CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
2404.13896
0
0

Abstract
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
Create account to get full access
Overview
- Presents CT-NeRF, a method for incrementally optimizing neural radiance fields (NeRFs) and camera poses with complex trajectories
- Addresses limitations of existing NeRF approaches that assume simple camera trajectories
- Introduces a novel representation and optimization strategy to handle more complex scenarios
Plain English Explanation
CT-NeRF is a technique for creating 3D models from images that can handle more complex camera movements than previous methods. Existing neural radiance field (NeRF) approaches work well when the camera follows a simple path, but struggle with more complex trajectories.
The key idea behind CT-NeRF is to represent the 3D scene using a neural network that can adapt to changes in the camera position and orientation over time. This allows the model to handle scenarios where the camera moves in a more complicated way, such as circling around an object or following a winding path.
The researchers introduce a novel optimization strategy to efficiently update the NeRF representation and camera poses as new images are captured. This incremental approach is more efficient than re-optimizing the entire scene from scratch each time, making CT-NeRF well-suited for applications where the camera is constantly moving, like robotics or augmented reality.
Technical Explanation
CT-NeRF builds upon the NeRF representation, which models a 3D scene as a continuous function that maps spatial coordinates and viewing directions to volume density and color. However, standard NeRF assumes a simple, linear camera trajectory, which limits its applicability to more complex scenarios.
To address this, CT-NeRF introduces a new scene representation that incorporates the camera's trajectory over time. The radiance field is conditioned on both the spatial coordinates and the camera's position and orientation at a given time. This allows the model to adapt to changes in the camera's movement.
The researchers also develop an incremental optimization strategy, where the NeRF and camera poses are updated jointly as new images are captured. This is more efficient than re-optimizing the entire scene from scratch each time, making CT-NeRF suitable for applications with complex, continuously changing camera trajectories.
Experiments on both synthetic and real-world datasets demonstrate that CT-NeRF can handle a wider range of camera movements compared to standard NeRF, while maintaining high-quality 3D reconstructions. The method shows promising results for applications like robotic navigation and mixed reality, where the camera often follows non-trivial trajectories.
Critical Analysis
The key strength of CT-NeRF is its ability to handle complex camera trajectories, which expands the applicability of NeRF-based approaches. However, the paper does not explore the limits of this capability, and it would be interesting to see how CT-NeRF performs on extremely complex or chaotic camera movements.
Additionally, the paper focuses on the core technical contributions and does not provide a detailed analysis of the computational and memory requirements of the method. As with any neural network-based approach, the efficiency and scalability of CT-NeRF may be an important consideration, especially for real-time applications.
While the experiments demonstrate the effectiveness of CT-NeRF on various datasets, it would be valuable to see further validation on a broader range of scenarios, including more challenging real-world environments. Exploring the method's robustness to noise, occlusions, and other real-world complications would help assess its practical applicability.
Conclusion
CT-NeRF is a significant advancement in the field of neural radiance field-based 3D reconstruction, addressing the limitation of existing NeRF approaches in handling complex camera trajectories. By incorporating the camera's position and orientation into the scene representation, CT-NeRF can adapt to a wider range of camera movements, opening up new possibilities for applications in robotics, augmented reality, and beyond.
