RemoteCLIP: A Vision Language Foundation Model for Remote Sensing
2306.11029
0
0
Abstract
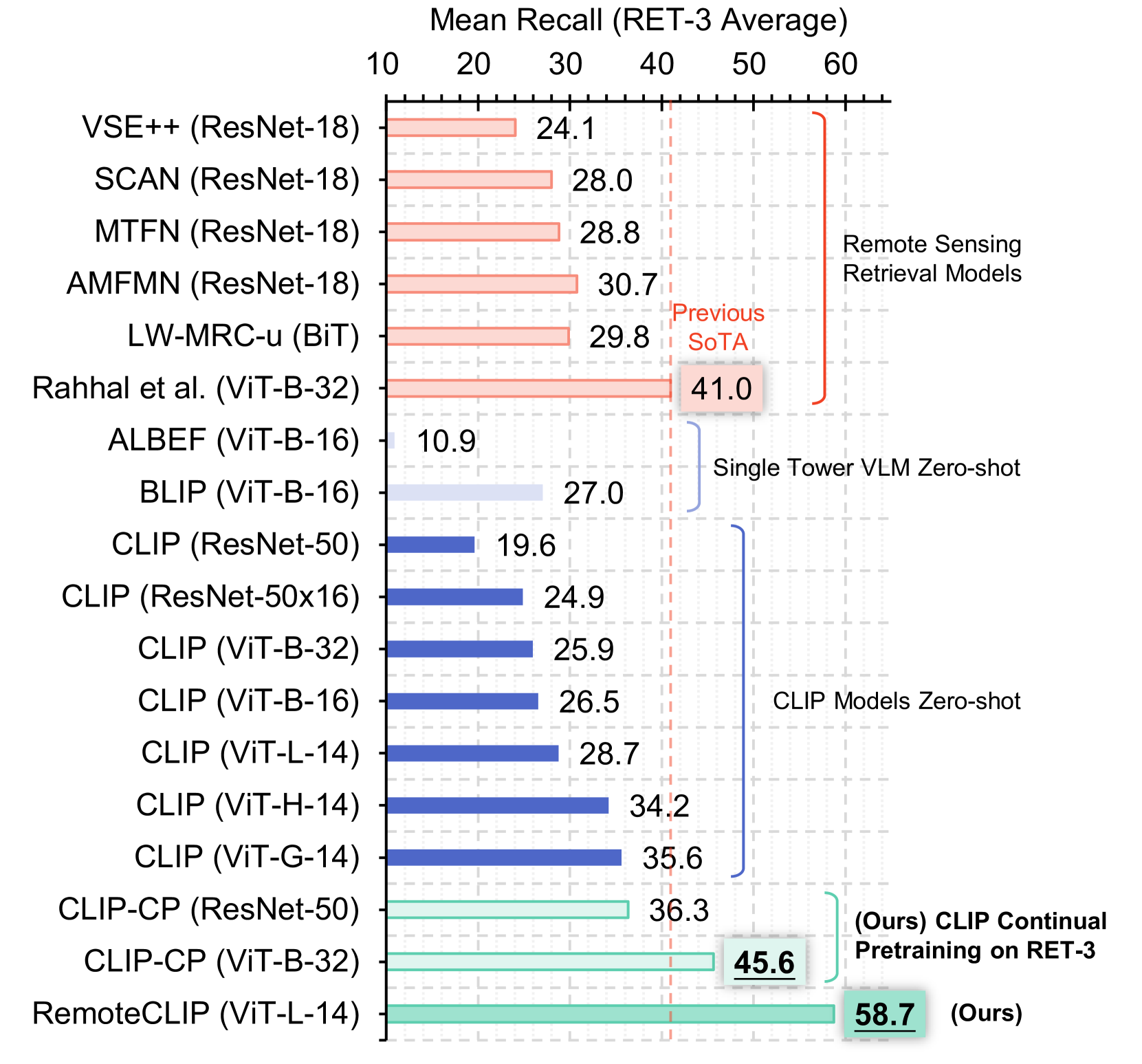
General-purpose foundation models have led to recent breakthroughs in artificial intelligence. In remote sensing, self-supervised learning (SSL) and Masked Image Modeling (MIM) have been adopted to build foundation models. However, these models primarily learn low-level features and require annotated data for fine-tuning. Moreover, they are inapplicable for retrieval and zero-shot applications due to the lack of language understanding. To address these limitations, we propose RemoteCLIP, the first vision-language foundation model for remote sensing that aims to learn robust visual features with rich semantics and aligned text embeddings for seamless downstream application. To address the scarcity of pre-training data, we leverage data scaling which converts heterogeneous annotations into a unified image-caption data format based on Box-to-Caption (B2C) and Mask-to-Box (M2B) conversion. By further incorporating UAV imagery, we produce a 12 $times$ larger pretraining dataset than the combination of all available datasets. RemoteCLIP can be applied to a variety of downstream tasks, including zero-shot image classification, linear probing, $textit{k}$-NN classification, few-shot classification, image-text retrieval, and object counting in remote sensing images. Evaluation on 16 datasets, including a newly introduced RemoteCount benchmark to test the object counting ability, shows that RemoteCLIP consistently outperforms baseline foundation models across different model scales. Impressively, RemoteCLIP beats the state-of-the-art method by 9.14% mean recall on the RSITMD dataset and 8.92% on the RSICD dataset. For zero-shot classification, our RemoteCLIP outperforms the CLIP baseline by up to 6.39% average accuracy on 12 downstream datasets. Project website: https://github.com/ChenDelong1999/RemoteCLIP
Create account to get full access
Overview
- This paper introduces RemoteCLIP, a vision-language foundation model specifically designed for remote sensing applications.
- RemoteCLIP is based on the popular CLIP (Contrastive Language-Image Pre-training) model, but with modifications to better handle the unique challenges of remote sensing data.
- The model is trained on a large dataset of remote sensing images and corresponding captions, enabling it to learn robust visual-linguistic representations for a variety of remote sensing tasks.
