Convolutional Transformer-Based Image Compression

0
Sign in to get full access
Overview
- Presents a convolutional transformer-based model for image compression
- Combines convolutional neural networks and transformer-based architectures for improved rate-distortion performance
- Leverages attention mechanism to capture long-range dependencies in images
Plain English Explanation
The paper introduces a new approach to image compression that combines convolutional neural networks and transformer-based architectures. Convolutional neural networks are well-suited for capturing local spatial information in images, while transformers excel at modeling long-range dependencies. By integrating these two powerful techniques, the proposed framework can achieve improved rate-distortion performance compared to traditional image compression methods.
The key idea is to use the attention mechanism of transformers to capture important global information in the image, while still leveraging the local feature extraction capabilities of convolutional networks. This allows the model to better understand the overall structure and context of the image, leading to more efficient compression.
Technical Explanation
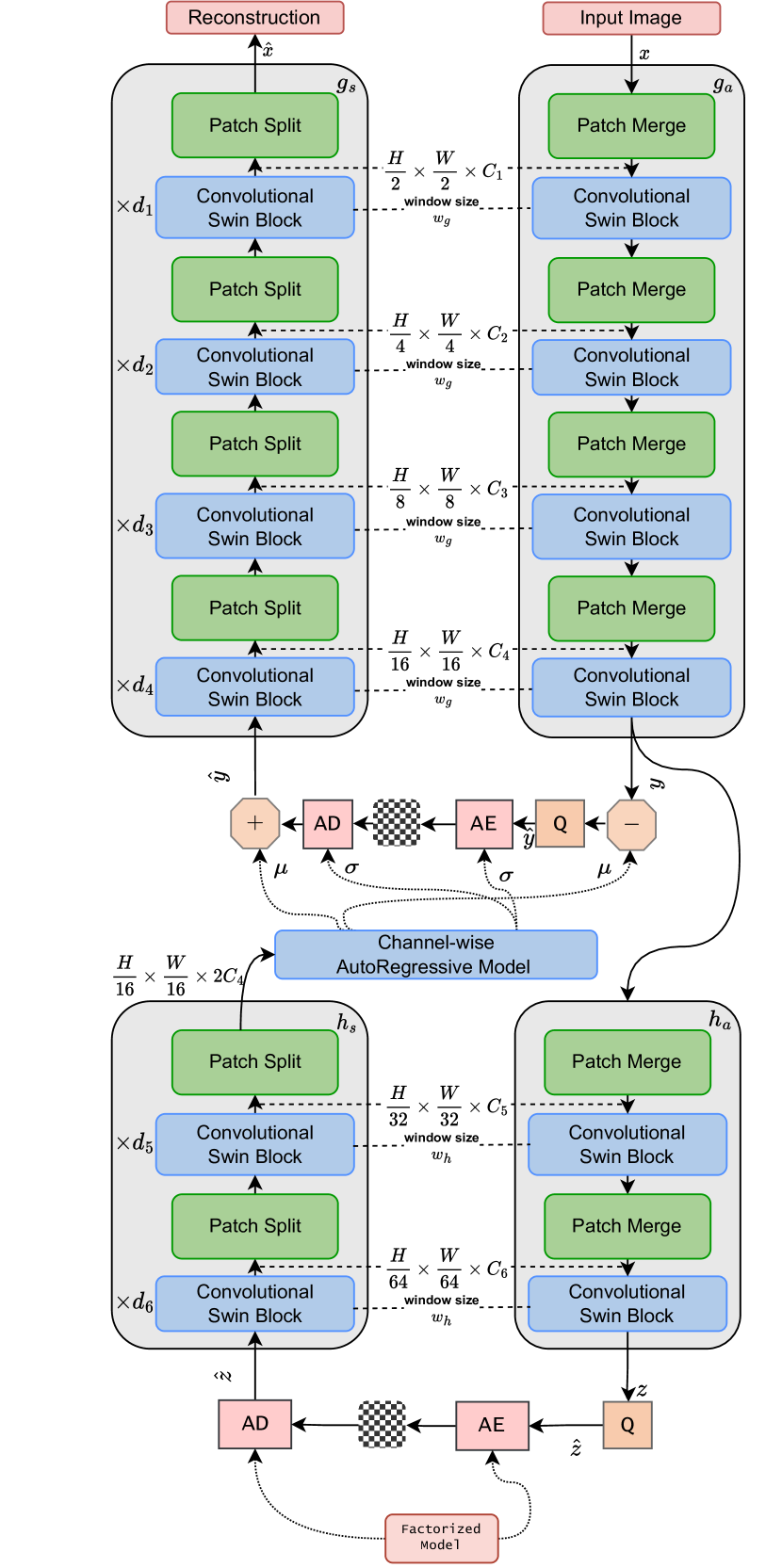
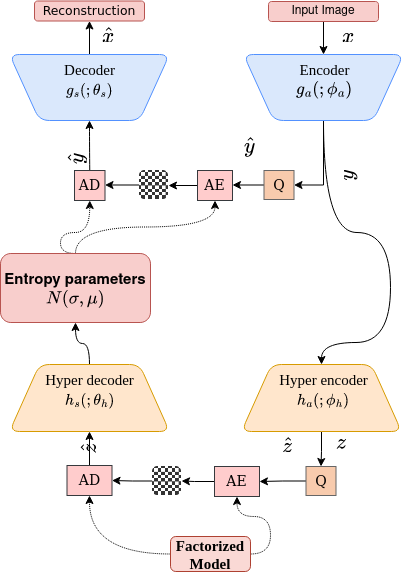
The proposed framework consists of an encoder and a decoder network. The encoder takes the input image and produces a compact latent representation, which is then quantized and entropy-coded for transmission. The decoder receives the encoded bitstream and reconstructs the original image.
