Bi-Level Spatial and Channel-aware Transformer for Learned Image Compression

0

Sign in to get full access
Overview
- The paper proposes a Bi-Level Spatial and Channel-aware Transformer (BLSCT) for learned image compression.
- The key ideas are:
- Using a transformer architecture with spatial and channel-wise attention to capture both spatial and channel-level information.
- Incorporating a bi-level hierarchy to enable efficient feature extraction and reconstruction.
- Demonstrating improvements in compression performance compared to existing learned image compression methods.
Plain English Explanation
The paper introduces a new technique for compressing images called the Bi-Level Spatial and Channel-aware Transformer (BLSCT). The goal of image compression is to reduce the file size of an image while still maintaining high quality.
The core idea behind BLSCT is to use a type of machine learning model called a transformer to capture both the spatial (location-based) and channel-wise (feature-based) information in the image. Transformers are good at understanding the relationships between different parts of an image.
BLSCT also has a bi-level hierarchy, which means it has two interconnected levels that work together. This allows it to efficiently extract and reconstruct the important features of the image.
By using this spatial and channel-aware transformer approach, the authors show that BLSCT can outperform other state-of-the-art image compression techniques. This means the compressed images maintain higher quality at smaller file sizes.
Technical Explanation
The key technical components of the Bi-Level Spatial and Channel-aware Transformer (BLSCT) are:
-
Spatial and Channel-wise Attention: The transformer architecture in BLSCT uses attention mechanisms to capture both spatial relationships between different image regions as well as channel-wise dependencies between different visual features.
-
Bi-Level Hierarchy: BLSCT has two interconnected levels - a shallow level that efficiently extracts coarse features, and a deeper level that reconstructs the final high-quality image from these features.
-
Encoder-Decoder Structure: The transformer is implemented as an encoder-decoder structure, where the encoder learns a compact feature representation and the decoder reconstructs the final image.
-
Progressive Decoding: BLSCT uses a progressive decoding approach, where the image is reconstructed in multiple steps by gradually adding more details.
The authors evaluate BLSCT on standard image compression benchmarks and show that it outperforms previous state-of-the-art learned image compression methods in terms of rate-distortion performance.
Critical Analysis
The paper presents a well-designed and effective approach to learned image compression. Some potential areas for further research and improvement include:
-
Computational Complexity: While the bi-level hierarchy helps with efficiency, the overall computational cost of the transformer-based model may still be higher compared to some traditional compression methods. Exploring ways to further optimize the model's inference speed would be valuable.
-
Generalization to Other Domains: The evaluation in the paper is focused on natural images. It would be interesting to see how well BLSCT generalizes to other image domains, such as medical or satellite imagery, which may have different characteristics.
-
Interpretability: As with many deep learning models, the internal workings of BLSCT may be difficult to interpret. Providing more insights into how the spatial and channel-wise attention mechanisms contribute to the final compression performance could enhance the understanding of the model's behavior.
-
Handling Diverse Content: The paper does not explicitly address how BLSCT might handle a wide range of image content, such as text-heavy documents or graphics-intensive images. Exploring the model's robustness to diverse image types could be a fruitful area of investigation.
Overall, the Bi-Level Spatial and Channel-aware Transformer is a promising advancement in learned image compression and demonstrates the value of incorporating transformer-based architectures in this domain.
Conclusion
The Bi-Level Spatial and Channel-aware Transformer (BLSCT) proposed in this paper represents an innovative approach to learned image compression. By leveraging a transformer architecture with spatial and channel-wise attention, as well as a bi-level hierarchy, BLSCT is able to outperform existing state-of-the-art methods in terms of rate-distortion performance.
This work highlights the potential of transformer-based models in the field of image compression, which has traditionally been dominated by convolutional neural networks. The ability to capture both spatial and channel-level information effectively can lead to more efficient and higher-quality image representations.
