Re-Attention Mechanism and Phantom Clipping.
- The paper aims to provide a modular approach to advance research in the field of differentially private deep learning.
Plain English Explanation
The paper focuses on the challenge of training a type of machine learning model called a Transformer while also protecting the privacy of the data used to train the model. Transformers are a powerful type of model that has been widely used in areas like natural language processing.
The authors identified two main issues with training Transformers with differential privacy. First, the attention mechanism in Transformers can be "distracted" by the privacy-preserving noise, reducing the model's accuracy. Second, existing techniques for efficiently clipping the gradients (a key step in the training process) don't work well with Transformers.
To address these challenges, the authors propose two new techniques:
- Re-Attention Mechanism: This helps the Transformer model focus on the right parts of the input, even with the privacy-preserving noise.
- Phantom Clipping: This is a new way to efficiently clip the gradients during Transformer training with differential privacy.
By addressing these key issues, the authors believe their work can help advance the field of training machine learning models, like Transformers, in a privacy-preserving way. This is an important area of research as machine learning models are increasingly used in applications that involve sensitive personal data.
Technical Explanation
The paper presents a modular approach to training Transformer models with differential privacy (DP). The authors first identify two key challenges unique to DP Transformer training: the attention distraction phenomenon and the lack of compatibility with existing techniques for efficient gradient clipping.
To address the attention distraction issue, the authors propose the Re-Attention Mechanism. This mechanism helps the Transformer model focus on the relevant parts of the input, even in the presence of privacy-preserving noise.
For the gradient clipping problem, the authors introduce Phantom Clipping. This is a new technique that enables efficient gradient clipping for Transformer models trained with differential privacy, overcoming the limitations of existing approaches.
The authors demonstrate the effectiveness of their solutions through experiments on various Transformer-based models, including BERT and GPT-2. The results show that their techniques can significantly improve the accuracy of DP Transformer models compared to baseline methods.
Critical Analysis
The paper provides a well-structured and comprehensive approach to the problem of training Transformer models with differential privacy. The authors' identification of the two key challenges, and their proposed solutions, are thoughtful and well-grounded in the existing literature.
One potential limitation of the work is the lack of a deeper exploration of the theoretical underpinnings of the attention distraction phenomenon and the gradient clipping incompatibility. While the authors provide intuitive explanations, a more rigorous analysis of the underlying mechanisms could strengthen the work.
Additionally, the paper could benefit from a more extensive evaluation of the proposed techniques across a wider range of Transformer-based models and tasks. This would help validate the generalizability of the authors' findings.
Finally, the authors could consider discussing potential real-world applications and implications of their research, as well as any ethical considerations that may arise from deploying DP Transformer models in sensitive domains.
Conclusion
This paper presents a modular approach to training Transformer models with differential privacy, a crucial capability as machine learning models are increasingly used in applications involving sensitive data. The authors' identification of the key challenges and their proposed solutions, the Re-Attention Mechanism and Phantom Clipping, represent important advancements in the field of differentially private deep learning.
By addressing these fundamental issues, the authors have laid the groundwork for further research and development of privacy-preserving Transformer models, with potential applications in natural language processing, task-oriented dialogue systems, and other domains where both model accuracy and data privacy are paramount.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Too Good to be True? Turn Any Model Differentially Private With DP-Weights
David Zagardo
0
0
Imagine training a machine learning model with Differentially Private Stochastic Gradient Descent (DP-SGD), only to discover post-training that the noise level was either too high, crippling your model's utility, or too low, compromising privacy. The dreaded realization hits: you must start the lengthy training process from scratch. But what if you could avoid this retraining nightmare? In this study, we introduce a groundbreaking approach (to our knowledge) that applies differential privacy noise to the model's weights after training. We offer a comprehensive mathematical proof for this novel approach's privacy bounds, use formal methods to validate its privacy guarantees, and empirically evaluate its effectiveness using membership inference attacks and performance evaluations. This method allows for a single training run, followed by post-hoc noise adjustments to achieve optimal privacy-utility trade-offs. We compare this novel fine-tuned model (DP-Weights model) to a traditional DP-SGD model, demonstrating that our approach yields statistically similar performance and privacy guarantees. Our results validate the efficacy of post-training noise application, promising significant time savings and flexibility in fine-tuning differential privacy parameters, making it a practical alternative for deploying differentially private models in real-world scenarios.
7/1/2024
🔄
Beyond the Mean: Differentially Private Prototypes for Private Transfer Learning
Dariush Wahdany, Matthew Jagielski, Adam Dziedzic, Franziska Boenisch
0
0
Machine learning (ML) models have been shown to leak private information from their training datasets. Differential Privacy (DP), typically implemented through the differential private stochastic gradient descent algorithm (DP-SGD), has become the standard solution to bound leakage from the models. Despite recent improvements, DP-SGD-based approaches for private learning still usually struggle in the high privacy ($varepsilonle1)$ and low data regimes, and when the private training datasets are imbalanced. To overcome these limitations, we propose Differentially Private Prototype Learning (DPPL) as a new paradigm for private transfer learning. DPPL leverages publicly pre-trained encoders to extract features from private data and generates DP prototypes that represent each private class in the embedding space and can be publicly released for inference. Since our DP prototypes can be obtained from only a few private training data points and without iterative noise addition, they offer high-utility predictions and strong privacy guarantees even under the notion of pure DP. We additionally show that privacy-utility trade-offs can be further improved when leveraging the public data beyond pre-training of the encoder: in particular, we can privately sample our DP prototypes from the publicly available data points used to train the encoder. Our experimental evaluation with four state-of-the-art encoders, four vision datasets, and under different data and imbalancedness regimes demonstrate DPPL's high performance under strong privacy guarantees in challenging private learning setups.