Plain English Explanation
RemoteCLIP is a new type of artificial intelligence (AI) model that can understand and work with images and text related to remote sensing. Remote sensing is the process of collecting information about the Earth's surface from a distance, usually using satellites or drones.
The RemoteCLIP model is built on top of an existing AI model called CLIP, which has been very successful at learning how images and text are related. However, the RemoteCLIP model has been specially designed to work with the unique characteristics of remote sensing data, such as the high resolution and complex content of satellite images.
By training RemoteCLIP on a large dataset of remote sensing images and their descriptions, the model has learned to understand the visual patterns and language used in this domain. This allows it to perform a variety of tasks, such as identifying objects in satellite images, describing the contents of remote sensing images, or connecting satellite data to relevant text.
The key idea behind RemoteCLIP is to take the powerful capabilities of CLIP and adapt them to the specific needs of remote sensing applications. This allows the model to leverage the latest advancements in vision-language AI while still being tailored to the unique challenges of working with remote sensing data.
Technical Explanation
RemoteCLIP is a vision-language foundation model that builds upon the success of the CLIP model to better suit the needs of remote sensing applications. The model is trained on a large dataset of remote sensing images and their corresponding captions, allowing it to learn robust visual-linguistic representations for this domain.
The key modifications to the standard CLIP architecture include:
- Specialized image encoder: The image encoder is fine-tuned on remote sensing datasets to better capture the unique visual patterns and characteristics of satellite and aerial imagery.
- Remote sensing-specific pretraining: The model is pretrained on a diverse collection of remote sensing images and captions, enabling it to learn the domain-specific language and visual semantics.
- Task-agnostic design: RemoteCLIP is designed as a general-purpose foundation model, allowing it to be fine-tuned for a variety of remote sensing tasks, such as image captioning, image-text retrieval, and geospatial reasoning.
