Stochastic Collapse: How Gradient Noise Attracts SGD Dynamics Towards Simpler Subnetworks
2306.04251
0
0
🔗
Abstract
In this work, we reveal a strong implicit bias of stochastic gradient descent (SGD) that drives overly expressive networks to much simpler subnetworks, thereby dramatically reducing the number of independent parameters, and improving generalization. To reveal this bias, we identify invariant sets, or subsets of parameter space that remain unmodified by SGD. We focus on two classes of invariant sets that correspond to simpler (sparse or low-rank) subnetworks and commonly appear in modern architectures. Our analysis uncovers that SGD exhibits a property of stochastic attractivity towards these simpler invariant sets. We establish a sufficient condition for stochastic attractivity based on a competition between the loss landscape's curvature around the invariant set and the noise introduced by stochastic gradients. Remarkably, we find that an increased level of noise strengthens attractivity, leading to the emergence of attractive invariant sets associated with saddle-points or local maxima of the train loss. We observe empirically the existence of attractive invariant sets in trained deep neural networks, implying that SGD dynamics often collapses to simple subnetworks with either vanishing or redundant neurons. We further demonstrate how this simplifying process of stochastic collapse benefits generalization in a linear teacher-student framework. Finally, through this analysis, we mechanistically explain why early training with large learning rates for extended periods benefits subsequent generalization.
Create account to get full access
Overview
- Researchers have discovered a strong implicit bias in stochastic gradient descent (SGD), a widely used optimization algorithm in machine learning.
- This bias causes overly expressive neural networks to collapse into much simpler subnetworks, dramatically reducing the number of independent parameters while improving generalization.
- The researchers identify "invariant sets" - subsets of the parameter space that remain unchanged by SGD - and show that SGD is attracted to these simpler subnetworks.
- They establish a condition for this "stochastic attractivity" based on the interplay between the curvature of the loss landscape and the noise introduced by stochastic gradients.
- Empirically, the researchers observe this simplifying "stochastic collapse" in trained deep neural networks, where SGD often converges to sparse or low-rank subnetworks.
- They demonstrate how this simplification process benefits generalization in a linear teacher-student framework.
- The analysis also provides mechanistic insights into why extended training with large learning rates can improve subsequent generalization performance.
Plain English Explanation
Stochastic gradient descent (SGD) is a widely used optimization algorithm in machine learning that helps train complex neural networks. However, the researchers discovered an interesting bias in how SGD works.
Imagine you have a very complex neural network with a huge number of parameters (the "knobs" that can be adjusted during training). You might expect that SGD would fully utilize all of these parameters to fit the training data as well as possible. But what the researchers found is that SGD actually has a strong tendency to collapse this complex network down into a much simpler subnetwork, with far fewer independent parameters.
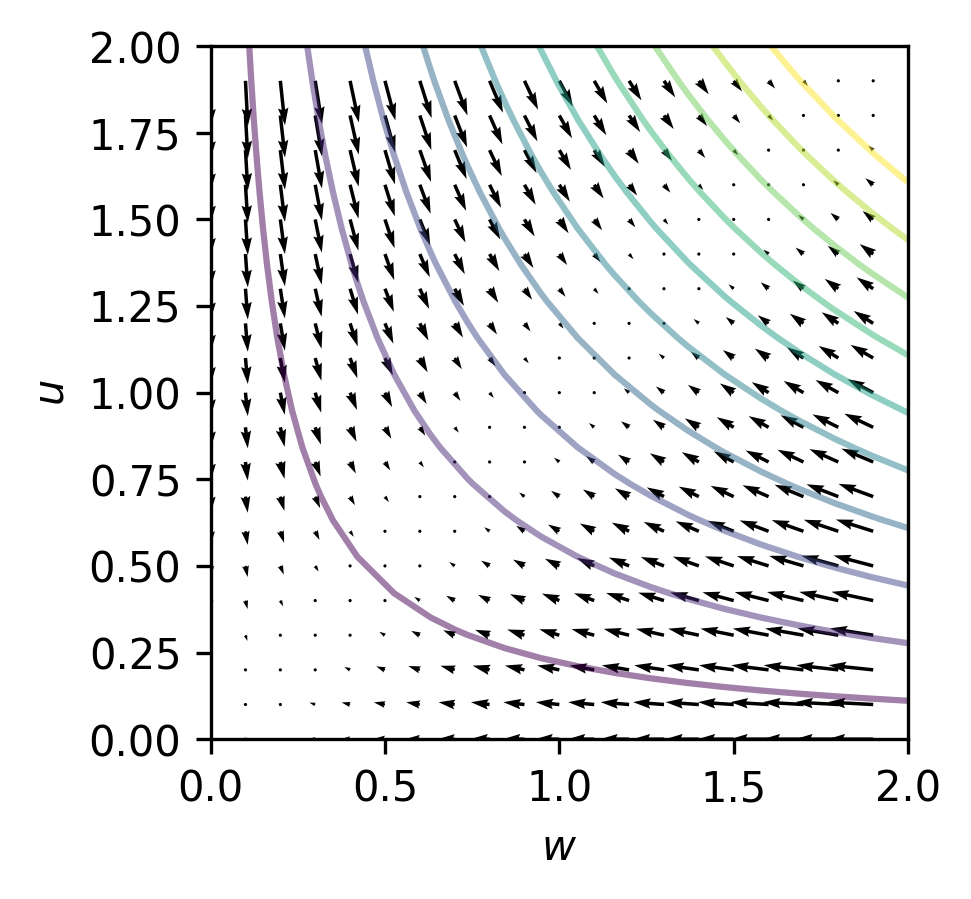
This "stochastic collapse" happens because SGD is attracted to certain "invariant sets" - subsets of the parameter space that remain unchanged during training. These invariant sets correspond to simpler, more streamlined neural network architectures, like those with sparse connections or low-rank weight matrices.
