BioCLIP: A Vision Foundation Model for the Tree of Life

0

Sign in to get full access
Overview
- This paper presents a new vision foundation model called TreeOfLife-10M for the Tree of Life, a comprehensive visual representation of the diversity of life on Earth.
- The model was trained on a large dataset of 10 million images spanning various life forms, from microbes to large animals.
- The authors demonstrate that TreeOfLife-10M can effectively capture the visual features and relationships between different species, enabling tasks like classification, localization, and image generation.
Plain English Explanation
The researchers have developed a new artificial intelligence (AI) model called TreeOfLife-10M that can analyze and understand a vast array of images related to the diversity of life on Earth. This model was trained on a massive dataset of 10 million images covering a wide range of living organisms, from microscopic bacteria to large animals.
One of the key capabilities of TreeOfLife-10M is its ability to recognize and classify different species based on their visual characteristics. It can also locate and identify specific organisms within an image, and even generate new images that depict realistic-looking life forms. This technology could have numerous applications, such as in biology education, ecological research, and conservation efforts.
By training the AI on such a comprehensive dataset, the researchers have enabled TreeOfLife-10M to capture the complex relationships and interconnections between different forms of life. This foundation model can serve as a powerful tool for scientists and educators to explore and understand the remarkable diversity of the natural world.
Technical Explanation
The paper introduces a new vision foundation model called TreeOfLife-10M, which was trained on a dataset of 10 million images covering a wide range of living organisms, from microbes to large animals.
The authors demonstrate that TreeOfLife-10M can effectively perform a variety of tasks, including image classification, object localization, and image generation. They evaluate the model's performance on a range of benchmark datasets and show that it outperforms existing approaches.
One of the key innovations of TreeOfLife-10M is its ability to capture the visual features and relationships between different species. The model's architecture and training strategy enable it to learn a rich, hierarchical representation of the Tree of Life, which can be leveraged for downstream applications.
The authors also discuss the potential limitations of their approach, such as the potential for biases in the training data, and suggest directions for future research to address these issues. They encourage further exploration and development of TreeOfLife-10M and similar foundation models to advance our understanding and appreciation of the natural world.
Critical Analysis
The paper presents a compelling approach to building a comprehensive visual representation of the Tree of Life using a large-scale foundation model. The authors have clearly put significant effort into curating a diverse dataset and designing an effective training strategy for TreeOfLife-10M.
One potential limitation highlighted in the paper is the potential for biases in the training data, which could lead to skewed or incomplete representations of certain species or taxonomic groups. The authors acknowledge this issue and suggest further research to address it, such as actively seeking out underrepresented data sources or developing techniques to mitigate biases.
Additionally, while the authors demonstrate the model's performance on various benchmarks, it would be valuable to see more real-world applications and case studies to understand the practical implications and limitations of TreeOfLife-10M. For example, how well does the model perform in tasks like species identification in the field, or in supporting conservation efforts?
Overall, the paper presents a promising step towards a more comprehensive and accessible representation of the natural world using advanced AI technologies. By encouraging further development and critical analysis of TreeOfLife-10M and similar foundation models, the research can help advance our understanding and appreciation of the remarkable diversity of life on our planet.
Conclusion
The TreeOfLife-10M model introduced in this paper represents a significant advancement in the field of computer vision and its application to understanding the natural world. By training an AI system on a massive dataset of 10 million images spanning a wide range of living organisms, the researchers have created a powerful tool for classifying, localizing, and even generating images of diverse life forms.
