BlockPruner: Fine-grained Pruning for Large Language Models
2406.10594
0
0
Abstract
With the rapid growth in the size and complexity of large language models (LLMs), the costs associated with their training and inference have escalated significantly. Research indicates that certain layers in LLMs harbor substantial redundancy, and pruning these layers has minimal impact on the overall performance. While various layer pruning methods have been developed based on this insight, they generally overlook the finer-grained redundancies within the layers themselves. In this paper, we delve deeper into the architecture of LLMs and demonstrate that finer-grained pruning can be achieved by targeting redundancies in multi-head attention (MHA) and multi-layer perceptron (MLP) blocks. We propose a novel, training-free structured pruning approach called BlockPruner. Unlike existing layer pruning methods, BlockPruner segments each Transformer layer into MHA and MLP blocks. It then assesses the importance of these blocks using perplexity measures and applies a heuristic search for iterative pruning. We applied BlockPruner to LLMs of various sizes and architectures and validated its performance across a wide range of downstream tasks. Experimental results show that BlockPruner achieves more granular and effective pruning compared to state-of-the-art baselines.
Create account to get full access
Overview
- This paper introduces BlockPruner, a fine-grained pruning method for large language models (LLMs) that can selectively remove parameters while preserving model performance.
- BlockPruner divides the model into blocks and prunes the blocks that have the least impact on the model's performance, allowing for significant model size reduction without compromising accuracy.
- The researchers demonstrate BlockPruner's effectiveness on a variety of LLMs, including BERT, GPT-2, and T5, achieving up to 70% parameter reduction with minimal performance loss.
Plain English Explanation
Large language models (LLMs) like BERT, GPT-2, and T5 have become incredibly powerful tools for a wide range of natural language processing tasks. However, these models can be extremely large, containing billions of parameters, which makes them computationally expensive and difficult to deploy on resource-constrained devices.
The researchers in this paper have developed a technique called BlockPruner that can significantly reduce the size of these LLMs without compromising their performance. The key idea is to divide the model into smaller "blocks" and then selectively remove the blocks that have the least impact on the model's overall capabilities.
Imagine a complex puzzle, where each block represents a piece of the puzzle. BlockPruner identifies the puzzle pieces that are the least important for the overall picture and removes them, allowing the puzzle to be much smaller without losing its essential structure and functionality.
By pruning the model in this fine-grained, block-level way, the researchers were able to achieve up to 70% reduction in the number of parameters, meaning the model could be much smaller and more efficient, while still maintaining its impressive performance on a variety of language tasks.
This is an important advancement in the field of model compression, as it allows developers to deploy powerful LLMs on a wider range of hardware, including mobile devices and edge computing platforms, without sacrificing the models' capabilities.
Technical Explanation
The BlockPruner method works by dividing the model's parameters into a grid of non-overlapping blocks. For each block, the researchers compute a score that reflects the block's importance to the model's overall performance. They then prune the blocks with the lowest scores, effectively removing the least important parameters from the model.
To compute the block importance scores, the researchers use a novel technique called "gradient-based block importance" (GBI). GBI measures how much the model's performance would change if a given block of parameters was removed, by analyzing the gradients of the model's output with respect to the block's parameters.
The researchers demonstrate BlockPruner's effectiveness on several popular LLMs, including BERT, GPT-2, and T5. They show that BlockPruner can achieve up to 70% parameter reduction with minimal performance loss, outperforming previous pruning methods like FinerCut and Optimization-Based Structural Pruning.
One key insight from the paper is that BlockPruner is able to selectively prune the model in a way that preserves the most important features and relationships, rather than simply removing parameters uniformly across the model. This fine-grained, block-level pruning strategy allows BlockPruner to achieve better performance compared to previous approaches.
Critical Analysis
The BlockPruner paper represents a significant advancement in the field of model compression for large language models. The researchers have developed a novel and effective technique for selectively removing parameters from the model, allowing for substantial size reduction without compromising performance.
One potential limitation of the approach is that the block-level pruning strategy may not be optimal for all types of model architectures or tasks. The researchers primarily evaluated BlockPruner on transformer-based models like BERT and T5, but it's possible that the technique may not be as effective for other types of LLMs or specialized architectures.
Additionally, while the paper demonstrates impressive results in terms of parameter reduction, it would be helpful to see more analysis on the actual computational and memory savings achieved, as well as the real-world implications for deploying the pruned models on different hardware and edge computing platforms.
Overall, the BlockPruner paper makes a valuable contribution to the field of model compression and provides a promising new approach for reducing the size of large language models without sacrificing their performance.
Conclusion
The BlockPruner paper introduces a novel fine-grained pruning technique for large language models that can achieve significant model size reduction without compromising accuracy. By dividing the model into blocks and selectively pruning the least important blocks, the researchers were able to demonstrate up to 70% parameter reduction on popular LLMs like BERT, GPT-2, and T5.