The authors evaluate RemoteCLIP on several remote sensing benchmarks and demonstrate its superior performance compared to both generic and domain-specific baselines. The model exhibits strong zero-shot generalization capabilities, allowing it to be applied to new tasks and datasets without extensive fine-tuning.
Critical Analysis
The RemoteCLIP paper presents a compelling approach to adapting the CLIP model to the unique challenges of remote sensing applications. By leveraging the robust visual-linguistic representations learned by CLIP and fine-tuning the model on remote sensing data, the authors have created a versatile foundation model that can be applied to a wide range of remote sensing tasks.
One potential limitation of the research is the lack of a detailed analysis of the model's performance on specific remote sensing tasks, such as object detection or geospatial analysis. While the paper demonstrates the model's strong zero-shot performance, a more in-depth exploration of its capabilities and limitations in different remote sensing scenarios would be valuable.
Additionally, the authors could have delved deeper into the unique challenges of remote sensing data, such as the high resolution, complex spatial relationships, and potential domain shift between training and deployment environments. A more thorough discussion of how RemoteCLIP addresses these challenges would further strengthen the paper's contribution.
Despite these minor limitations, the RemoteCLIP research represents an important step forward in the application of vision-language models to the field of remote sensing. The model's versatility and strong performance on benchmark tasks suggest that it could have a significant impact on a wide range of remote sensing applications, from satellite image analysis to aerial imagery interpretation.
Conclusion
The RemoteCLIP paper introduces a novel vision-language foundation model that is specifically designed for remote sensing applications. By adapting the popular CLIP model to the unique characteristics of remote sensing data, the authors have created a versatile and high-performing AI system that can be applied to a variety of tasks in this domain.
The key contributions of this research include the specialized image encoder, remote sensing-specific pretraining, and the model's task-agnostic design, which allows it to be fine-tuned for different remote sensing applications. The strong zero-shot performance demonstrated by RemoteCLIP suggests that it could have a significant impact on the way remote sensing data is analyzed and interpreted, potentially leading to advancements in areas such as satellite image captioning, geospatial reasoning, and remote sensing-driven decision making.
