NVINS: Robust Visual Inertial Navigation Fused with NeRF-augmented Camera Pose Regressor and Uncertainty Quantification
2404.01400
0
0
Abstract
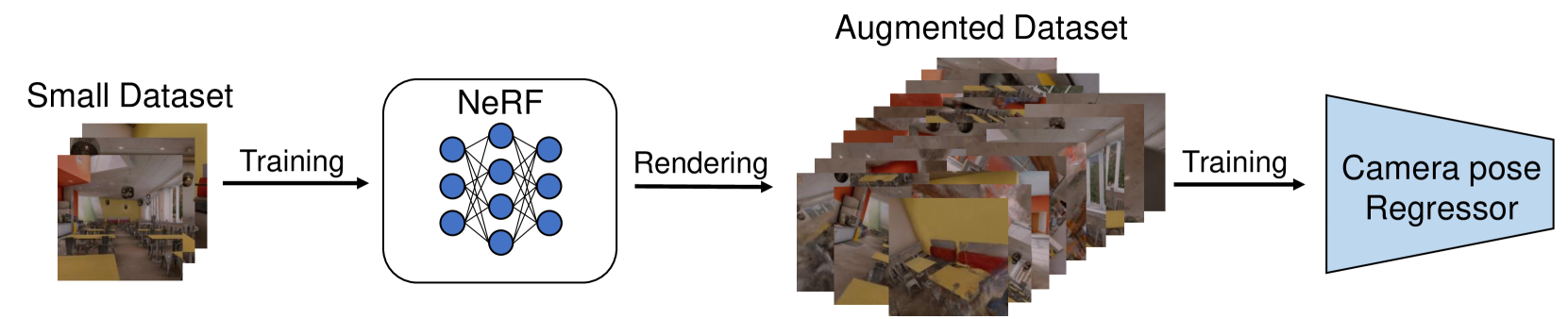
In recent years, Neural Radiance Fields (NeRF) have emerged as a powerful tool for 3D reconstruction and novel view synthesis. However, the computational cost of NeRF rendering and degradation in quality due to the presence of artifacts pose significant challenges for its application in real-time and robust robotic tasks, especially on embedded systems. This paper introduces a novel framework that integrates NeRF-derived localization information with Visual-Inertial Odometry(VIO) to provide a robust solution for robotic navigation in a real-time. By training an absolute pose regression network with augmented image data rendered from a NeRF and quantifying its uncertainty, our approach effectively counters positional drift and enhances system reliability. We also establish a mathematically sound foundation for combining visual inertial navigation with camera localization neural networks, considering uncertainty under a Bayesian framework. Experimental validation in the photorealistic simulation environment demonstrates significant improvements in accuracy compared to a conventional VIO approach.
Create account to get full access
Overview
- This paper proposes a robust visual-inertial navigation system (NVINS) that fuses data from cameras and inertial measurement units (IMUs) to accurately track the pose (position and orientation) of a mobile device.
- NVINS improves upon existing approaches by incorporating a neural radiance field (NeRF) model to enhance the camera pose regression and provide uncertainty quantification.
- The system is designed to work reliably in challenging environments with dynamic objects and occlusions.
Plain English Explanation
NVINS is a technology that helps determine the exact location and orientation of a camera or other mobile device as it moves around. It does this by combining information from two different types of sensors:
- Cameras - These capture images of the surrounding environment.
- Inertial measurement units (IMUs) - These detect the device's motion, such as acceleration and rotation.
By fusing the data from these sensors, NVINS can track the device's position and orientation very accurately, even in complex environments with moving objects or partial visibility. This is important for applications like augmented reality, robotics, and autonomous vehicles.
The key innovation in NVINS is the use of a neural radiance field (NeRF) model. NeRF is an AI technique that can create a detailed 3D representation of a scene from just a few photos. NVINS leverages this NeRF model to improve the camera pose estimation - that is, the calculation of where the camera is located and which direction it is pointing. The NeRF model also provides information about the uncertainty in these pose estimates, which is crucial for making the overall navigation system more robust.