The model's ability to capture the visual features and relationships between different species holds great potential for a wide range of applications, from biology education and ecological research to conservation efforts and even artistic endeavors. As the authors suggest, further development and critical analysis of TreeOfLife-10M and similar foundation models can help us better understand and appreciate the remarkable diversity of life on our planet.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BioCLIP: A Vision Foundation Model for the Tree of Life
Samuel Stevens, Jiaman Wu, Matthew J Thompson, Elizabeth G Campolongo, Chan Hee Song, David Edward Carlyn, Li Dong, Wasila M Dahdul, Charles Stewart, Tanya Berger-Wolf, Wei-Lun Chao, Yu Su
Images of the natural world, collected by a variety of cameras, from drones to individual phones, are increasingly abundant sources of biological information. There is an explosion of computational methods and tools, particularly computer vision, for extracting biologically relevant information from images for science and conservation. Yet most of these are bespoke approaches designed for a specific task and are not easily adaptable or extendable to new questions, contexts, and datasets. A vision model for general organismal biology questions on images is of timely need. To approach this, we curate and release TreeOfLife-10M, the largest and most diverse ML-ready dataset of biology images. We then develop BioCLIP, a foundation model for the tree of life, leveraging the unique properties of biology captured by TreeOfLife-10M, namely the abundance and variety of images of plants, animals, and fungi, together with the availability of rich structured biological knowledge. We rigorously benchmark our approach on diverse fine-grained biology classification tasks and find that BioCLIP consistently and substantially outperforms existing baselines (by 16% to 17% absolute). Intrinsic evaluation reveals that BioCLIP has learned a hierarchical representation conforming to the tree of life, shedding light on its strong generalizability. https://imageomics.github.io/bioclip has models, data and code.
Read more5/16/2024

0
BIOSCAN-CLIP: Bridging Vision and Genomics for Biodiversity Monitoring at Scale
ZeMing Gong, Austin T. Wang, Joakim Bruslund Haurum, Scott C. Lowe, Graham W. Taylor, Angel X. Chang
Measuring biodiversity is crucial for understanding ecosystem health. While prior works have developed machine learning models for the taxonomic classification of photographic images and DNA separately, in this work, we introduce a multimodal approach combining both, using CLIP-style contrastive learning to align images, DNA barcodes, and textual data in a unified embedding space. This allows for accurate classification of both known and unknown insect species without task-specific fine-tuning, leveraging contrastive learning for the first time to fuse DNA and image data. Our method surpasses previous single-modality approaches in accuracy by over 11% on zero-shot learning tasks, showcasing its effectiveness in biodiversity studies.
Read more5/29/2024
📈
0
EyeCLIP: A visual-language foundation model for multi-modal ophthalmic image analysis
Danli Shi, Weiyi Zhang, Jiancheng Yang, Siyu Huang, Xiaolan Chen, Mayinuer Yusufu, Kai Jin, Shan Lin, Shunming Liu, Qing Zhang, Mingguang He
Early detection of eye diseases like glaucoma, macular degeneration, and diabetic retinopathy is crucial for preventing vision loss. While artificial intelligence (AI) foundation models hold significant promise for addressing these challenges, existing ophthalmic foundation models primarily focus on a single modality, whereas diagnosing eye diseases requires multiple modalities. A critical yet often overlooked aspect is harnessing the multi-view information across various modalities for the same patient. Additionally, due to the long-tail nature of ophthalmic diseases, standard fully supervised or unsupervised learning approaches often struggle. Therefore, it is essential to integrate clinical text to capture a broader spectrum of diseases. We propose EyeCLIP, a visual-language foundation model developed using over 2.77 million multi-modal ophthalmology images with partial text data. To fully leverage the large multi-modal unlabeled and labeled data, we introduced a pretraining strategy that combines self-supervised reconstructions, multi-modal image contrastive learning, and image-text contrastive learning to learn a shared representation of multiple modalities. Through evaluation using 14 benchmark datasets, EyeCLIP can be transferred to a wide range of downstream tasks involving ocular and systemic diseases, achieving state-of-the-art performance in disease classification, visual question answering, and cross-modal retrieval. EyeCLIP represents a significant advancement over previous methods, especially showcasing few-shot, even zero-shot capabilities in real-world long-tail scenarios.