Overall, the RemoteCLIP research represents an important step forward in the application of vision-language AI to the field of remote sensing, and its findings could have far-reaching implications for how we understand and interact with our planet from a distance.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
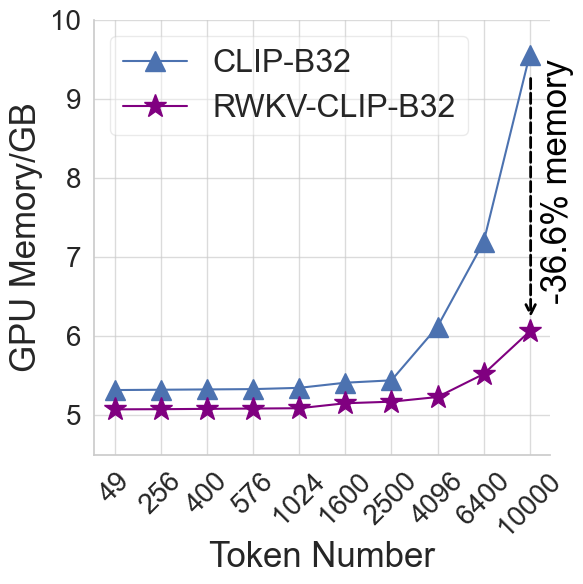
RWKV-CLIP: A Robust Vision-Language Representation Learner
Tiancheng Gu, Kaicheng Yang, Xiang An, Ziyong Feng, Dongnan Liu, Weidong Cai, Jiankang Deng
0
0
Contrastive Language-Image Pre-training (CLIP) has significantly improved performance in various vision-language tasks by expanding the dataset with image-text pairs obtained from websites. This paper further explores CLIP from the perspectives of data and model architecture. To address the prevalence of noisy data and enhance the quality of large-scale image-text data crawled from the internet, we introduce a diverse description generation framework that can leverage Large Language Models (LLMs) to synthesize and refine content from web-based texts, synthetic captions, and detection tags. Furthermore, we propose RWKV-CLIP, the first RWKV-driven vision-language representation learning model that combines the effective parallel training of transformers with the efficient inference of RNNs. Comprehensive experiments across various model scales and pre-training datasets demonstrate that RWKV-CLIP is a robust and efficient vision-language representation learner, it achieves state-of-the-art performance in several downstream tasks, including linear probe, zero-shot classification, and zero-shot image-text retrieval. To facilitate future research, the code and pre-trained models are released at https://github.com/deepglint/RWKV-CLIP
6/12/2024

RankCLIP: Ranking-Consistent Language-Image Pretraining
Yiming Zhang, Zhuokai Zhao, Zhaorun Chen, Zhili Feng, Zenghui Ding, Yining Sun
0
0
Self-supervised contrastive learning models, such as CLIP, have set new benchmarks for vision-language models in many downstream tasks. However, their dependency on rigid one-to-one mappings overlooks the complex and often multifaceted relationships between and within texts and images. To this end, we introduce RANKCLIP, a novel pretraining method that extends beyond the rigid one-to-one matching framework of CLIP and its variants. By extending the traditional pair-wise loss to list-wise, and leveraging both in-modal and cross-modal ranking consistency, RANKCLIP improves the alignment process, enabling it to capture the nuanced many-to-many relationships between and within each modality. Through comprehensive experiments, we demonstrate the effectiveness of RANKCLIP in various downstream tasks, notably achieving significant gains in zero-shot classifications over state-of-the-art methods, underscoring the importance of this enhanced learning process.
