Beyond Spatial Explanations: Explainable Face Recognition in the Frequency Domain

0

Sign in to get full access
Overview
- This paper explores a novel approach to explain how deep learning models for face recognition make their predictions, moving beyond traditional spatial-based explanations.
- The researchers present a frequency-domain explainability method that can identify the specific frequency bands that a model uses to recognize faces.
- This work aims to provide a more comprehensive understanding of the inner workings of these models and potentially lead to improved model interpretability and robustness.
Plain English Explanation
Deep learning models have become highly accurate at recognizing faces in images, but it's often unclear how they arrive at their predictions. Traditionally, researchers have tried to explain these models by looking at the specific pixels or spatial regions that influence their decisions. However, this paper takes a different approach, focusing on the frequency domain rather than the spatial domain.
The key insight is that faces contain information across a wide range of frequencies, from low-level features like edges to high-level features like facial structure. By analyzing which frequency bands a model pays attention to, the researchers can gain a deeper understanding of how it recognizes faces. This frequency-domain explainability method could lead to models that are more interpretable and robust, as we can identify the specific frequency information they are relying on.
For example, a model might primarily use low-frequency information to recognize basic facial features, while using higher frequencies to pick up on more subtle details. Knowing this can help us understand the model's strengths and weaknesses, and potentially improve its performance by focusing on the most informative frequency bands.
Overall, this research represents a promising step towards a more comprehensive visual saliency explanation framework for face recognition, moving beyond traditional spatial-based approaches and shedding new light on how these powerful models work under the hood.
Technical Explanation
The key innovation in this paper is the use of a frequency-domain explainability method to understand how deep learning models for face recognition make their predictions. Rather than focusing on the specific pixels or spatial regions that influence a model's decision, as is common in spatial-based explanation techniques, the authors explore the model's reliance on different frequency bands.
To do this, they first trained a state-of-the-art face recognition model using standard techniques. They then developed a frequency-domain explanation method that involves applying selective frequency masking to the input image and measuring the impact on the model's predictions. By systematically masking different frequency bands, they could identify which ones the model relies on most heavily for face recognition.
The experiments revealed that models tend to use a combination of low, mid, and high-frequency information to recognize faces, with the specific frequency bands varying depending on the task and dataset. Importantly, the frequency-based explanations provided additional insights beyond what could be gleaned from spatial-based techniques alone, suggesting that this approach offers a more comprehensive understanding of model behavior.
Furthermore, the researchers demonstrated that the frequency-domain explanations could be used to enhance deepfake detection by identifying the frequency bands that are most affected by manipulation. This highlights the potential for frequency-domain explainability to improve the interpretability and robustness of face recognition systems.
Critical Analysis
One limitation of this work is that the frequency-domain explainability method was only tested on a single face recognition model and dataset. It would be valuable to see how the technique performs across a wider range of models and tasks to assess its generalizability. Additionally, the paper does not provide a detailed comparison to existing spatial-based explanation methods, making it difficult to evaluate the relative merits of the frequency-domain approach.
Another potential concern is the computational complexity of the frequency masking process, which could limit the scalability of the technique, especially for larger input images or more complex models. The authors acknowledge this issue and suggest that future work should explore ways to make the method more efficient.
Finally, while the frequency-domain explanations provide valuable insights into model behavior, it's not yet clear how this information could be used to directly improve model performance or robustness. Further research is needed to explore the practical applications of this approach and its potential impact on the development of more interpretable and trustworthy face recognition systems.
Conclusion
This paper presents a novel frequency-domain explainability method for understanding how deep learning models for face recognition make their predictions. By analyzing the specific frequency bands that a model relies on, the researchers were able to gain a more comprehensive understanding of its inner workings, going beyond traditional spatial-based explanation techniques.
The key contribution of this work is the demonstration that frequency-domain analysis can offer unique insights that complement existing explanation methods. This has the potential to lead to more interpretable and robust face recognition systems, as we can better identify the strengths and weaknesses of these models and potentially optimize their performance by focusing on the most informative frequency bands.
