Bias in Motion: Theoretical Insights into the Dynamics of Bias in SGD Training
2405.18296
0
0
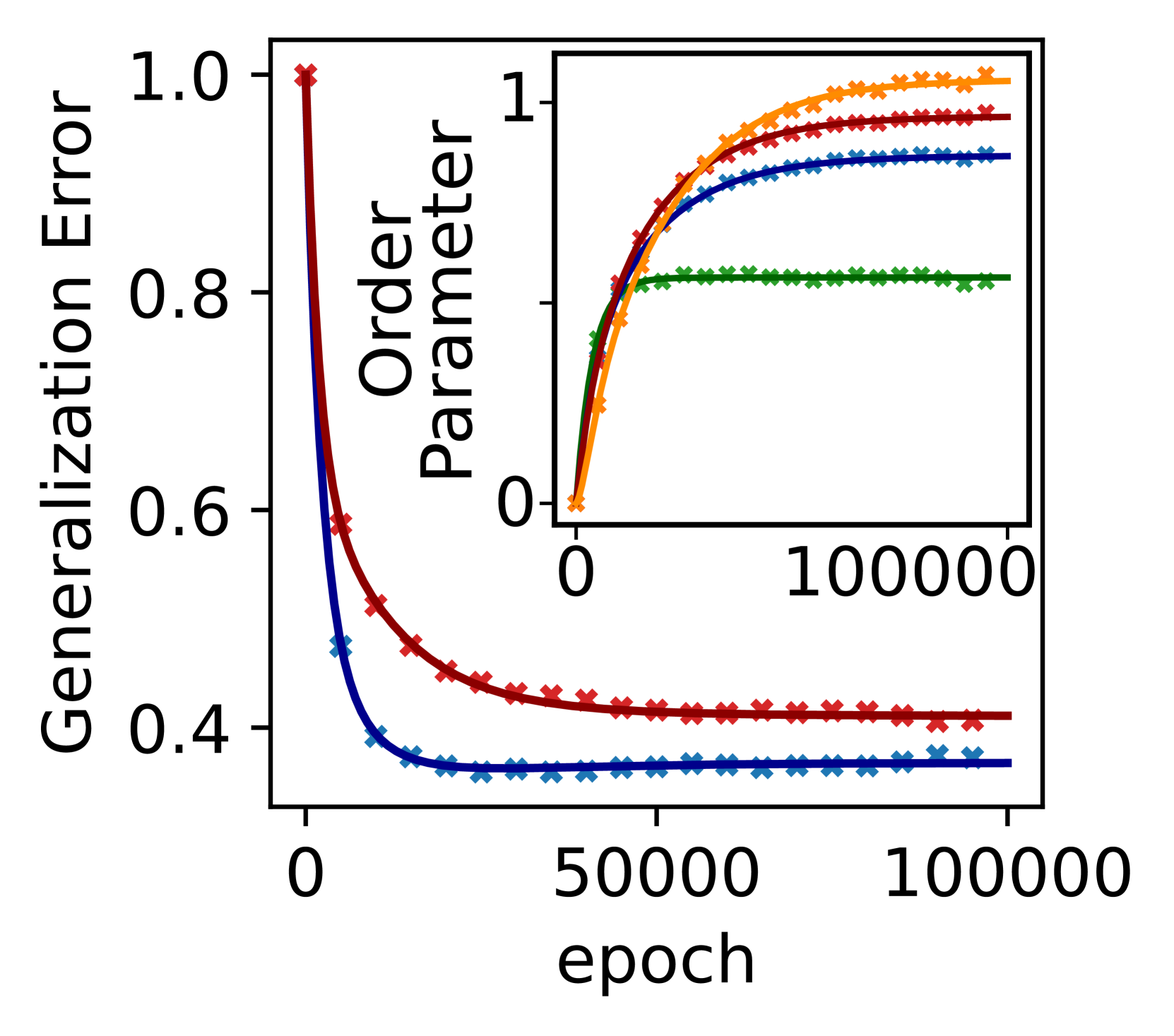
Abstract
Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations. Current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup modeling different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setting, which we prove to be exact in high dimension. Notably, our analysis reveals how different properties of sub-populations influence bias at different timescales, showing a shifting preference of the classifier during training. Applying our findings to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real datasets, including CIFAR10, MNIST, and CelebA.