While the paper presents a compelling solution, there are still opportunities for further research and improvements, such as addressing computational complexity, exploring generalization to diverse image domains, and enhancing the interpretability of the model. Overall, the BLSCT approach is a significant contribution to the ongoing efforts in developing advanced learned image compression techniques.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Bi-Level Spatial and Channel-aware Transformer for Learned Image Compression
Hamidreza Soltani, Erfan Ghasemi
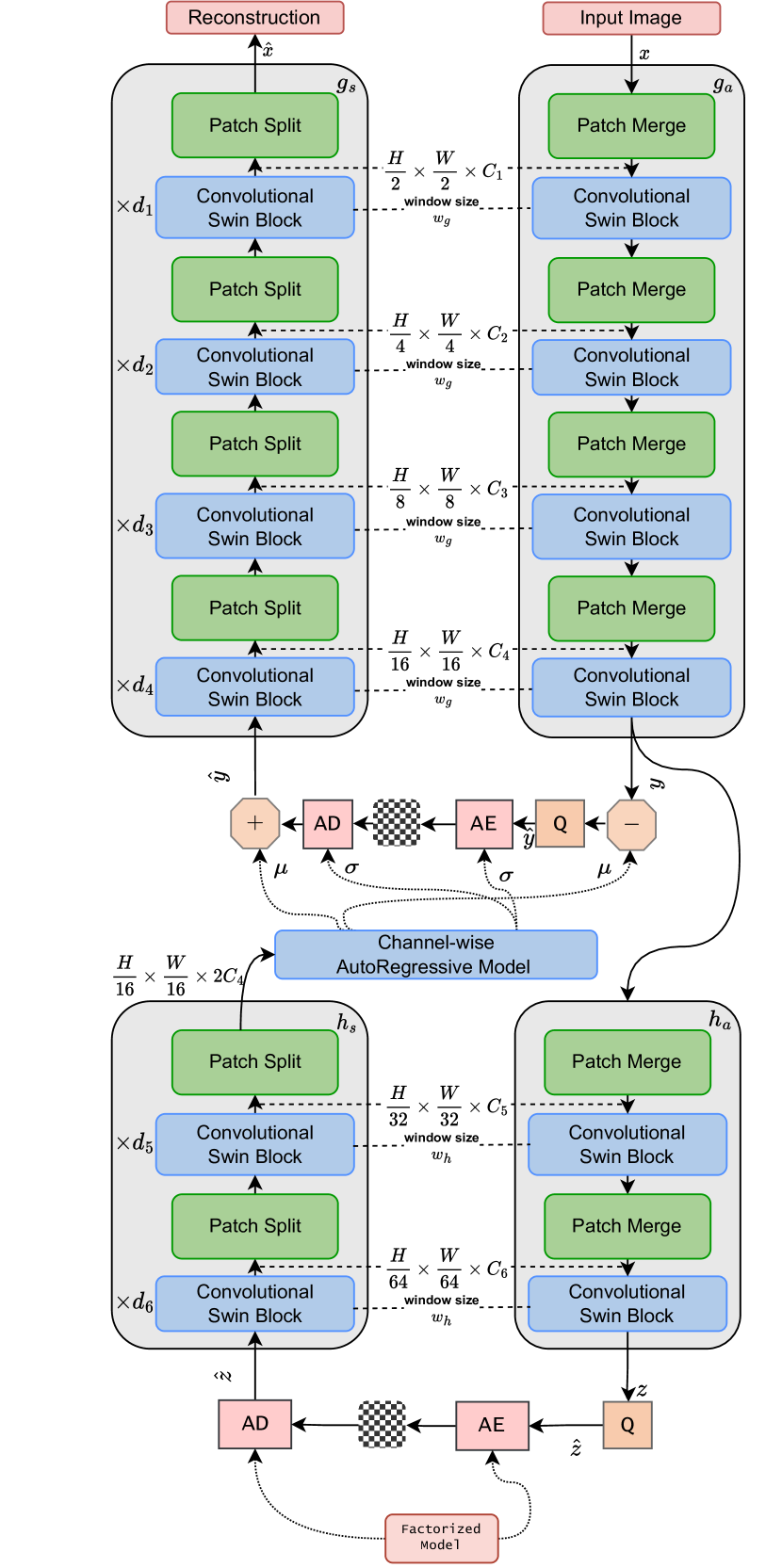
Recent advancements in learned image compression (LIC) methods have demonstrated superior performance over traditional hand-crafted codecs. These learning-based methods often employ convolutional neural networks (CNNs) or Transformer-based architectures. However, these nonlinear approaches frequently overlook the frequency characteristics of images, which limits their compression efficiency. To address this issue, we propose a novel Transformer-based image compression method that enhances the transformation stage by considering frequency components within the feature map. Our method integrates a novel Hybrid Spatial-Channel Attention Transformer Block (HSCATB), where a spatial-based branch independently handles high and low frequencies at the attention layer, and a Channel-aware Self-Attention (CaSA) module captures information across channels, significantly improving compression performance. Additionally, we introduce a Mixed Local-Global Feed Forward Network (MLGFFN) within the Transformer block to enhance the extraction of diverse and rich information, which is crucial for effective compression. These innovations collectively improve the transformation's ability to project data into a more decorrelated latent space, thereby boosting overall compression efficiency. Experimental results demonstrate that our framework surpasses state-of-the-art LIC methods in rate-distortion performance.