Technical Explanation
The NVINS system consists of three main components:
-
Visual-Inertial Odometry (VIO): This module fuses the camera and IMU data to estimate the 6-DoF (degree-of-freedom) pose of the device over time. It uses advanced optimization techniques to handle sensor noise and biases.
-
NeRF-augmented Camera Pose Regressor: A deep neural network is trained to predict the camera pose from the current image and previous poses. The network is enhanced with a NeRF model, which provides additional spatial and appearance cues to improve the pose estimation.
-
Uncertainty Quantification: The NeRF model also outputs uncertainty estimates for the predicted camera poses. These uncertainty values are then integrated into the overall NVINS system to make it more robust to errors and better able to handle challenging environments.
The paper presents extensive experimental evaluations of NVINS on both simulated and real-world datasets. The results demonstrate significant improvements in localization accuracy and robustness compared to state-of-the-art visual-inertial odometry approaches.
Critical Analysis
The NVINS system represents an innovative and promising approach to visual-inertial navigation. The incorporation of the NeRF model is a clever way to leverage advancements in 3D scene representation to enhance the core pose estimation capabilities.
However, the paper does not discuss the computational complexity and runtime performance of the system. The NeRF model in particular could be computationally intensive, which may limit its usability in real-time applications with limited processing power, such as mobile devices.
Additionally, the paper does not provide in-depth analysis of the failure modes and limitations of the NVINS system. It would be helpful to understand the types of environments or situations where the system may struggle, and what steps could be taken to further improve its robustness.
Conclusion
The NVINS system proposed in this paper presents a novel approach to visual-inertial navigation that combines state-of-the-art techniques in 6-DoF pose estimation, 3D scene representation, and uncertainty quantification. By fusing camera, IMU, and NeRF data, the system is able to achieve robust and accurate localization performance, even in challenging environments.
While there are some open questions regarding the computational efficiency and limitations of the approach, the overall concept and demonstrated results suggest that NVINS could have significant impact on a wide range of applications, from augmented reality to autonomous robotics, where reliable and accurate spatial awareness is crucial.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🧠
Novel View Synthesis with Neural Radiance Fields for Industrial Robot Applications
Markus Hillemann, Robert Langendorfer, Max Heiken, Max Mehltretter, Andreas Schenk, Martin Weinmann, Stefan Hinz, Christian Heipke, Markus Ulrich
0
0
Neural Radiance Fields (NeRFs) have become a rapidly growing research field with the potential to revolutionize typical photogrammetric workflows, such as those used for 3D scene reconstruction. As input, NeRFs require multi-view images with corresponding camera poses as well as the interior orientation. In the typical NeRF workflow, the camera poses and the interior orientation are estimated in advance with Structure from Motion (SfM). But the quality of the resulting novel views, which depends on different parameters such as the number and distribution of available images, as well as the accuracy of the related camera poses and interior orientation, is difficult to predict. In addition, SfM is a time-consuming pre-processing step, and its quality strongly depends on the image content. Furthermore, the undefined scaling factor of SfM hinders subsequent steps in which metric information is required. In this paper, we evaluate the potential of NeRFs for industrial robot applications. We propose an alternative to SfM pre-processing: we capture the input images with a calibrated camera that is attached to the end effector of an industrial robot and determine accurate camera poses with metric scale based on the robot kinematics. We then investigate the quality of the novel views by comparing them to ground truth, and by computing an internal quality measure based on ensemble methods. For evaluation purposes, we acquire multiple datasets that pose challenges for reconstruction typical of industrial applications, like reflective objects, poor texture, and fine structures. We show that the robot-based pose determination reaches similar accuracy as SfM in non-demanding cases, while having clear advantages in more challenging scenarios. Finally, we present first results of applying the ensemble method to estimate the quality of the synthetic novel view in the absence of a ground truth.