The researchers show that this attraction to simpler subnetworks is driven by a competition between the curvature of the loss function (the landscape that SGD is trying to optimize) and the noise introduced by the stochastic gradients. Interestingly, they found that higher noise levels can actually strengthen this attraction, causing SGD to converge to subnetworks associated with saddle points or even local maxima of the training loss.
So in practice, this means that even if you start with a very complex neural network, SGD will often find a much simpler version that still performs well. This "stochastic collapse" can actually be a good thing, as it helps improve the network's generalization - its ability to perform well on new, unseen data. The researchers demonstrate this in a simple linear "teacher-student" framework.
Finally, the analysis also sheds light on why training neural networks with large learning rates for extended periods can improve their subsequent generalization performance. By exploring this "stochastic collapse" phenomenon, the researchers have uncovered an intriguing and counterintuitive bias in how SGD optimizes neural networks.
Technical Explanation
The researchers reveal a strong implicit bias in stochastic gradient descent (SGD) that drives overly expressive neural networks to collapse into much simpler subnetworks. This dramatically reduces the number of independent parameters while improving generalization.
To uncover this bias, the researchers identify "invariant sets" - subsets of the parameter space that remain unmodified by SGD. They focus on two classes of invariant sets that correspond to simpler (sparse or low-rank) subnetworks, which commonly appear in modern neural architectures.
The analysis shows that SGD exhibits a property of "stochastic attractivity" towards these simpler invariant sets. The researchers establish a sufficient condition for this stochastic attractivity based on a competition between the curvature of the loss landscape around the invariant set and the noise introduced by stochastic gradients. Remarkably, they find that increased noise can actually strengthen this attractivity, leading to the emergence of attractive invariant sets associated with saddle points or local maxima of the training loss.
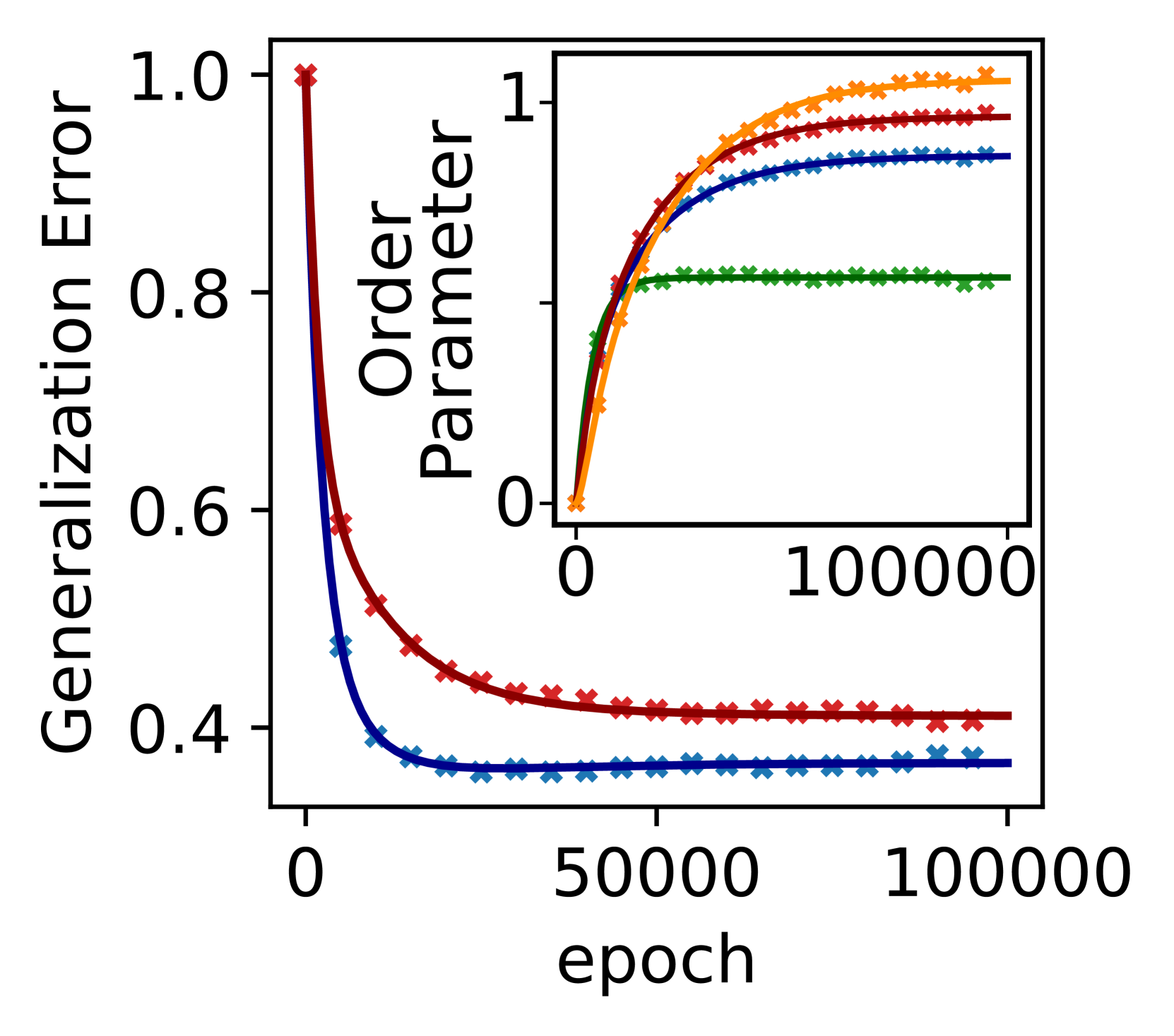
Empirically, the researchers observe the existence of these attractive invariant sets in trained deep neural networks, implying that SGD dynamics often converge to simple subnetworks with vanishing or redundant neurons. They further demonstrate how this "stochastic collapse" process benefits generalization in a linear teacher-student framework.
