Initial Guessing Bias: How Untrained Networks Favor Some Classes
2306.00809
0
0
➖
Abstract
Understanding and controlling biasing effects in neural networks is crucial for ensuring accurate and fair model performance. In the context of classification problems, we provide a theoretical analysis demonstrating that the structure of a deep neural network (DNN) can condition the model to assign all predictions to the same class, even before the beginning of training, and in the absence of explicit biases. We prove that, besides dataset properties, the presence of this phenomenon, which we call textit{Initial Guessing Bias} (IGB), is influenced by model choices including dataset preprocessing methods, and architectural decisions, such as activation functions, max-pooling layers, and network depth. Our analysis of IGB provides information for architecture selection and model initialization. We also highlight theoretical consequences, such as the breakdown of node-permutation symmetry, the violation of self-averaging and the non-trivial effects that depth has on the phenomenon.
Create account to get full access
Overview
- This paper provides a theoretical analysis of how the structure of deep neural networks (DNNs) can lead to biased model predictions, even before training begins.
- The authors introduce the concept of "Initial Guessing Bias" (IGB), where a DNN can be conditioned to assign all predictions to the same class, due to factors like dataset preprocessing, activation functions, and network depth.
- The analysis of IGB offers insights for architecture selection and model initialization, and highlights theoretical consequences like the breakdown of node-permutation symmetry and the non-trivial effects of depth on the phenomenon.
Plain English Explanation
Neural networks are powerful machine learning models that can be used for a variety of tasks, such as image classification and language processing. However, ensuring these models are accurate and fair is crucial, as they can sometimes exhibit biases that can lead to unfair or inaccurate predictions.
This paper explores a phenomenon called "Initial Guessing Bias" (IGB), where a neural network can be conditioned to always predict the same class, even before the training process begins. This can happen due to the way the network is designed, such as the choice of activation functions or the depth of the network.
The researchers provide a theoretical analysis of IGB, showing how it can arise from factors like dataset preprocessing and network architecture. This information can help researchers and developers make more informed choices when designing and training neural networks, to minimize the risk of biased predictions.
Technical Explanation
The authors of this paper provide a theoretical analysis of how the structure of a deep neural network (DNN) can condition the model to assign all predictions to the same class, even before the beginning of training, and in the absence of explicit biases.
They introduce the concept of "Initial Guessing Bias" (IGB), which describes this phenomenon. The authors prove that, besides dataset properties, the presence of IGB is influenced by model choices such as dataset preprocessing methods, activation functions, max-pooling layers, and network depth.
Their analysis of IGB offers information for architecture selection and model initialization. The paper also highlights theoretical consequences of IGB, such as the breakdown of node-permutation symmetry, the violation of self-averaging, and the non-trivial effects that depth has on the phenomenon.
Critical Analysis
The paper provides a thorough theoretical analysis of the "Initial Guessing Bias" (IGB) phenomenon, which is an important consideration for ensuring fair and accurate neural network performance. The authors' exploration of how factors like dataset preprocessing and network architecture can contribute to IGB is valuable for researchers and developers working on neural network models.
That said, the paper is quite technical and may be challenging for a general audience to fully understand. While the plain English explanation attempts to make the key ideas more accessible, some readers may still struggle with the more complex concepts and mathematical formulations.
Additionally, the paper does not provide empirical validation of the IGB phenomenon or the proposed theoretical insights. While the analysis is rigorous, it would be helpful to see the authors demonstrate the real-world implications and impacts of IGB through experimental studies.
Overall, this paper offers important theoretical contributions to the field of machine learning, but further research and practical applications may be needed to fully understand the significance and implications of IGB in the development of fair and accurate neural network models.
Conclusion
This paper presents a theoretical analysis of the "Initial Guessing Bias" (IGB) phenomenon in deep neural networks, where a model can be conditioned to assign all predictions to the same class, even before training begins. The authors demonstrate that IGB is influenced by factors like dataset preprocessing, activation functions, and network depth, in addition to the properties of the dataset itself.
The insights from this analysis can inform the design and initialization of neural network architectures, helping to mitigate the risk of biased predictions. While the paper is technically sophisticated, the potential implications for improving the fairness and accuracy of AI systems are significant. As the use of neural networks continues to expand, understanding and addressing biases like IGB will be crucial for building trustworthy and responsible AI technologies.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Bias in Motion: Theoretical Insights into the Dynamics of Bias in SGD Training
Anchit Jain, Rozhin Nobahari, Aristide Baratin, Stefano Sarao Mannelli
0
0
Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations. Current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup modeling different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setting, which we prove to be exact in high dimension. Notably, our analysis reveals how different properties of sub-populations influence bias at different timescales, showing a shifting preference of the classifier during training. Applying our findings to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real datasets, including CIFAR10, MNIST, and CelebA.
5/29/2024
Can Biases in ImageNet Models Explain Generalization?
