Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
2405.02880
0
0
🛠️
Abstract
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
Create account to get full access
Overview
- The paper addresses the challenge of leveraging distributed Neural Radiance Fields (NeRFs) for modeling large-scale urban environments, which is limited by the model capacity.
- Current distributed NeRF registration approaches suffer from aliasing artifacts due to discrepancies in rendering resolutions and suboptimal pose precision, leading to occlusion artifacts in the NeRF blending stage.
- The proposed system introduces a tri-stage pose optimization approach to achieve precise poses and robust transformations between NeRFs in different coordinate systems.
Plain English Explanation
NeRFs are a powerful technique for creating 3D models from images, but they can struggle when trying to model large, complex environments like cities. This is because the model capacity of a single NeRF can be limited, making it difficult to capture all the details.
To overcome this, the researchers in this paper propose a distributed NeRF system, where multiple NeRFs are used to model different parts of the environment. However, this introduces some challenges. When you combine the different NeRFs, there can be issues with the alignment of the models, leading to visual artifacts like blurriness or missing parts.
The key innovation in this paper is a three-step process to optimize the poses (positions and orientations) of the images used to create the NeRFs. First, they use a coarse-to-fine strategy to precisely align the images in each NeRF. Then, they incorporate an "inverted" NeRF model and a special filtering technique to further refine the poses and find the transformation between NeRFs in different coordinate systems. Finally, they fine-tune this transformation to get the best possible alignment between the NeRFs.
With these optimized poses and transformations, the researchers can then blend the NeRFs together to create a high-quality, seamless 3D model of the entire environment. This approach shows promising results in both real-world and simulated scenarios.
Technical Explanation
The paper proposes a distributed NeRF system with a tri-stage pose optimization approach to address the challenges of modeling large-scale urban environments.
In the first stage, the researchers use a coarse-to-fine strategy with bundle adjustment to precisely align the images within each NeRF using Mip-NeRF 360.
Next, they incorporate the inverted Mip-NeRF 360 and a truncated dynamic low-pass filter to achieve robust and precise poses, a process they call "Frame2Model optimization." This enables them to find the coarse transformation between NeRFs in different coordinate systems.
In the third stage, the researchers fine-tune the transformation between NeRFs using a "Model2Model pose optimization" approach.
After obtaining the precise transformation parameters, the researchers implement NeRF blending, which demonstrates superior performance metrics in both real-world and simulation scenarios.
Critical Analysis
The paper addresses an important challenge in the field of large-scale 3D modeling using NeRFs. The proposed tri-stage pose optimization approach seems to be an effective solution, as evidenced by the reported performance improvements.
However, the paper does not discuss the computational complexity and runtime of the proposed method. As the system involves multiple optimization stages, it may have a higher computational cost compared to simpler NeRF registration approaches. The researchers could have provided more insights into the tradeoffs between the method's accuracy and its practical implementation.
Additionally, the paper does not explore the generalizability of the approach to other types of environments beyond urban scenes. It would be interesting to see how the method performs in modeling more diverse and complex scenes, such as natural landscapes or indoor environments.
Further research could also investigate the robustness of the system to noise, occlusions, or other challenging conditions that may be present in real-world scenarios. Exploring ways to make the pose optimization more efficient or scalable would also be valuable for practical applications.
Conclusion
This paper presents a novel distributed NeRF system with a tri-stage pose optimization approach to address the challenges of modeling large-scale urban environments. By precisely aligning the images within each NeRF and optimizing the transformations between them, the researchers have demonstrated a significant improvement in the quality and fidelity of the resulting 3D models.