Finally, the analysis provides mechanistic insights into why extended training with large learning rates can improve subsequent generalization performance. By revealing SGD's strong bias towards simpler subnetworks, the researchers offer a new perspective on the dynamics and generalization properties of deep learning.
Critical Analysis
The researchers present a compelling and technically rigorous analysis of an intriguing bias in stochastic gradient descent (SGD). By identifying invariant sets corresponding to simpler neural network architectures, they shed light on how SGD often converges to much more streamlined models than one might expect.
One potential limitation of the work is that the theoretical analysis is primarily focused on linear or simplified neural network settings. While the researchers do observe the "stochastic collapse" phenomenon empirically in trained deep neural networks, it would be valuable to see a more comprehensive investigation of how this bias manifests in more complex, real-world architectures and tasks.
Additionally, the paper does not explore the extent to which this bias is influenced by factors like network initialization, regularization techniques, or the specific loss landscape of the problem being solved. Investigating these interactions could lead to a more holistic understanding of how this simplifying tendency of SGD interacts with other key elements of the deep learning training process.
Finally, while the researchers demonstrate benefits to generalization in a linear teacher-student framework, it would be insightful to see a more detailed exploration of the tradeoffs and practical implications of this stochastic collapse phenomenon. For example, how does it impact training efficiency, robustness, or the ability to learn complex representations?
Despite these potential avenues for further research, this work represents an important contribution to our mechanistic understanding of deep learning optimization. By uncovering a surprising bias in a widely used algorithm, the researchers have opened up new directions for improving the design and training of neural networks.
Conclusion
This research uncovers a strong implicit bias in stochastic gradient descent (SGD) that drives overly expressive neural networks to collapse into much simpler subnetworks. By identifying "invariant sets" corresponding to streamlined architectures, the researchers show that SGD exhibits a tendency to be attracted to these simpler, lower-dimensional models.
The analysis reveals that this "stochastic collapse" is driven by a competition between the curvature of the loss landscape and the noise introduced by stochastic gradients. Remarkably, increased noise can actually strengthen this attractivity, leading SGD to converge to subnetworks associated with saddle points or local maxima of the training loss.
