Differentially Private Knowledge Distillation via Synthetic Text Generation
2403.00932
0
0
Abstract
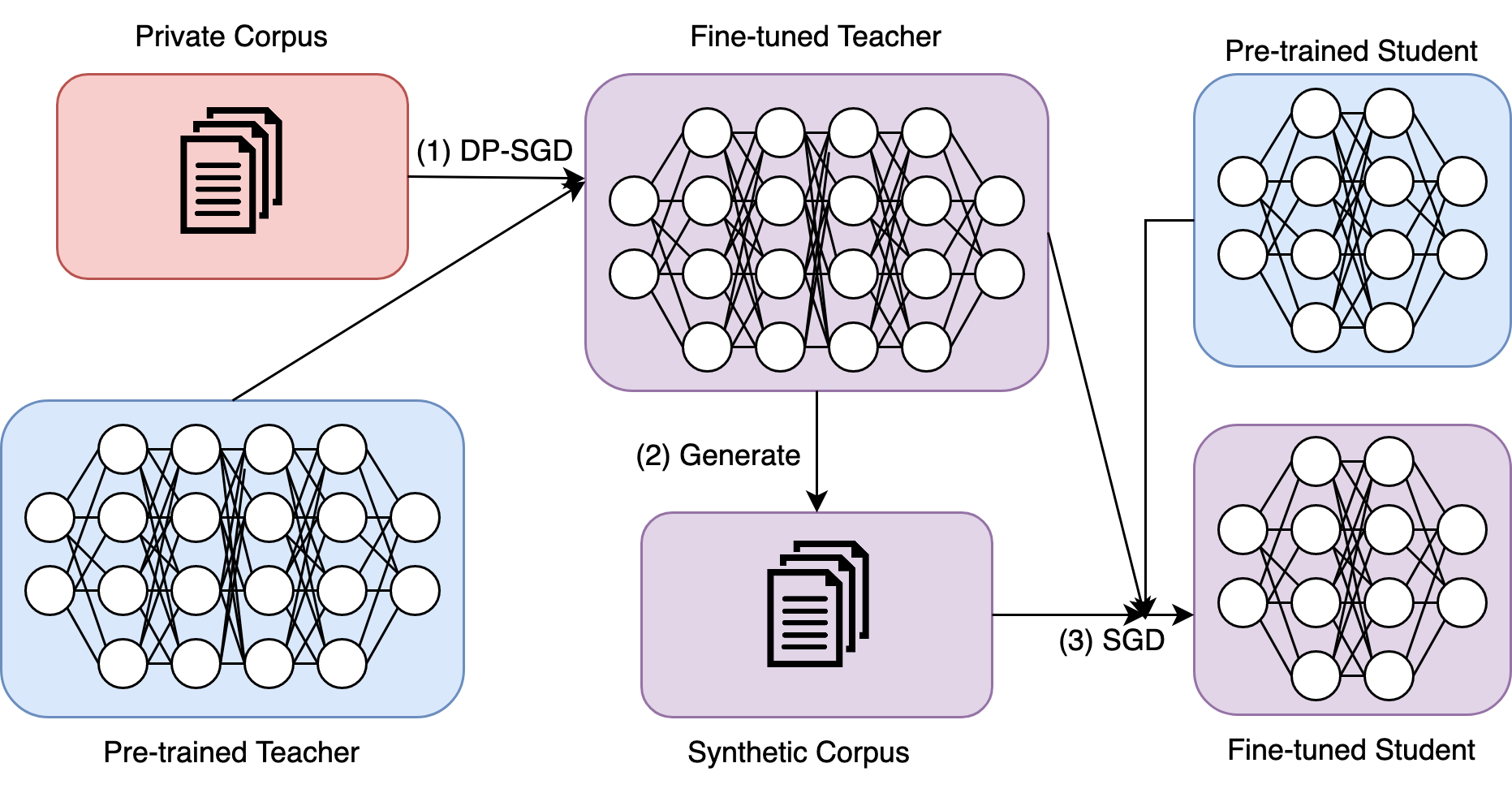
Large Language models (LLMs) are achieving state-of-the-art performance in many different downstream tasks. However, the increasing urgency of data privacy puts pressure on practitioners to train LLMs with Differential Privacy (DP) on private data. Concurrently, the exponential growth in parameter size of LLMs necessitates model compression before deployment of LLMs on resource-constrained devices or latency-sensitive applications. Differential privacy and model compression generally must trade off utility loss to achieve their objectives. Moreover, simultaneously applying both schemes can compound the utility degradation. To this end, we propose DistilDP: a novel differentially private knowledge distillation algorithm that exploits synthetic data generated by a differentially private teacher LLM. The knowledge of a teacher LLM is transferred onto the student in two ways: one way from the synthetic data itself -- the hard labels, and the other way by the output distribution of the teacher evaluated on the synthetic data -- the soft labels. Furthermore, if the teacher and student share a similar architectural structure, we can further distill knowledge by aligning the hidden representations between both. Our experimental results demonstrate that DistilDP can substantially improve the utility over existing baselines, at least $9.0$ PPL on the Big Patent dataset, with strong privacy parameters, $epsilon=2$. These promising results progress privacy-preserving compression of autoregressive LLMs. Our code can be accessed here: https://github.com/james-flemings/dp_compress.