Create account to get full access
Overview
- This paper explores the theoretical dynamics of bias in stochastic gradient descent (SGD) training of machine learning models.
- The authors analyze how biases in the data and optimization process can evolve and propagate during training, leading to biased models.
- They develop a theoretical framework to study this phenomenon and provide insights that could help mitigate bias in machine learning systems.
Plain English Explanation
When training machine learning models, the data used and the way the optimization process works can introduce biases. These biases can then get "baked in" to the final model, leading to unfair or inaccurate predictions.
The authors of this paper wanted to better understand how these biases arise and change over the course of training. They came up with a mathematical model to study this phenomenon.
Their analysis shows that biases can actually grow and spread as the model is trained, even if the initial data is unbiased. This is because the way the optimization algorithm (SGD) works can amplify and propagate biases present in the data or the training process.
The insights from this theoretical framework could help machine learning practitioners develop techniques to detect and mitigate bias in their models, leading to fairer and more reliable AI systems. For example, the research suggests ways to modify the optimization algorithm or architecture to be more robust to biases.
Technical Explanation
The paper develops a theoretical framework to analyze the dynamics of bias during the stochastic gradient descent (SGD) training of machine learning models. The authors consider a simplified two-layer neural network architecture and study how biases in the data and the optimization process can evolve over the course of training.
They model the bias as a vector that gets updated at each SGD iteration based on the gradient of the loss function. Their analysis shows that this bias vector can grow in magnitude and spread to different parts of the model, even when the initial data is unbiased.
This "bias amplification" occurs because the SGD updates combine gradients from different data points, which can lead to the accumulation and propagation of biases. The authors characterize this process mathematically and identify key factors, such as the learning rate and the structure of the loss landscape, that influence the dynamics of bias.
The theoretical insights provided in the paper could inform the development of debiasing techniques for machine learning, such as modifying the optimization algorithm or the model architecture to be more robust to biases. The framework also suggests ways to monitor and diagnose bias issues during training.
Critical Analysis
The paper provides a valuable theoretical foundation for understanding the behavior of biases in SGD training. The authors make simplifying assumptions, such as a two-layer network architecture, to make the analysis tractable. While this allows them to derive analytical insights, it's important to consider how the results might generalize to more complex, real-world machine learning models.
Additionally, the paper focuses on a specific type of bias, namely the bias in the model parameters. Other forms of bias, such as representation bias or algorithmic bias, are not explicitly addressed. Further research may be needed to understand the interplay between different types of biases and their collective impact on model performance and fairness.
The paper also does not provide empirical validation of the theoretical predictions on real-world datasets or machine learning tasks. While the mathematical framework is compelling, it would be helpful to see how well it aligns with observed biases in practical applications.
Despite these limitations, the paper offers a solid theoretical foundation for understanding bias dynamics in machine learning and can inform the development of bias-mitigating techniques. Continued research in this direction, combined with empirical studies, could lead to more robust and fair AI systems.
Conclusion
This paper presents a theoretical analysis of the dynamics of bias in stochastic gradient descent (SGD) training of machine learning models. The authors develop a mathematical framework to study how biases in the data and optimization process can evolve and propagate during the course of training, leading to biased models.
The key insights from this research suggest that biases can amplify and spread, even when the initial data is unbiased. This is due to the way the SGD algorithm combines gradients from different data points, which can accumulate and propagate biases. The authors identify factors that influence these bias dynamics, such as the learning rate and the structure of the loss landscape.