The incremental optimization strategy is a key innovation that enables CT-NeRF to efficiently update the 3D model as new images are captured, making it well-suited for dynamic environments. While the paper provides a solid technical foundation, further research is needed to fully understand the method's capabilities, limitations, and practical implications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🛠️
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
Baijun Ye, Caiyun Liu, Xiaoyu Ye, Yuantao Chen, Yuhai Wang, Zike Yan, Yongliang Shi, Hao Zhao, Guyue Zhou
0
0
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
5/7/2024
🧠
TD-NeRF: Novel Truncated Depth Prior for Joint Camera Pose and Neural Radiance Field Optimization
Zhen Tan, Zongtan Zhou, Yangbing Ge, Zi Wang, Xieyuanli Chen, Dewen Hu
0
0
The reliance on accurate camera poses is a significant barrier to the widespread deployment of Neural Radiance Fields (NeRF) models for 3D reconstruction and SLAM tasks. The existing method introduces monocular depth priors to jointly optimize the camera poses and NeRF, which fails to fully exploit the depth priors and neglects the impact of their inherent noise. In this paper, we propose Truncated Depth NeRF (TD-NeRF), a novel approach that enables training NeRF from unknown camera poses - by jointly optimizing learnable parameters of the radiance field and camera poses. Our approach explicitly utilizes monocular depth priors through three key advancements: 1) we propose a novel depth-based ray sampling strategy based on the truncated normal distribution, which improves the convergence speed and accuracy of pose estimation; 2) to circumvent local minima and refine depth geometry, we introduce a coarse-to-fine training strategy that progressively improves the depth precision; 3) we propose a more robust inter-frame point constraint that enhances robustness against depth noise during training. The experimental results on three datasets demonstrate that TD-NeRF achieves superior performance in the joint optimization of camera pose and NeRF, surpassing prior works, and generates more accurate depth geometry. The implementation of our method has been released at https://github.com/nubot-nudt/TD-NeRF.
5/14/2024

CTNeRF: Cross-Time Transformer for Dynamic Neural Radiance Field from Monocular Video
Xingyu Miao, Yang Bai, Haoran Duan, Yawen Huang, Fan Wan, Yang Long, Yefeng Zheng
0
0
The goal of our work is to generate high-quality novel views from monocular videos of complex and dynamic scenes. Prior methods, such as DynamicNeRF, have shown impressive performance by leveraging time-varying dynamic radiation fields. However, these methods have limitations when it comes to accurately modeling the motion of complex objects, which can lead to inaccurate and blurry renderings of details. To address this limitation, we propose a novel approach that builds upon a recent generalization NeRF, which aggregates nearby views onto new viewpoints. However, such methods are typically only effective for static scenes. To overcome this challenge, we introduce a module that operates in both the time and frequency domains to aggregate the features of object motion. This allows us to learn the relationship between frames and generate higher-quality images. Our experiments demonstrate significant improvements over state-of-the-art methods on dynamic scene datasets. Specifically, our approach outperforms existing methods in terms of both the accuracy and visual quality of the synthesized views. Our code is available on https://github.com/xingy038/CTNeRF.
6/27/2024
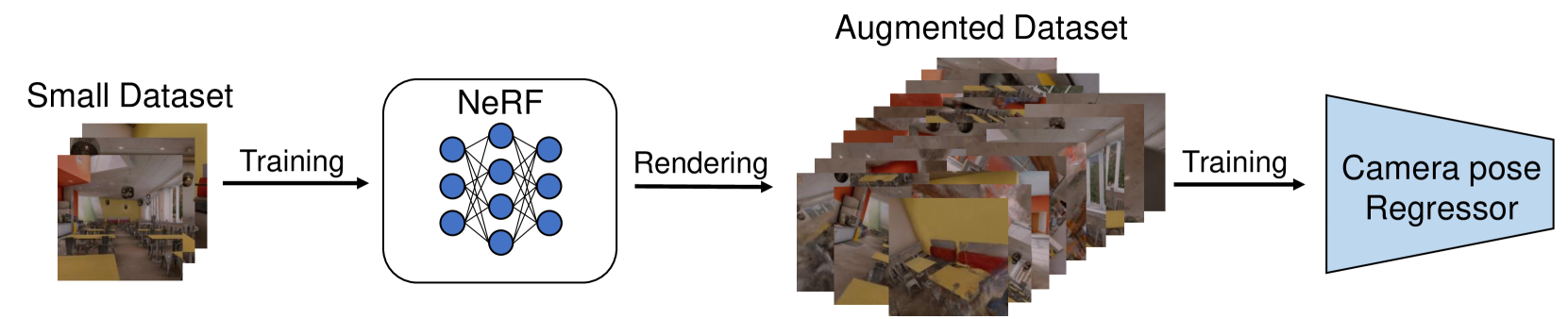
NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
Juyeop Han, Lukas Lao Beyer, Guilherme V. Cavalheiro, Sertac Karaman
0
0
In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
4/3/2024