While further research is needed to fully realize the benefits of this approach, this paper represents an important step forward in the field of explainable AI for computer vision applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Beyond Spatial Explanations: Explainable Face Recognition in the Frequency Domain
Marco Huber, Naser Damer
The need for more transparent face recognition (FR), along with other visual-based decision-making systems has recently attracted more attention in research, society, and industry. The reasons why two face images are matched or not matched by a deep learning-based face recognition system are not obvious due to the high number of parameters and the complexity of the models. However, it is important for users, operators, and developers to ensure trust and accountability of the system and to analyze drawbacks such as biased behavior. While many previous works use spatial semantic maps to highlight the regions that have a significant influence on the decision of the face recognition system, frequency components which are also considered by CNNs, are neglected. In this work, we take a step forward and investigate explainable face recognition in the unexplored frequency domain. This makes this work the first to propose explainability of verification-based decisions in the frequency domain, thus explaining the relative influence of the frequency components of each input toward the obtained outcome. To achieve this, we manipulate face images in the spatial frequency domain and investigate the impact on verification outcomes. In extensive quantitative experiments, along with investigating two special scenarios cases, cross-resolution FR and morphing attacks (the latter in supplementary material), we observe the applicability of our proposed frequency-based explanations.
Read more7/17/2024
🤷
0
Spatial-Frequency Discriminability for Revealing Adversarial Perturbations
Chao Wang, Shuren Qi, Zhiqiu Huang, Yushu Zhang, Rushi Lan, Xiaochun Cao, Feng-Lei Fan
The vulnerability of deep neural networks to adversarial perturbations has been widely perceived in the computer vision community. From a security perspective, it poses a critical risk for modern vision systems, e.g., the popular Deep Learning as a Service (DLaaS) frameworks. For protecting deep models while not modifying them, current algorithms typically detect adversarial patterns through discriminative decomposition for natural and adversarial data. However, these decompositions are either biased towards frequency resolution or spatial resolution, thus failing to capture adversarial patterns comprehensively. Also, when the detector relies on few fixed features, it is practical for an adversary to fool the model while evading the detector (i.e., defense-aware attack). Motivated by such facts, we propose a discriminative detector relying on a spatial-frequency Krawtchouk decomposition. It expands the above works from two aspects: 1) the introduced Krawtchouk basis provides better spatial-frequency discriminability, capturing the differences between natural and adversarial data comprehensively in both spatial and frequency distributions, w.r.t. the common trigonometric or wavelet basis; 2) the extensive features formed by the Krawtchouk decomposition allows for adaptive feature selection and secrecy mechanism, significantly increasing the difficulty of the defense-aware attack, w.r.t. the detector with few fixed features. Theoretical and numerical analyses demonstrate the uniqueness and usefulness of our detector, exhibiting competitive scores on several deep models and image sets against a variety of adversarial attacks.
Read more8/9/2024

0
Explaining time series models using frequency masking
Thea Brusch, Kristoffer K. Wickstr{o}m, Mikkel N. Schmidt, Tommy S. Alstr{o}m, Robert Jenssen
Time series data is fundamentally important for describing many critical domains such as healthcare, finance, and climate, where explainable models are necessary for safe automated decision-making. To develop eXplainable AI (XAI) in these domains therefore implies explaining salient information in the time series. Current methods for obtaining saliency maps assumes localized information in the raw input space. In this paper, we argue that the salient information of a number of time series is more likely to be localized in the frequency domain. We propose FreqRISE, which uses masking based methods to produce explanations in the frequency and time-frequency domain, which shows the best performance across a number of tasks.