Read more8/9/2024
0
Convolutional Transformer-Based Image Compression
Bouzid Arezki, Fangchen Feng, Anissa Mokraoui
In this paper, we present a novel transformer-based architecture for end-to-end image compression. Our architecture incorporates blocks that effectively capture local dependencies between tokens, eliminating the need for positional encoding by integrating convolutional operations within the multi-head attention mechanism. We demonstrate through experiments that our proposed framework surpasses state-of-the-art CNN-based architectures in terms of the trade-off between bit-rate and distortion and achieves comparable results to transformer-based methods while maintaining lower computational complexity.
Read more9/9/2024

0
HyCoT: Hyperspectral Compression Transformer with an Efficient Training Strategy
Martin Hermann Paul Fuchs, Behnood Rasti, Begum Demir
The development of learning-based hyperspectral image (HSI) compression models has recently attracted significant interest. Existing models predominantly utilize convolutional filters, which capture only local dependencies. Furthermore, they often incur high training costs and exhibit substantial computational complexity. To address these limitations, in this paper we propose Hyperspectral Compression Transformer (HyCoT) that is a transformer-based autoencoder for pixelwise HSI compression. Additionally, we introduce an efficient training strategy to accelerate the training process. Experimental results on the HySpecNet-11k dataset demonstrate that HyCoT surpasses the state-of-the-art across various compression ratios by over 1 dB with significantly reduced computational requirements. Our code and pre-trained weights are publicly available at https://git.tu-berlin.de/rsim/hycot .
Read more8/19/2024
👁️
0
Generative Adversarial Networks for Spatio-Spectral Compression of Hyperspectral Images
Martin Hermann Paul Fuchs, Akshara Preethy Byju, Alisa Walda, Behnood Rasti, Begum Demir
The development of deep learning-based models for the compression of hyperspectral images (HSIs) has recently attracted great attention in remote sensing due to the sharp growing of hyperspectral data archives. Most of the existing models achieve either spectral or spatial compression, and do not jointly consider the spatio-spectral redundancies present in HSIs. To address this problem, in this paper we focus our attention on the High Fidelity Compression (HiFiC) model (which is proven to be highly effective for spatial compression problems) and adapt it to perform spatio-spectral compression of HSIs. In detail, we introduce two new models: i) HiFiC using Squeeze and Excitation (SE) blocks (denoted as HiFiC$_{SE}$); and ii) HiFiC with 3D convolutions (denoted as HiFiC$_{3D}$) in the framework of compression of HSIs. We analyze the effectiveness of HiFiC$_{SE}$ and HiFiC$_{3D}$ in compressing the spatio-spectral redundancies with channel attention and inter-dependency analysis. Experimental results show the efficacy of the proposed models in performing spatio-spectral compression, while reconstructing images at reduced bitrates with higher reconstruction quality. The code of the proposed models is publicly available at https://git.tu-berlin.de/rsim/HSI-SSC .
Read more7/8/2024