Create account to get full access
Overview
- This paper introduces a novel approach for differentially private knowledge distillation using synthetic text generation.
- The key idea is to generate synthetic text samples that capture the knowledge of a larger "teacher" model, while preserving the privacy of the original training data.
- The authors present a framework that combines language models, differential privacy, and knowledge distillation to train a smaller "student" model in a privacy-preserving manner.
Plain English Explanation
The paper describes a way to train a smaller machine learning model to mimic the behavior of a larger, more complex model, while protecting the privacy of the data used to train the original model. This is done by generating synthetic text samples that capture the knowledge of the larger "teacher" model, without needing to access the original training data.
The approach uses differentially private tabular data synthesis and differentially private fine-tuning of diffusion models to create these synthetic text samples, and then applies knowledge distillation to train the smaller "student" model. This allows the student model to learn the important patterns and behaviors of the teacher model, without directly accessing the sensitive training data.
The key benefit of this approach is that it enables the deployment of smaller, more efficient models that still maintain the performance of larger, more complex models, while preserving the privacy of the original data. This can be particularly useful in applications where data privacy is a critical concern, such as in healthcare or financial services.
Technical Explanation
The paper proposes a framework for differentially private knowledge distillation using synthetic text generation. The core idea is to generate synthetic text samples that capture the knowledge of a larger "teacher" model, and then use these samples to train a smaller "student" model.
The framework consists of three main components:
-
Differentially Private Text Generation: The authors use a differentially private language model to generate synthetic text samples that preserve the statistical properties of the original training data, while providing strong privacy guarantees. This is achieved through techniques like differentially private next-token prediction and differentially private fine-tuning of diffusion models.
-
Knowledge Distillation: The synthetic text samples generated in the first step are used to train the smaller student model, using a knowledge distillation approach. This allows the student model to learn the important patterns and behaviors of the teacher model, without directly accessing the original training data.
-
Differential Privacy Analysis: The authors provide a theoretical analysis of the privacy guarantees of their framework, showing that it satisfies differential privacy and can offer strong privacy protections for the original training data.
The paper demonstrates the effectiveness of this approach through experiments on various datasets and tasks, showing that the student model can achieve competitive performance compared to the teacher model, while preserving the privacy of the original data.
Critical Analysis
The paper presents a promising approach for differentially private knowledge distillation, but there are a few potential limitations and areas for further research:
- The paper focuses on text-based tasks, and it's not clear how well the approach would generalize to other domains, such as image or audio data.
- The authors do not explore the impact of the quality of the synthetic text samples on the final performance of the student model. Further research is needed to understand the trade-offs between privacy and model performance.
- The theoretical analysis of the privacy guarantees is based on a simplified setting, and more realistic scenarios with complex data distributions and adversaries may require additional considerations.
- The paper does not provide a detailed comparison with other privacy-preserving machine learning techniques, such as LMO-DP, which could offer different trade-offs between privacy and performance.
Overall, the paper presents an interesting and potentially valuable approach to differentially private knowledge distillation, but more research is needed to fully understand its practical implications and limitations.
Conclusion
This paper introduces a novel framework for differentially private knowledge distillation using synthetic text generation. The key idea is to generate synthetic text samples that capture the knowledge of a larger "teacher" model, and then use these samples to train a smaller "student" model in a privacy-preserving manner.