5/8/2024

CT-NeRF: Incremental Optimizing Neural Radiance Field and Poses with Complex Trajectory
Yunlong Ran, Yanxu Li, Qi Ye, Yuchi Huo, Zechun Bai, Jiahao Sun, Jiming Chen
0
0
Neural radiance field (NeRF) has achieved impressive results in high-quality 3D scene reconstruction. However, NeRF heavily relies on precise camera poses. While recent works like BARF have introduced camera pose optimization within NeRF, their applicability is limited to simple trajectory scenes. Existing methods struggle while tackling complex trajectories involving large rotations. To address this limitation, we propose CT-NeRF, an incremental reconstruction optimization pipeline using only RGB images without pose and depth input. In this pipeline, we first propose a local-global bundle adjustment under a pose graph connecting neighboring frames to enforce the consistency between poses to escape the local minima caused by only pose consistency with the scene structure. Further, we instantiate the consistency between poses as a reprojected geometric image distance constraint resulting from pixel-level correspondences between input image pairs. Through the incremental reconstruction, CT-NeRF enables the recovery of both camera poses and scene structure and is capable of handling scenes with complex trajectories. We evaluate the performance of CT-NeRF on two real-world datasets, NeRFBuster and Free-Dataset, which feature complex trajectories. Results show CT-NeRF outperforms existing methods in novel view synthesis and pose estimation accuracy.
4/24/2024
🛠️
Blending Distributed NeRFs with Tri-stage Robust Pose Optimization
Baijun Ye, Caiyun Liu, Xiaoyu Ye, Yuantao Chen, Yuhai Wang, Zike Yan, Yongliang Shi, Hao Zhao, Guyue Zhou
0
0
Due to the limited model capacity, leveraging distributed Neural Radiance Fields (NeRFs) for modeling extensive urban environments has become a necessity. However, current distributed NeRF registration approaches encounter aliasing artifacts, arising from discrepancies in rendering resolutions and suboptimal pose precision. These factors collectively deteriorate the fidelity of pose estimation within NeRF frameworks, resulting in occlusion artifacts during the NeRF blending stage. In this paper, we present a distributed NeRF system with tri-stage pose optimization. In the first stage, precise poses of images are achieved