Read more6/21/2024
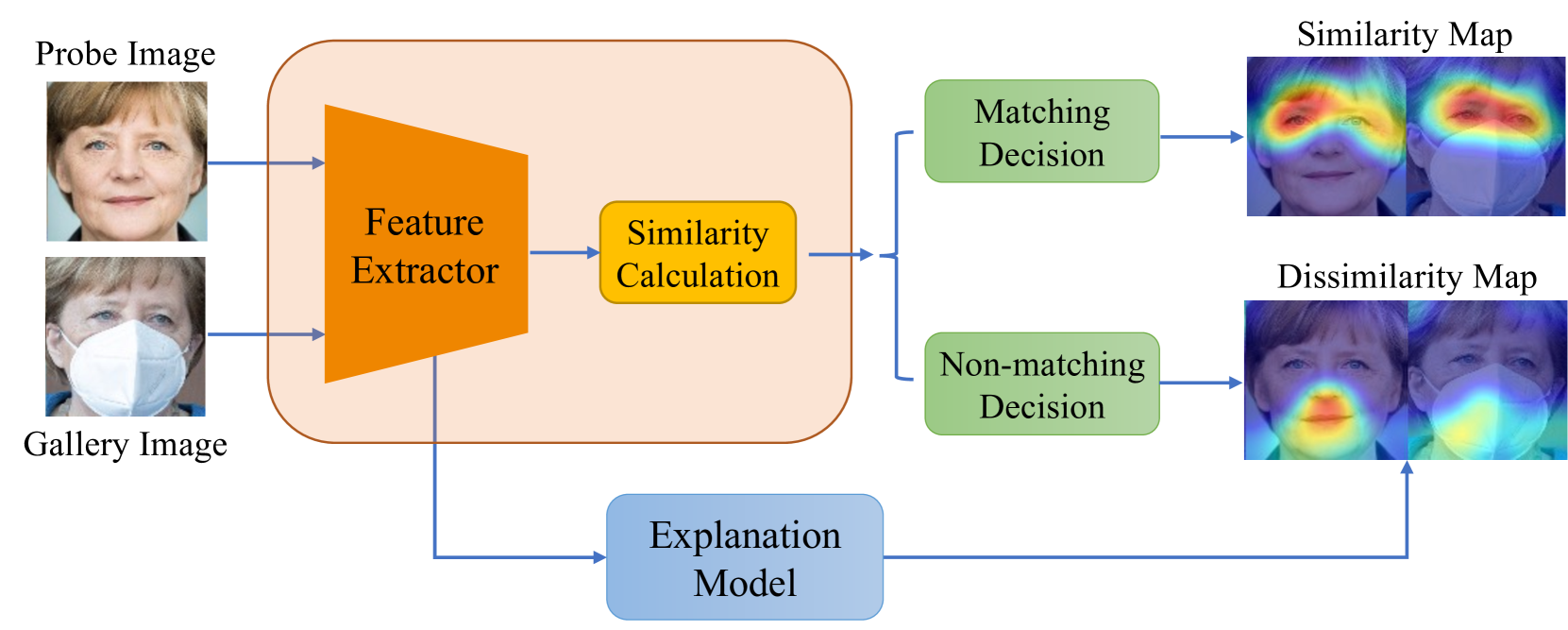
0
Towards A Comprehensive Visual Saliency Explanation Framework for AI-based Face Recognition Systems
Yuhang Lu, Zewei Xu, Touradj Ebrahimi
Over recent years, deep convolutional neural networks have significantly advanced the field of face recognition techniques for both verification and identification purposes. Despite the impressive accuracy, these neural networks are often criticized for lacking explainability. There is a growing demand for understanding the decision-making process of AI-based face recognition systems. Some studies have investigated the use of visual saliency maps as explanations, but they have predominantly focused on the specific face verification case. The discussion on more general face recognition scenarios and the corresponding evaluation methodology for these explanations have long been absent in current research. Therefore, this manuscript conceives a comprehensive explanation framework for face recognition tasks. Firstly, an exhaustive definition of visual saliency map-based explanations for AI-based face recognition systems is provided, taking into account the two most common recognition situations individually, i.e., face verification and identification. Secondly, a new model-agnostic explanation method named CorrRISE is proposed to produce saliency maps, which reveal both the similar and dissimilar regions between any given face images. Subsequently, the explanation framework conceives a new evaluation methodology that offers quantitative measurement and comparison of the performance of general visual saliency explanation methods in face recognition. Consequently, extensive experiments are carried out on multiple verification and identification scenarios. The results showcase that CorrRISE generates insightful saliency maps and demonstrates superior performance, particularly in similarity maps in comparison with the state-of-the-art explanation approaches.
Read more7/9/2024