The proposed approach combines techniques from language modeling, differential privacy, and knowledge distillation to enable the deployment of efficient, high-performing models while preserving the privacy of the original training data. This can be particularly useful in applications where data privacy is a critical concern, such as in healthcare or financial services.
While the paper focuses on text-based tasks, the underlying principles could potentially be extended to other domains, making it an important contribution to the field of privacy-preserving machine learning.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛸
Synthetic Query Generation for Privacy-Preserving Deep Retrieval Systems using Differentially Private Language Models
Aldo Gael Carranza, Rezsa Farahani, Natalia Ponomareva, Alex Kurakin, Matthew Jagielski, Milad Nasr
0
0
We address the challenge of ensuring differential privacy (DP) guarantees in training deep retrieval systems. Training these systems often involves the use of contrastive-style losses, which are typically non-per-example decomposable, making them difficult to directly DP-train with since common techniques require per-example gradients. To address this issue, we propose an approach that prioritizes ensuring query privacy prior to training a deep retrieval system. Our method employs DP language models (LMs) to generate private synthetic queries representative of the original data. These synthetic queries can be used in downstream retrieval system training without compromising privacy. Our approach demonstrates a significant enhancement in retrieval quality compared to direct DP-training, all while maintaining query-level privacy guarantees. This work highlights the potential of harnessing LMs to overcome limitations in standard DP-training methods.
5/24/2024
Differentially Private Tabular Data Synthesis using Large Language Models
Toan V. Tran, Li Xiong
0
0
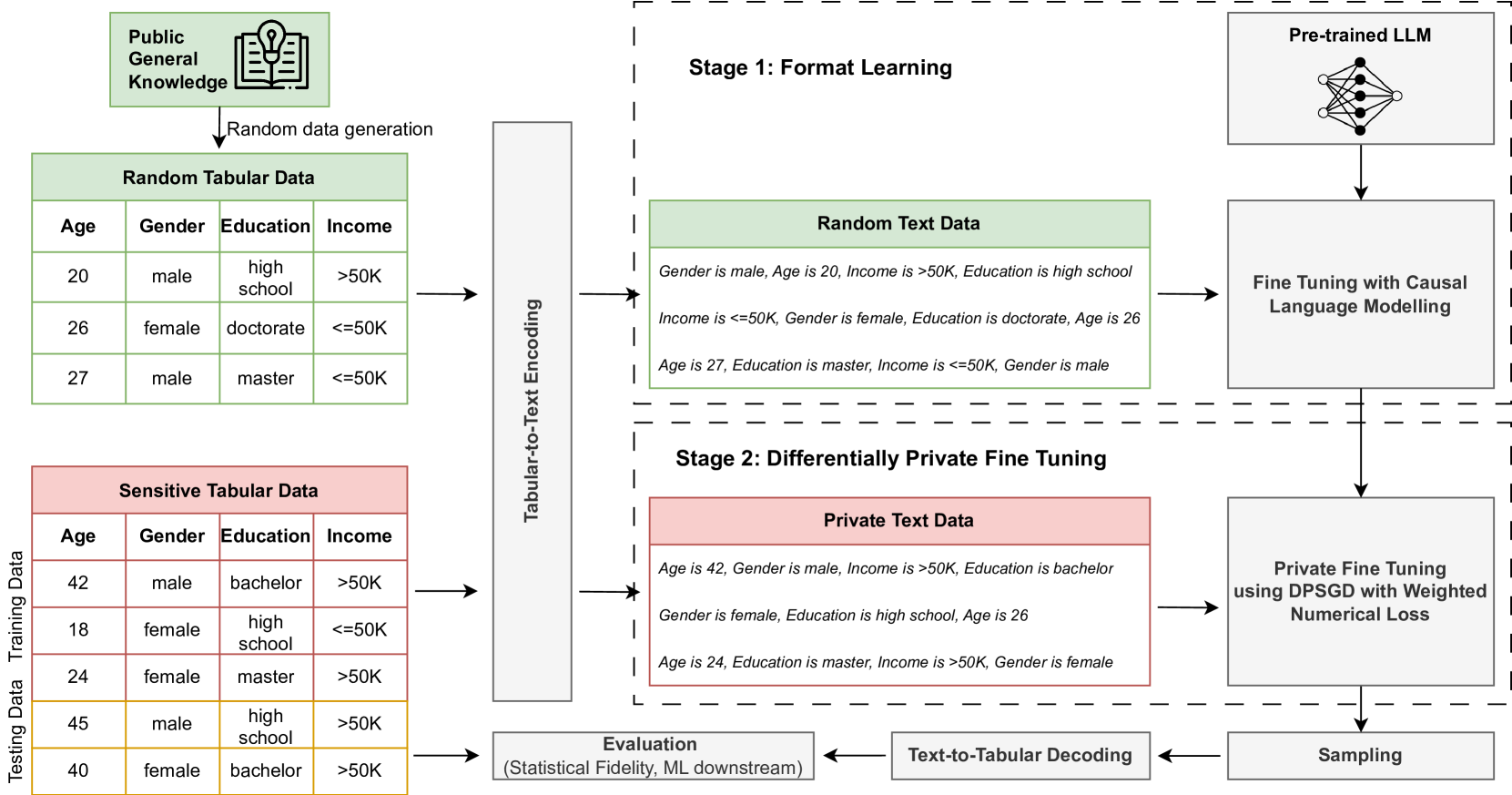