Empirically observing this simplification process in trained deep neural networks, the researchers demonstrate how it can benefit generalization in a linear teacher-student framework. The work also sheds light on why extended training with large learning rates can improve subsequent performance, providing a mechanistic explanation for this phenomenon.
By uncovering this intriguing bias in a widely used optimization algorithm, the researchers have opened up new avenues for understanding the dynamics and generalization properties of deep learning. Their findings challenge our assumptions about how neural networks are trained and offer opportunities to leverage this "stochastic collapse" to design more efficient and effective models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Singular-limit analysis of gradient descent with noise injection
Anna Shalova, Andr'e Schlichting, Mark Peletier
0
0
We study the limiting dynamics of a large class of noisy gradient descent systems in the overparameterized regime. In this regime the set of global minimizers of the loss is large, and when initialized in a neighbourhood of this zero-loss set a noisy gradient descent algorithm slowly evolves along this set. In some cases this slow evolution has been related to better generalisation properties. We characterize this evolution for the broad class of noisy gradient descent systems in the limit of small step size. Our results show that the structure of the noise affects not just the form of the limiting process, but also the time scale at which the evolution takes place. We apply the theory to Dropout, label noise and classical SGD (minibatching) noise, and show that these evolve on different two time scales. Classical SGD even yields a trivial evolution on both time scales, implying that additional noise is required for regularization. The results are inspired by the training of neural networks, but the theorems apply to noisy gradient descent of any loss that has a non-trivial zero-loss set.
4/19/2024
Loss Symmetry and Noise Equilibrium of Stochastic Gradient Descent
Liu Ziyin, Mingze Wang, Hongchao Li, Lei Wu
0
0
Symmetries exist abundantly in the loss function of neural networks. We characterize the learning dynamics of stochastic gradient descent (SGD) when exponential symmetries, a broad subclass of continuous symmetries, exist in the loss function. We establish that when gradient noises do not balance, SGD has the tendency to move the model parameters toward a point where noises from different directions are balanced. Here, a special type of fixed point in the constant directions of the loss function emerges as a candidate for solutions for SGD. As the main theoretical result, we prove that every parameter $theta$ connects without loss function barrier to a unique noise-balanced fixed point $theta^*$. The theory implies that the balancing of gradient noise can serve as a novel alternative mechanism for relevant phenomena such as progressive sharpening and flattening and can be applied to understand common practical problems such as representation normalization, matrix factorization, warmup, and formation of latent representations.
6/4/2024
Bias in Motion: Theoretical Insights into the Dynamics of Bias in SGD Training
Anchit Jain, Rozhin Nobahari, Aristide Baratin, Stefano Sarao Mannelli
0
0
Machine learning systems often acquire biases by leveraging undesired features in the data, impacting accuracy variably across different sub-populations. Current understanding of bias formation mostly focuses on the initial and final stages of learning, leaving a gap in knowledge regarding the transient dynamics. To address this gap, this paper explores the evolution of bias in a teacher-student setup modeling different data sub-populations with a Gaussian-mixture model. We provide an analytical description of the stochastic gradient descent dynamics of a linear classifier in this setting, which we prove to be exact in high dimension. Notably, our analysis reveals how different properties of sub-populations influence bias at different timescales, showing a shifting preference of the classifier during training. Applying our findings to fairness and robustness, we delineate how and when heterogeneous data and spurious features can generate and amplify bias. We empirically validate our results in more complex scenarios by training deeper networks on synthetic and real datasets, including CIFAR10, MNIST, and CelebA.
5/29/2024

Weight fluctuations in (deep) linear neural networks and a derivation of the inverse-variance flatness relation
Markus Gross, Arne P. Raulf, Christoph Rath
0
0
We investigate the stationary (late-time) training regime of single- and two-layer underparameterized linear neural networks within the continuum limit of stochastic gradient descent (SGD) for synthetic Gaussian data. In the case of a single-layer network in the weakly underparameterized regime, the spectrum of the noise covariance matrix deviates notably from the Hessian, which can be attributed to the broken detailed balance of SGD dynamics. The weight fluctuations are in this case generally anisotropic, but effectively experience an isotropic loss. For an underparameterized two-layer network, we describe the stochastic dynamics of the weights in each layer and analyze the associated stationary covariances. We identify the inter-layer coupling as a distinct source of anisotropy for the weight fluctuations. In contrast to the single-layer case, the weight fluctuations are effectively subject to an anisotropic loss, the flatness of which is inversely related to the fluctuation variance. We thereby provide an analytical derivation of the recently observed inverse variance-flatness relation in a model of a deep linear neural network.
6/26/2024