The proposed method has the potential to expand the capabilities of NeRF-based 3D modeling, enabling the creation of high-quality, seamless representations of extensive urban areas. This could have important applications in fields such as urban planning, navigation, and virtual tourism. The code and data for this research will be made publicly available, which will allow other researchers to build upon these advancements and further push the boundaries of large-scale 3D modeling.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
Yunlong Ran, Yanxu Li, Qi Ye, Yuchi Huo, Zechun Bai, Jiahao Sun, Jiming Chen
0
0
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
4/24/2024
🧠
TD-NeRF: Novel Truncated Depth Prior for Joint Camera Pose and Neural Radiance Field Optimization
Zhen Tan, Zongtan Zhou, Yangbing Ge, Zi Wang, Xieyuanli Chen, Dewen Hu
0
0
The reliance on accurate camera poses is a significant barrier to the widespread deployment of Neural Radiance Fields (NeRF) models for 3D reconstruction and SLAM tasks. The existing method introduces monocular depth priors to jointly optimize the camera poses and NeRF, which fails to fully exploit the depth priors and neglects the impact of their inherent noise. In this paper, we propose Truncated Depth NeRF (TD-NeRF), a novel approach that enables training NeRF from unknown camera poses - by jointly optimizing learnable parameters of the radiance field and camera poses. Our approach explicitly utilizes monocular depth priors through three key advancements: 1) we propose a novel depth-based ray sampling strategy based on the truncated normal distribution, which improves the convergence speed and accuracy of pose estimation; 2) to circumvent local minima and refine depth geometry, we introduce a coarse-to-fine training strategy that progressively improves the depth precision; 3) we propose a more robust inter-frame point constraint that enhances robustness against depth noise during training. The experimental results on three datasets demonstrate that TD-NeRF achieves superior performance in the joint optimization of camera pose and NeRF, surpassing prior works, and generates more accurate depth geometry. The implementation of our method has been released at https://github.com/nubot-nudt/TD-NeRF.
5/14/2024
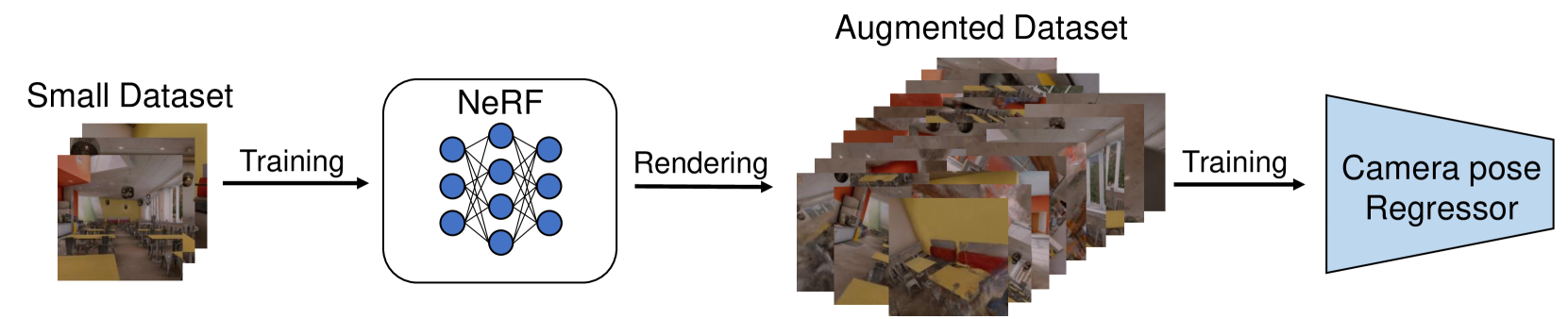
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Juyeop Han, Lukas Lao Beyer, Guilherme V. Cavalheiro, Sertac Karaman
0
0
In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
4/3/2024

Generative Lifting of Multiview to 3D from Unknown Pose: Wrapping NeRF inside Diffusion
Xin Yuan, Rana Hanocka, Michael Maire
0
0
We cast multiview reconstruction from unknown pose as a generative modeling problem. From a collection of unannotated 2D images of a scene, our approach simultaneously learns both a network to predict camera pose from 2D image input, as well as the parameters of a Neural Radiance Field (NeRF) for the 3D scene. To drive learning, we wrap both the pose prediction network and NeRF inside a Denoising Diffusion Probabilistic Model (DDPM) and train the system via the standard denoising objective. Our framework requires the system accomplish the task of denoising an input 2D image by predicting its pose and rendering the NeRF from that pose. Learning to denoise thus forces the system to concurrently learn the underlying 3D NeRF representation and a mapping from images to camera extrinsic parameters. To facilitate the latter, we design a custom network architecture to represent pose as a distribution, granting implicit capacity for discovering view correspondences when trained end-to-end for denoising alone. This technique allows our system to successfully build NeRFs, without pose knowledge, for challenging scenes where competing methods fail. At the conclusion of training, our learned NeRF can be extracted and used as a 3D scene model; our full system can be used to sample novel camera poses and generate novel-view images.
6/12/2024