by bundle adjusting Mip-NeRF 360 with a coarse-to-fine strategy. In the second stage, we incorporate the inverting Mip-NeRF 360, coupled with the truncated dynamic low-pass filter, to enable the achievement of robust and precise poses, termed Frame2Model optimization. On top of this, we obtain a coarse transformation between NeRFs in different coordinate systems. In the third stage, we fine-tune the transformation between NeRFs by Model2Model pose optimization. After obtaining precise transformation parameters, we proceed to implement NeRF blending, showcasing superior performance metrics in both real-world and simulation scenarios. Codes and data will be publicly available at https://github.com/boilcy/Distributed-NeRF.
5/7/2024
VRS-NeRF: Visual Relocalization with Sparse Neural Radiance Field
Fei Xue, Ignas Budvytis, Daniel Olmeda Reino, Roberto Cipolla
0
0
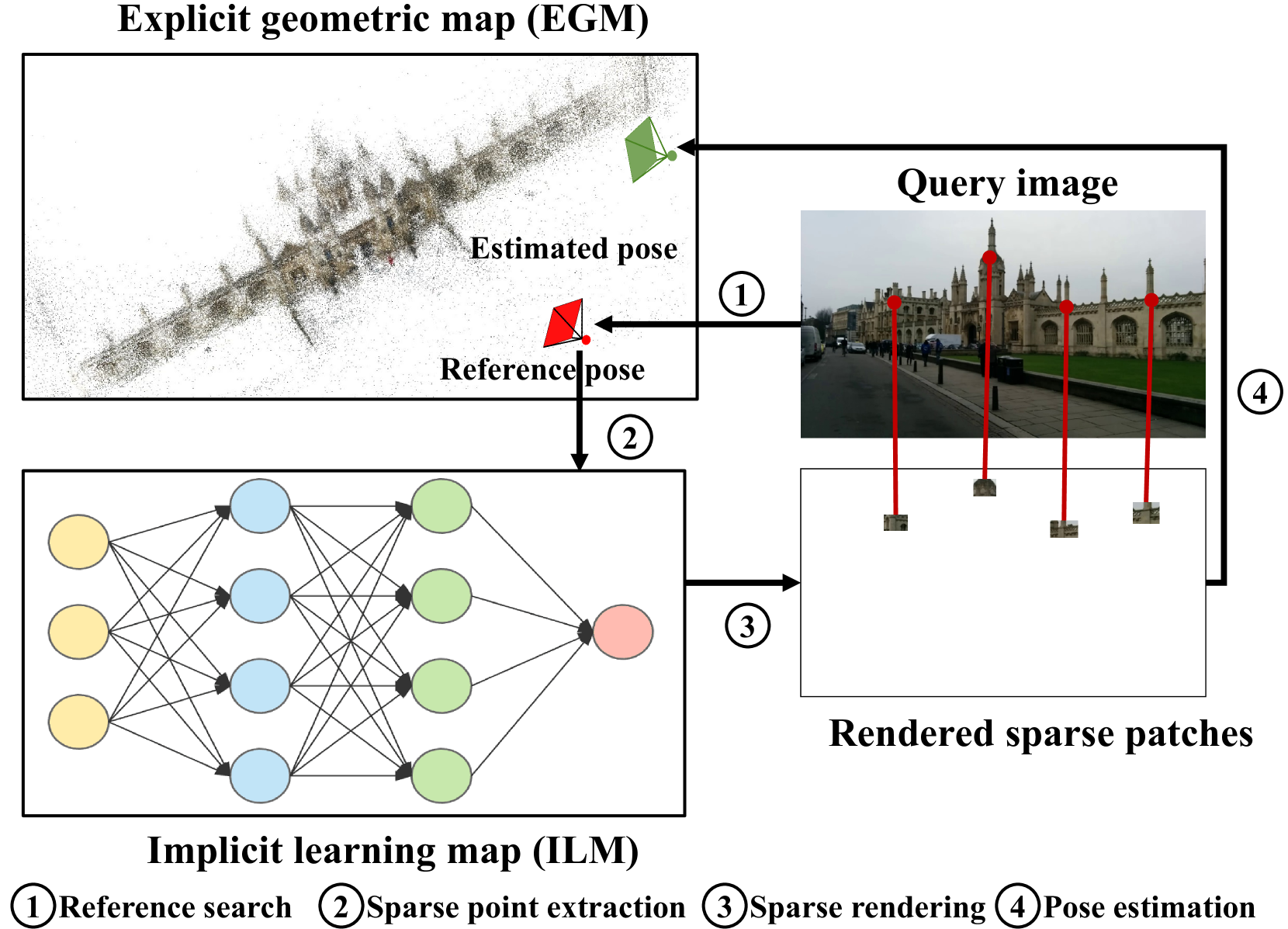
Visual relocalization is a key technique to autonomous driving, robotics, and virtual/augmented reality. After decades of explorations, absolute pose regression (APR), scene coordinate regression (SCR), and hierarchical methods (HMs) have become the most popular frameworks. However, in spite of high efficiency, APRs and SCRs have limited accuracy especially in large-scale outdoor scenes; HMs are accurate but need to store a large number of 2D descriptors for matching, resulting in poor efficiency. In this paper, we propose an efficient and accurate framework, called VRS-NeRF, for visual relocalization with sparse neural radiance field. Precisely, we introduce an explicit geometric map (EGM) for 3D map representation and an implicit learning map (ILM) for sparse patches rendering. In this localization process, EGP provides priors of spare 2D points and ILM utilizes these sparse points to render patches with sparse NeRFs for matching. This allows us to discard a large number of 2D descriptors so as to reduce the map size. Moreover, rendering patches only for useful points rather than all pixels in the whole image reduces the rendering time significantly. This framework inherits the accuracy of HMs and discards their low efficiency. Experiments on 7Scenes, CambridgeLandmarks, and Aachen datasets show that our method gives much better accuracy than APRs and SCRs, and close performance to HMs but is much more efficient.
4/16/2024