Read more9/12/2024
0
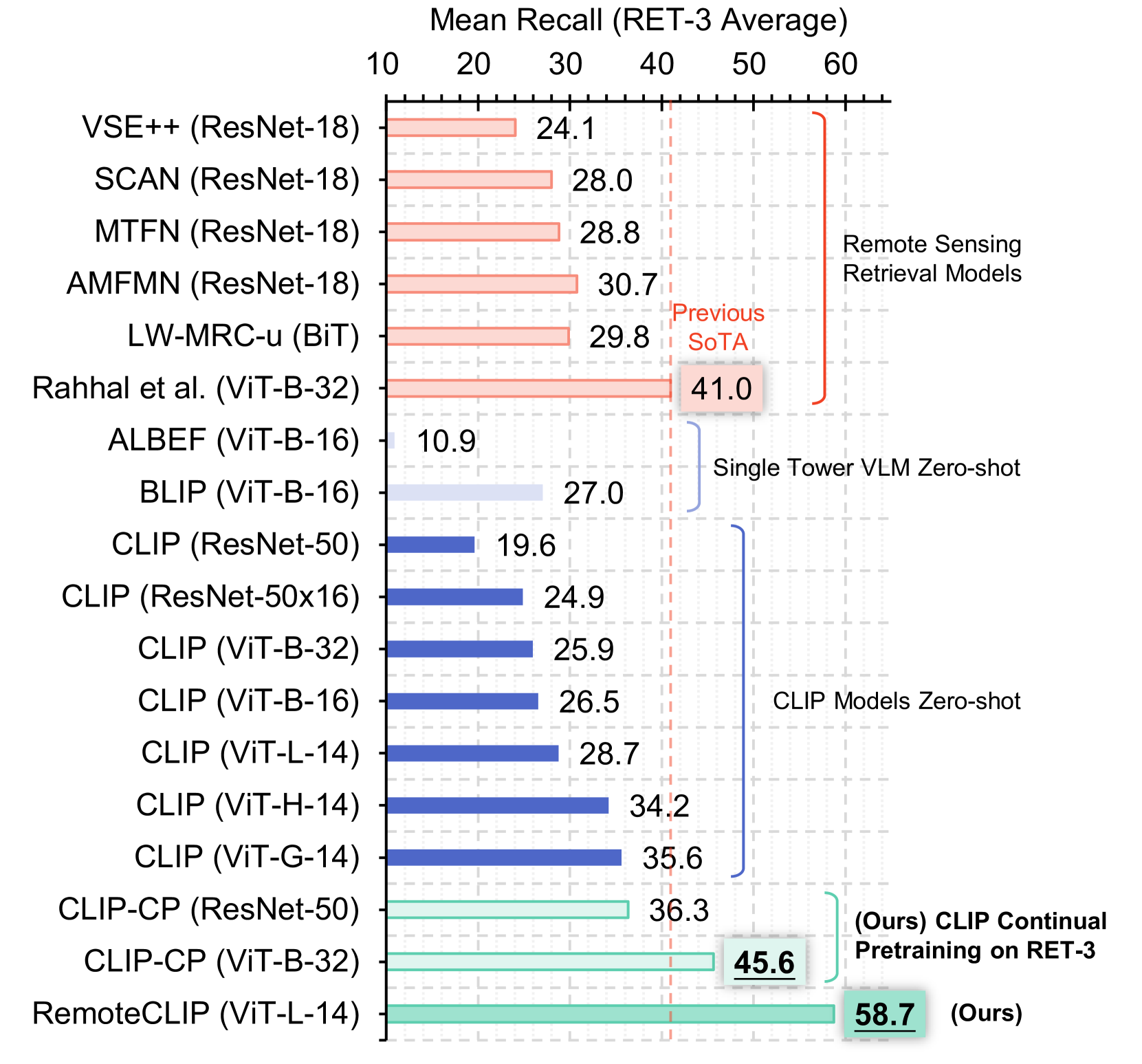
RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
Fan Liu, Delong Chen, Zhangqingyun Guan, Xiaocong Zhou, Jiale Zhu, Qiaolin Ye, Liyong Fu, Jun Zhou
General-purpose foundation models have led to recent breakthroughs in artificial intelligence. In remote sensing, self-supervised learning (SSL) and Masked Image Modeling (MIM) have been adopted to build foundation models. However, these models primarily learn low-level features and require annotated data for fine-tuning. Moreover, they are inapplicable for retrieval and zero-shot applications due to the lack of language understanding. To address these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics and aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling which converts heterogeneous annotations into a unified image-caption data format based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion. By further incorporating UAV imagery, we produce a 12 $times$ larger pretraining dataset than the combination of all available datasets. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, $textit{k}$-NN classification, few-shot classification, image-text retrieval, and object counting in remote sensing images. Evaluation on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, shows that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP beats the state-of-the-art method by 9.14% mean recall on the RSITMD dataset and 8.92% on the RSICD dataset. For zero-shot classification, our RemoteCLIP outperforms the CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. Project website: https://github.com/ChenDelong1999/RemoteCLIP
Read more4/17/2024