Synthetic tabular data generation with differential privacy is a crucial problem to enable data sharing with formal privacy. Despite a rich history of methodological research and development, developing differentially private tabular data generators that can provide realistic synthetic datasets remains challenging. This paper introduces DP-LLMTGen -- a novel framework for differentially private tabular data synthesis that leverages pretrained large language models (LLMs). DP-LLMTGen models sensitive datasets using a two-stage fine-tuning procedure with a novel loss function specifically designed for tabular data. Subsequently, it generates synthetic data through sampling the fine-tuned LLMs. Our empirical evaluation demonstrates that DP-LLMTGen outperforms a variety of existing mechanisms across multiple datasets and privacy settings. Additionally, we conduct an ablation study and several experimental analyses to deepen our understanding of LLMs in addressing this important problem. Finally, we highlight the controllable generation ability of DP-LLMTGen through a fairness-constrained generation setting.
6/4/2024
Differentially Private Fine-Tuning of Diffusion Models
Yu-Lin Tsai, Yizhe Li, Zekai Chen, Po-Yu Chen, Chia-Mu Yu, Xuebin Ren, Francois Buet-Golfouse
0
0
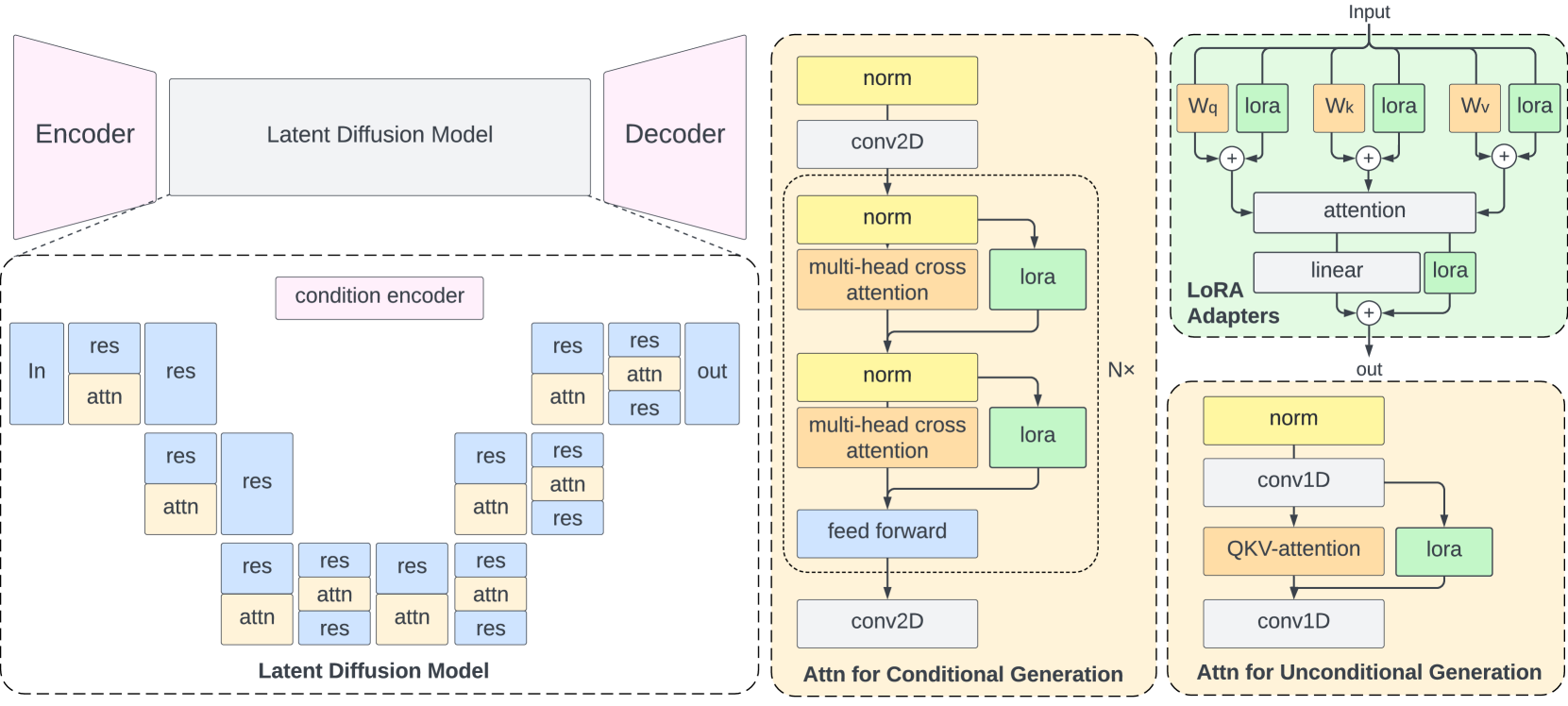
The integration of Differential Privacy (DP) with diffusion models (DMs) presents a promising yet challenging frontier, particularly due to the substantial memorization capabilities of DMs that pose significant privacy risks. Differential privacy offers a rigorous framework for safeguarding individual data points during model training, with Differential Privacy Stochastic Gradient Descent (DP-SGD) being a prominent implementation. Diffusion method decomposes image generation into iterative steps, theoretically aligning well with DP's incremental noise addition. Despite the natural fit, the unique architecture of DMs necessitates tailored approaches to effectively balance privacy-utility trade-off. Recent developments in this field have highlighted the potential for generating high-quality synthetic data by pre-training on public data (i.e., ImageNet) and fine-tuning on private data, however, there is a pronounced gap in research on optimizing the trade-offs involved in DP settings, particularly concerning parameter efficiency and model scalability. Our work addresses this by proposing a parameter-efficient fine-tuning strategy optimized for private diffusion models, which minimizes the number of