The encoder network uses a convolutional architecture to extract local features, followed by a transformer-based module to capture long-range dependencies. The attention mechanism in the transformer helps the model focus on the most relevant regions of the image, improving the overall compression quality.
The decoder network reverses the process, first using a transformer-based module to decode the global information, and then a convolutional network to reconstruct the final image. The authors also incorporate a rate-distortion optimization technique to balance the trade-off between compression rate and reconstruction quality.
Critical Analysis
The paper presents a well-designed and thorough evaluation of the proposed convolutional transformer-based image compression model. The authors demonstrate significant improvements in rate-distortion performance compared to state-of-the-art methods, across a variety of image datasets and compression levels.
One potential limitation is the increased complexity of the model, which may impact its computational efficiency and deployment in resource-constrained environments. The authors acknowledge this trade-off and suggest that further research is needed to strike the right balance between compression quality and model complexity.
Additionally, the paper does not explore the impact of the proposed approach on specific image types or applications, such as medical imaging or surveillance, where the preservation of fine details may be critical. Further research in these domains could provide valuable insights and guide the development of more specialized compression solutions.
Conclusion
The convolutional transformer-based image compression framework presented in this paper represents a promising step forward in the field of image compression. By leveraging the complementary strengths of convolutional networks and transformer-based architectures, the model can achieve state-of-the-art rate-distortion performance, making it a valuable tool for efficient image storage and transmission. As the field of deep learning continues to evolve, this research highlights the potential for innovative hybrid architectures to tackle challenging problems in image processing and beyond.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Convolutional Transformer-Based Image Compression
Bouzid Arezki, Fangchen Feng, Anissa Mokraoui
In this paper, we present a novel transformer-based architecture for end-to-end image compression. Our architecture incorporates blocks that effectively capture local dependencies between tokens, eliminating the need for positional encoding by integrating convolutional operations within the multi-head attention mechanism. We demonstrate through experiments that our proposed framework surpasses state-of-the-art CNN-based architectures in terms of the trade-off between bit-rate and distortion and achieves comparable results to transformer-based methods while maintaining lower computational complexity.
Read more9/9/2024
0
On Efficient Neural Network Architectures for Image Compression
Yichi Zhang, Zhihao Duan, Fengqing Zhu
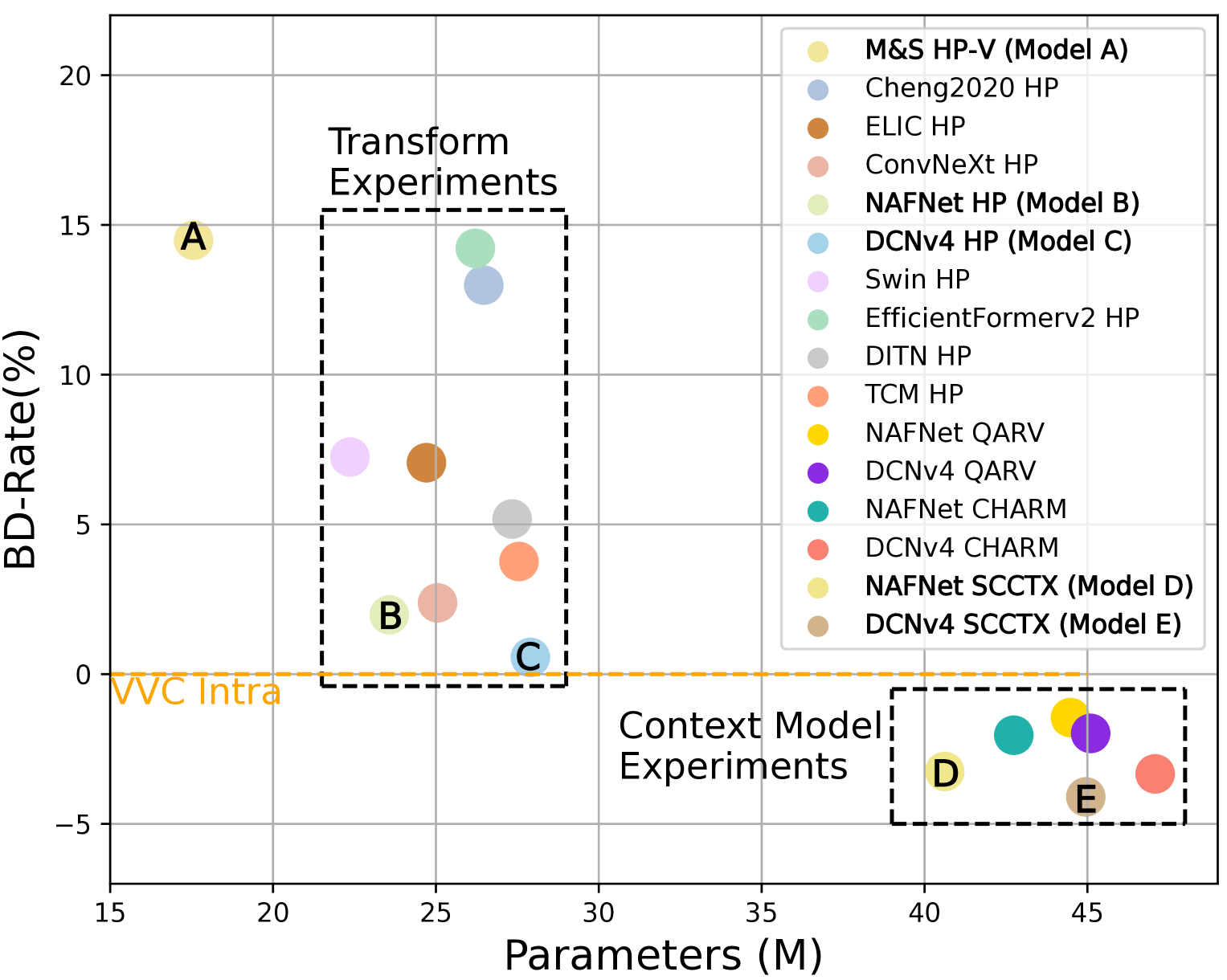