Paul Gavrikov, Janis Keuper
0
0
The robust generalization of models to rare, in-distribution (ID) samples drawn from the long tail of the training distribution and to out-of-training-distribution (OOD) samples is one of the major challenges of current deep learning methods. For image classification, this manifests in the existence of adversarial attacks, the performance drops on distorted images, and a lack of generalization to concepts such as sketches. The current understanding of generalization in neural networks is very limited, but some biases that differentiate models from human vision have been identified and might be causing these limitations. Consequently, several attempts with varying success have been made to reduce these biases during training to improve generalization. We take a step back and sanity-check these attempts. Fixing the architecture to the well-established ResNet-50, we perform a large-scale study on 48 ImageNet models obtained via different training methods to understand how and if these biases - including shape bias, spectral biases, and critical bands - interact with generalization. Our extensive study results reveal that contrary to previous findings, these biases are insufficient to accurately predict the generalization of a model holistically. We provide access to all checkpoints and evaluation code at https://github.com/paulgavrikov/biases_vs_generalization
4/3/2024
🤔
Towards Exact Computation of Inductive Bias
Akhilan Boopathy, William Yue, Jaedong Hwang, Abhiram Iyer, Ila Fiete
0
0
Much research in machine learning involves finding appropriate inductive biases (e.g. convolutional neural networks, momentum-based optimizers, transformers) to promote generalization on tasks. However, quantification of the amount of inductive bias associated with these architectures and hyperparameters has been limited. We propose a novel method for efficiently computing the inductive bias required for generalization on a task with a fixed training data budget; formally, this corresponds to the amount of information required to specify well-generalizing models within a specific hypothesis space of models. Our approach involves modeling the loss distribution of random hypotheses drawn from a hypothesis space to estimate the required inductive bias for a task relative to these hypotheses. Unlike prior work, our method provides a direct estimate of inductive bias without using bounds and is applicable to diverse hypothesis spaces. Moreover, we derive approximation error bounds for our estimation approach in terms of the number of sampled hypotheses. Consistent with prior results, our empirical results demonstrate that higher dimensional tasks require greater inductive bias. We show that relative to other expressive model classes, neural networks as a model class encode large amounts of inductive bias. Furthermore, our measure quantifies the relative difference in inductive bias between different neural network architectures. Our proposed inductive bias metric provides an information-theoretic interpretation of the benefits of specific model architectures for certain tasks and provides a quantitative guide to developing tasks requiring greater inductive bias, thereby encouraging the development of more powerful inductive biases.
6/26/2024
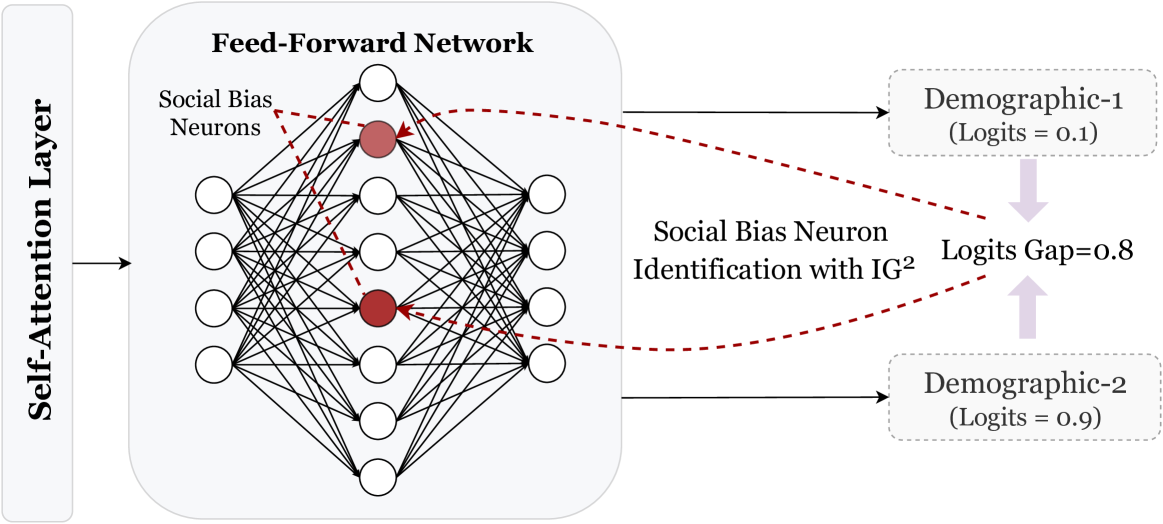
The Devil is in the Neurons: Interpreting and Mitigating Social Biases in Pre-trained Language Models
Yan Liu, Yu Liu, Xiaokang Chen, Pin-Yu Chen, Daoguang Zan, Min-Yen Kan, Tsung-Yi Ho
0
0
Pre-trained Language models (PLMs) have been acknowledged to contain harmful information, such as social biases, which may cause negative social impacts or even bring catastrophic results in application. Previous works on this problem mainly focused on using black-box methods such as probing to detect and quantify social biases in PLMs by observing model outputs. As a result, previous debiasing methods mainly finetune or even pre-train language models on newly constructed anti-stereotypical datasets, which are high-cost. In this work, we try to unveil the mystery of social bias inside language models by introducing the concept of {sc Social Bias Neurons}. Specifically, we propose {sc Integrated Gap Gradients (IG$^2$)} to accurately pinpoint units (i.e., neurons) in a language model that can be attributed to undesirable behavior, such as social bias. By formalizing undesirable behavior as a distributional property of language, we employ sentiment-bearing prompts to elicit classes of sensitive words (demographics) correlated with such sentiments. Our IG$^2$ thus attributes the uneven distribution for different demographics to specific Social Bias Neurons, which track the trail of unwanted behavior inside PLM units to achieve interoperability. Moreover, derived from our interpretable technique, {sc Bias Neuron Suppression (BNS)} is further proposed to mitigate social biases. By studying BERT, RoBERTa, and their attributable differences from debiased FairBERTa, IG$^2$ allows us to locate and suppress identified neurons, and further mitigate undesired behaviors. As measured by prior metrics from StereoSet, our model achieves a higher degree of fairness while maintaining language modeling ability with low cost.
6/17/2024