trainable parameters to enhance the privacy-utility trade-off. We empirically demonstrate that our method achieves state-of-the-art performance in DP synthesis, significantly surpassing previous benchmarks on widely studied datasets (e.g., with only 0.47M trainable parameters, achieving a more than 35% improvement over the previous state-of-the-art with a small privacy budget on the CelebA-64 dataset). Anonymous codes available at https://anonymous.4open.science/r/DP-LORA-F02F.
6/4/2024
🔄
Beyond the Mean: Differentially Private Prototypes for Private Transfer Learning
Dariush Wahdany, Matthew Jagielski, Adam Dziedzic, Franziska Boenisch
0
0
Machine learning (ML) models have been shown to leak private information from their training datasets. Differential Privacy (DP), typically implemented through the differential private stochastic gradient descent algorithm (DP-SGD), has become the standard solution to bound leakage from the models. Despite recent improvements, DP-SGD-based approaches for private learning still usually struggle in the high privacy ($varepsilonle1)$ and low data regimes, and when the private training datasets are imbalanced. To overcome these limitations, we propose Differentially Private Prototype Learning (DPPL) as a new paradigm for private transfer learning. DPPL leverages publicly pre-trained encoders to extract features from private data and generates DP prototypes that represent each private class in the embedding space and can be publicly released for inference. Since our DP prototypes can be obtained from only a few private training data points and without iterative noise addition, they offer high-utility predictions and strong privacy guarantees even under the notion of pure DP. We additionally show that privacy-utility trade-offs can be further improved when leveraging the public data beyond pre-training of the encoder: in particular, we can privately sample our DP prototypes from the publicly available data points used to train the encoder. Our experimental evaluation with four state-of-the-art encoders, four vision datasets, and under different data and imbalancedness regimes demonstrate DPPL's high performance under strong privacy guarantees in challenging private learning setups.
6/13/2024