6/21/2024
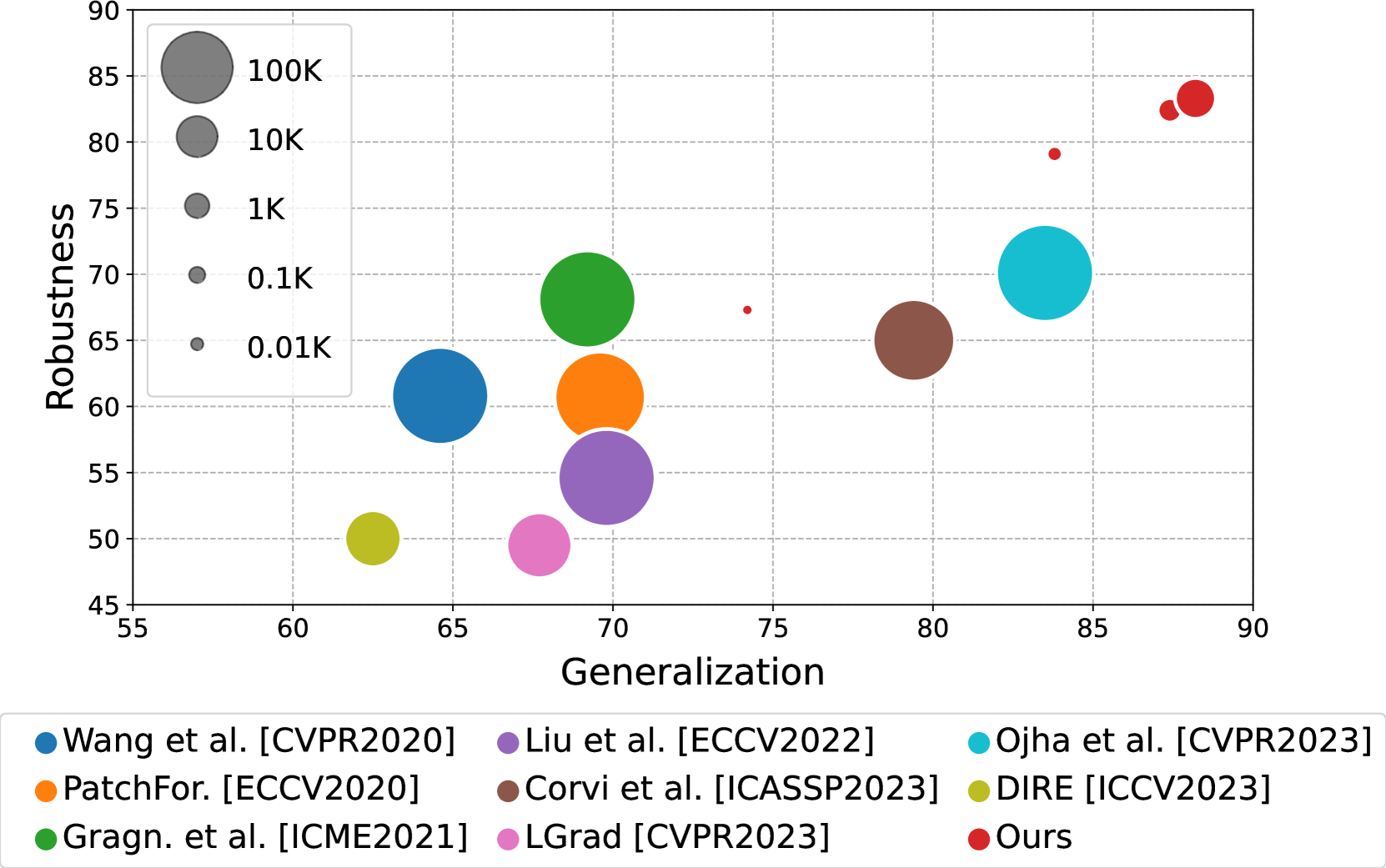
Raising the Bar of AI-generated Image Detection with CLIP
Davide Cozzolino, Giovanni Poggi, Riccardo Corvi, Matthias Nie{ss}ner, Luisa Verdoliva
0
0
The aim of this work is to explore the potential of pre-trained vision-language models (VLMs) for universal detection of AI-generated images. We develop a lightweight detection strategy based on CLIP features and study its performance in a wide variety of challenging scenarios. We find that, contrary to previous beliefs, it is neither necessary nor convenient to use a large domain-specific dataset for training. On the contrary, by using only a handful of example images from a single generative model, a CLIP-based detector exhibits surprising generalization ability and high robustness across different architectures, including recent commercial tools such as Dalle-3, Midjourney v5, and Firefly. We match the state-of-the-art (SoTA) on in-distribution data and significantly improve upon it in terms of generalization to out-of-distribution data (+6% AUC) and robustness to impaired/laundered data (+13%). Our project is available at https://grip-unina.github.io/ClipBased-SyntheticImageDetection/
4/30/2024
🛸
Cascade-CLIP: Cascaded Vision-Language Embeddings Alignment for Zero-Shot Semantic Segmentation
Yunheng Li, ZhongYu Li, Quansheng Zeng, Qibin Hou, Ming-Ming Cheng
0
0
Pre-trained vision-language models, e.g., CLIP, have been successfully applied to zero-shot semantic segmentation. Existing CLIP-based approaches primarily utilize visual features from the last layer to align with text embeddings, while they neglect the crucial information in intermediate layers that contain rich object details. However, we find that directly aggregating the multi-level visual features weakens the zero-shot ability for novel classes. The large differences between the visual features from different layers make these features hard to align well with the text embeddings. We resolve this problem by introducing a series of independent decoders to align the multi-level visual features with the text embeddings in a cascaded way, forming a novel but simple framework named Cascade-CLIP. Our Cascade-CLIP is flexible and can be easily applied to existing zero-shot semantic segmentation methods. Experimental results show that our simple Cascade-CLIP achieves superior zero-shot performance on segmentation benchmarks, like COCO-Stuff, Pascal-VOC, and Pascal-Context. Our code is available at: https://github.com/HVision-NKU/Cascade-CLIP
6/7/2024