Recent advances in learning-based image compression typically come at the cost of high complexity. Designing computationally efficient architectures remains an open challenge. In this paper, we empirically investigate the impact of different network designs in terms of rate-distortion performance and computational complexity. Our experiments involve testing various transforms, including convolutional neural networks and transformers, as well as various context models, including hierarchical, channel-wise, and space-channel context models. Based on the results, we present a series of efficient models, the final model of which has comparable performance to recent best-performing methods but with significantly lower complexity. Extensive experiments provide insights into the design of architectures for learned image compression and potential direction for future research. The code is available at url{https://gitlab.com/viper-purdue/efficient-compression}.
Read more6/18/2024
0
Universal End-to-End Neural Network for Lossy Image Compression
Bouzid Arezki, Fangchen Feng, Anissa Mokraoui
This paper presents variable bitrate lossy image compression using a VAE-based neural network. An adaptable image quality adjustment strategy is proposed. The key innovation involves adeptly adjusting the input scale exclusively during the inference process, resulting in an exceptionally efficient rate-distortion mechanism. Through extensive experimentation, across diverse VAE-based compression architectures (CNN, ViT) and training methodologies (MSE, SSIM), our approach exhibits remarkable universality. This success is attributed to the inherent generalization capacity of neural networks. Unlike methods that adjust model architecture or loss functions, our approach emphasizes simplicity, reducing computational complexity and memory requirements. The experiments not only highlight the effectiveness of our approach but also indicate its potential to drive advancements in variable-rate neural network lossy image compression methodologies.
Read more9/11/2024
👨🏫
0
Transformer-Aided Semantic Communications
Matin Mortaheb, Erciyes Karakaya, Mohammad A. Amir Khojastepour, Sennur Ulukus
The transformer structure employed in large language models (LLMs), as a specialized category of deep neural networks (DNNs) featuring attention mechanisms, stands out for their ability to identify and highlight the most relevant aspects of input data. Such a capability is particularly beneficial in addressing a variety of communication challenges, notably in the realm of semantic communication where proper encoding of the relevant data is critical especially in systems with limited bandwidth. In this work, we employ vision transformers specifically for the purpose of compression and compact representation of the input image, with the goal of preserving semantic information throughout the transmission process. Through the use of the attention mechanism inherent in transformers, we create an attention mask. This mask effectively prioritizes critical segments of images for transmission, ensuring that the reconstruction phase focuses on key objects highlighted by the mask. Our methodology significantly improves the quality of semantic communication and optimizes bandwidth usage by encoding different parts of the data in accordance with their semantic information content, thus enhancing overall efficiency. We evaluate the effectiveness of our proposed framework using the TinyImageNet dataset, focusing on both reconstruction quality and accuracy. Our evaluation results demonstrate that our framework successfully preserves semantic information, even when only a fraction of the encoded data is transmitted, according to the intended compression rates.
Read more5/3/2024