6/13/2024
🏷️
DP-DyLoRA: Fine-Tuning Transformer-Based Models On-Device under Differentially Private Federated Learning using Dynamic Low-Rank Adaptation
Jie Xu, Karthikeyan Saravanan, Rogier van Dalen, Haaris Mehmood, David Tuckey, Mete Ozay
0
0
Federated learning (FL) allows clients in an Internet of Things (IoT) system to collaboratively train a global model without sharing their local data with a server. However, clients' contributions to the server can still leak sensitive information. Differential privacy (DP) addresses such leakage by providing formal privacy guarantees, with mechanisms that add randomness to the clients' contributions. The randomness makes it infeasible to train large transformer-based models, common in modern IoT systems. In this work, we empirically evaluate the practicality of fine-tuning large scale on-device transformer-based models with differential privacy in a federated learning system. We conduct comprehensive experiments on various system properties for tasks spanning a multitude of domains: speech recognition, computer vision (CV) and natural language understanding (NLU). Our results show that full fine-tuning under differentially private federated learning (DP-FL) generally leads to huge performance degradation which can be alleviated by reducing the dimensionality of contributions through parameter-efficient fine-tuning (PEFT). Our benchmarks of existing DP-PEFT methods show that DP-Low-Rank Adaptation (DP-LoRA) consistently outperforms other methods. An even more promising approach, DyLoRA, which makes the low rank variable, when naively combined with FL would straightforwardly break differential privacy. We therefore propose an adaptation method that can be combined with differential privacy and call it DP-DyLoRA. Finally, we are able to reduce the accuracy degradation and word error rate (WER) increase due to DP to less than 2% and 7% respectively with 1 million clients and a stringent privacy budget of {epsilon}=2.
5/29/2024
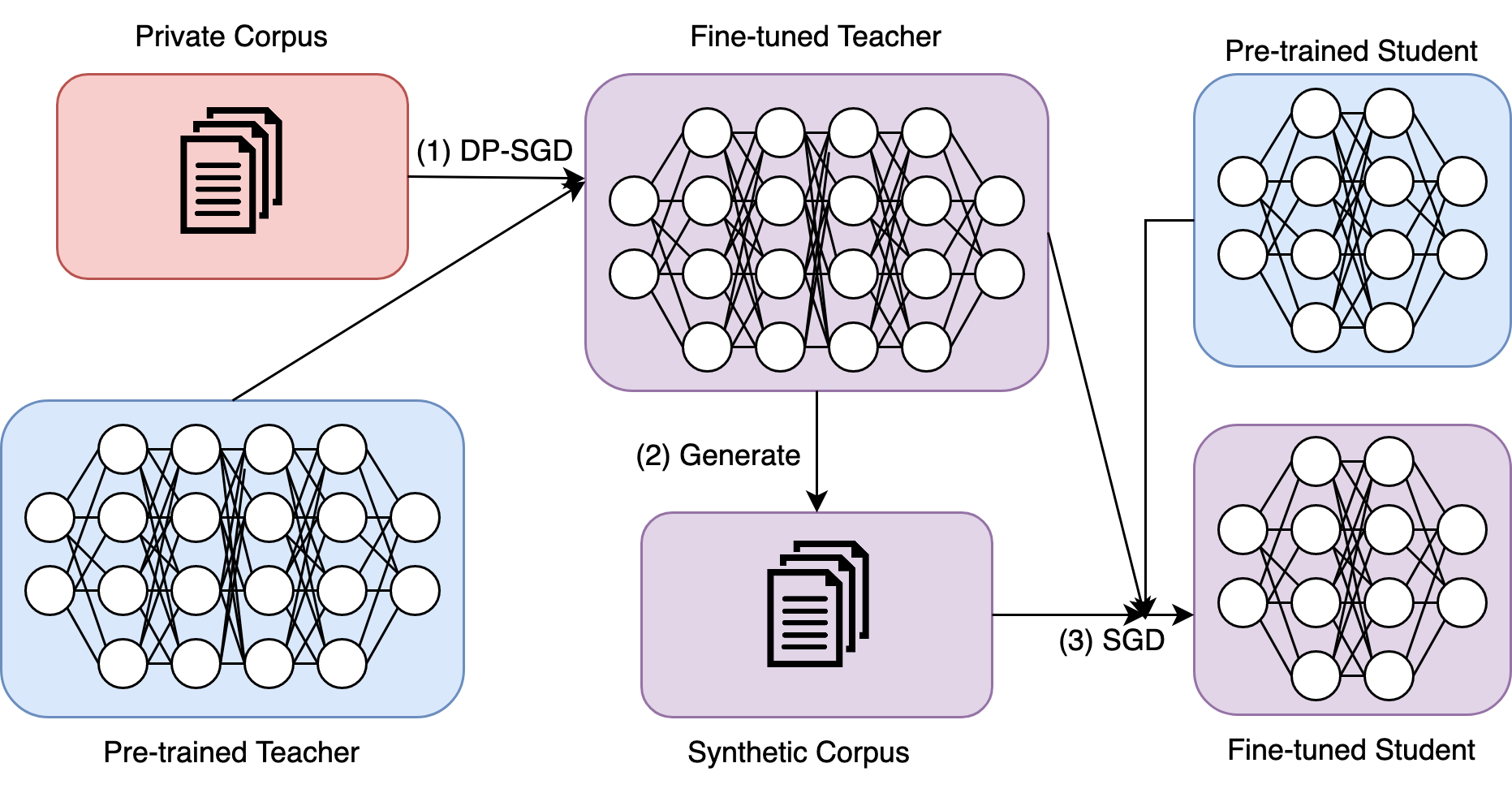
Differentially Private Knowledge Distillation via Synthetic Text Generation
James Flemings, Murali Annavaram
0
0
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
6/6/2024