The theoretical framework provided in this paper could inform the development of debiasing techniques for machine learning, helping to create more reliable and fair AI systems. Future research building on this work, combined with empirical validation, could lead to a deeper understanding of bias in machine learning and practical solutions to mitigate it.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔗
Stochastic Collapse: How Gradient Noise Attracts SGD Dynamics Towards Simpler Subnetworks
Feng Chen, Daniel Kunin, Atsushi Yamamura, Surya Ganguli
0
0
In this work, we reveal a strong implicit bias of stochastic gradient descent (SGD) that drives overly expressive networks to much simpler subnetworks, thereby dramatically reducing the number of independent parameters, and improving generalization. To reveal this bias, we identify invariant sets, or subsets of parameter space that remain unmodified by SGD. We focus on two classes of invariant sets that correspond to simpler (sparse or low-rank) subnetworks and commonly appear in modern architectures. Our analysis uncovers that SGD exhibits a property of stochastic attractivity towards these simpler invariant sets. We establish a sufficient condition for stochastic attractivity based on a competition between the loss landscape's curvature around the invariant set and the noise introduced by stochastic gradients. Remarkably, we find that an increased level of noise strengthens attractivity, leading to the emergence of attractive invariant sets associated with saddle-points or local maxima of the train loss. We observe empirically the existence of attractive invariant sets in trained deep neural networks, implying that SGD dynamics often collapses to simple subnetworks with either vanishing or redundant neurons. We further demonstrate how this simplifying process of stochastic collapse benefits generalization in a linear teacher-student framework. Finally, through this analysis, we mechanistically explain why early training with large learning rates for extended periods benefits subsequent generalization.
5/30/2024
➖
Initial Guessing Bias: How Untrained Networks Favor Some Classes
Emanuele Francazi, Aurelien Lucchi, Marco Baity-Jesi
0
0
Understanding and controlling biasing effects in neural networks is crucial for ensuring accurate and fair model performance. In the context of classification problems, we provide a theoretical analysis demonstrating that the structure of a deep neural network (DNN) can condition the model to assign all predictions to the same class, even before the beginning of training, and in the absence of explicit biases. We prove that, besides dataset properties, the presence of this phenomenon, which we call textit{Initial Guessing Bias} (IGB), is influenced by model choices including dataset preprocessing methods, and architectural decisions, such as activation functions, max-pooling layers, and network depth. Our analysis of IGB provides information for architecture selection and model initialization. We also highlight theoretical consequences, such as the breakdown of node-permutation symmetry, the violation of self-averaging and the non-trivial effects that depth has on the phenomenon.
6/17/2024

Beyond Implicit Bias: The Insignificance of SGD Noise in Online Learning
Nikhil Vyas, Depen Morwani, Rosie Zhao, Gal Kaplun, Sham Kakade, Boaz Barak
0
0
The success of SGD in deep learning has been ascribed by prior works to the implicit bias induced by finite batch sizes (SGD noise). While prior works focused on offline learning (i.e., multiple-epoch training), we study the impact of SGD noise on online (i.e., single epoch) learning. Through an extensive empirical analysis of image and language data, we demonstrate that small batch sizes do not confer any implicit bias advantages in online learning. In contrast to offline learning, the benefits of SGD noise in online learning are strictly computational, facilitating more cost-effective gradient steps. This suggests that SGD in the online regime can be construed as taking noisy steps along the golden path of the noiseless gradient descent algorithm. We study this hypothesis and provide supporting evidence in loss and function space. Our findings challenge the prevailing understanding of SGD and offer novel insights into its role in online learning.
6/10/2024
🤔
Towards Exact Computation of Inductive Bias
Akhilan Boopathy, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
0
0
Much research in machine learning involves finding appropriate inductive biases (e.g. convolutional neural networks, momentum-based optimizers, transformers) to promote generalization on tasks. However, quantification of the amount of inductive bias associated with these architectures and hyperparameters has been limited. We propose a novel method for efficiently computing the inductive bias required for generalization on a task with a fixed training data budget; formally, this corresponds to the amount of information required to specify well-generalizing models within a specific hypothesis space of models. Our approach involves modeling the loss distribution of random hypotheses drawn from a hypothesis space to estimate the required inductive bias for a task relative to these hypotheses. Unlike prior work, our method provides a direct estimate of inductive bias without using bounds and is applicable to diverse hypothesis spaces. Moreover, we derive approximation error bounds for our estimation approach in terms of the number of sampled hypotheses. Consistent with prior results, our empirical results demonstrate that higher dimensional tasks require greater inductive bias. We show that relative to other expressive model classes, neural networks as a model class encode large amounts of inductive bias. Furthermore, our measure quantifies the relative difference in inductive bias between different neural network architectures. Our proposed inductive bias metric provides an information-theoretic interpretation of the benefits of specific model architectures for certain tasks and provides a quantitative guide to developing tasks requiring greater inductive bias, thereby encouraging the development of more powerful inductive biases.
6/26/2024