This work represents an important advancement in the field of model compression, as it allows developers to deploy powerful language models on a wider range of hardware, including resource-constrained devices at the edge. The BlockPruner approach could have far-reaching implications for making large language models more accessible and scalable, paving the way for their wider adoption and real-world impact.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
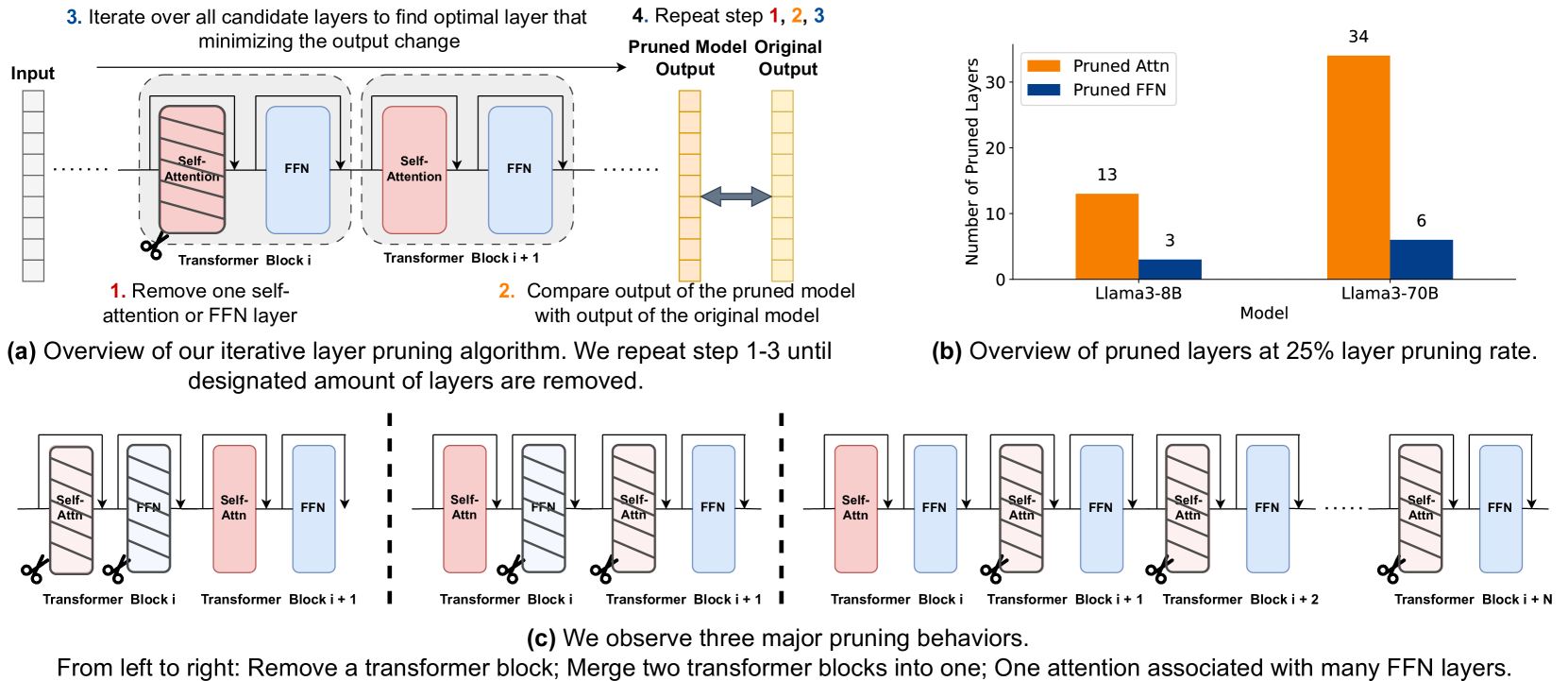
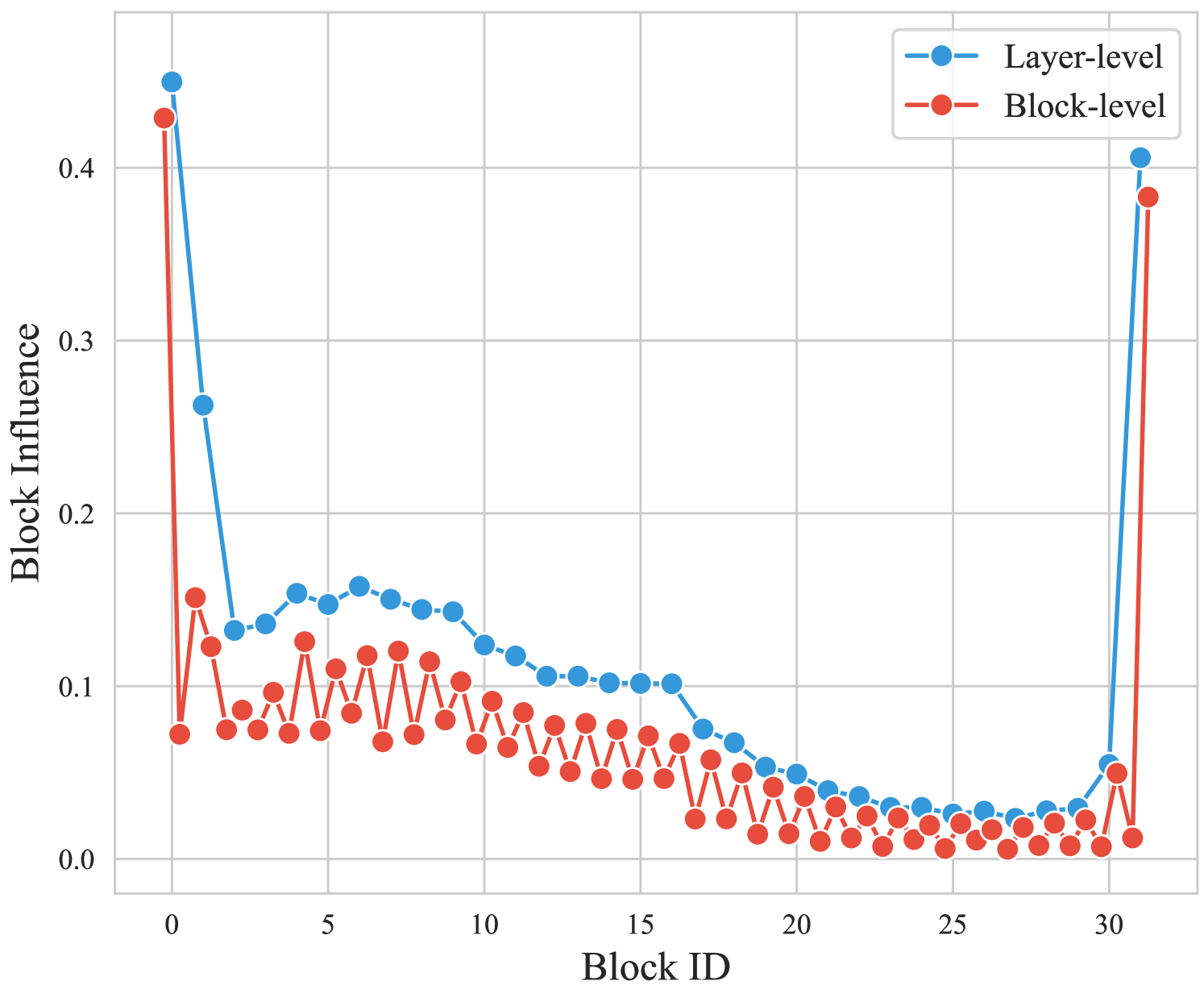
FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models
Yang Zhang, Yawei Li, Xinpeng Wang, Qianli Shen, Barbara Plank, Bernd Bischl, Mina Rezaei, Kenji Kawaguchi
0
0
Overparametrized transformer networks are the state-of-the-art architecture for Large Language Models (LLMs). However, such models contain billions of parameters making large compute a necessity, while raising environmental concerns. To address these issues, we propose FinerCut, a new form of fine-grained layer pruning, which in contrast to prior work at the transformer block level, considers all self-attention and feed-forward network (FFN) layers within blocks as individual pruning candidates. FinerCut prunes layers whose removal causes minimal alternation to the model's output -- contributing to a new, lean, interpretable, and task-agnostic pruning method. Tested across 9 benchmarks, our approach retains 90% performance of Llama3-8B with 25% layers removed, and 95% performance of Llama3-70B with 30% layers removed, all without fine-tuning or post-pruning reconstruction. Strikingly, we observe intriguing results with FinerCut: 42% (34 out of 80) of the self-attention layers in Llama3-70B can be removed while preserving 99% of its performance -- without additional fine-tuning after removal. Moreover, FinerCut provides a tool to inspect the types and locations of pruned layers, allowing to observe interesting pruning behaviors. For instance, we observe a preference for pruning self-attention layers, often at deeper consecutive decoder layers. We hope our insights inspire future efficient LLM architecture designs.
5/29/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024
💬
Shortened LLaMA: Depth Pruning for Large Language Models with Comparison of Retraining Methods
Bo-Kyeong Kim, Geonmin Kim, Tae-Ho Kim, Thibault Castells, Shinkook Choi, Junho Shin, Hyoung-Kyu Song
0
0
Structured pruning of modern large language models (LLMs) has emerged as a way of decreasing their high computational needs. Width pruning reduces the size of projection weight matrices (e.g., by removing attention heads) while maintaining the number of layers. Depth pruning, in contrast, removes entire layers or blocks, while keeping the size of the remaining weights unchanged. Most current research focuses on either width-only or a blend of width and depth pruning, with little comparative analysis between the two units (width vs. depth) concerning their impact on LLM inference efficiency. In this work, we show that simple depth pruning can effectively compress LLMs while achieving comparable or superior performance to recent width pruning studies. Our pruning method boosts inference speeds, especially under memory-constrained conditions that require limited batch sizes for running LLMs, where width pruning is ineffective. In retraining pruned models for quality recovery, continued pretraining on a large corpus markedly outperforms LoRA-based tuning, particularly at severe pruning ratios. We hope this work can help build compact yet capable LLMs. Code and models can be found at: https://github.com/Nota-NetsPresso/shortened-llm
6/26/2024

Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
0
0
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
6/18/2024