FinerCut: Finer-grained Interpretable Layer Pruning for Large Language Models
2405.18218
0
0
Abstract
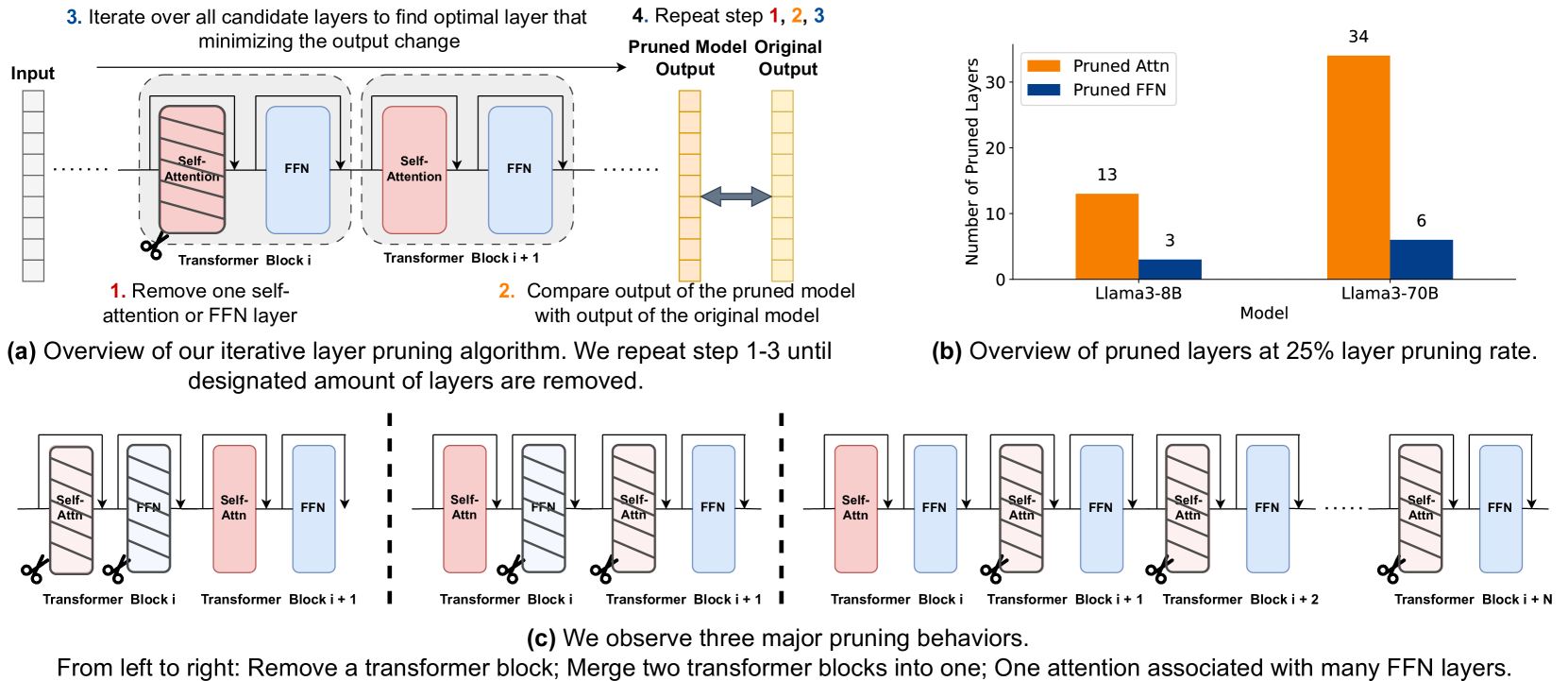
Overparametrized transformer networks are the state-of-the-art architecture for Large Language Models (LLMs). However, such models contain billions of parameters making large compute a necessity, while raising environmental concerns. To address these issues, we propose FinerCut, a new form of fine-grained layer pruning, which in contrast to prior work at the transformer block level, considers all self-attention and feed-forward network (FFN) layers within blocks as individual pruning candidates. FinerCut prunes layers whose removal causes minimal alternation to the model's output -- contributing to a new, lean, interpretable, and task-agnostic pruning method. Tested across 9 benchmarks, our approach retains 90% performance of Llama3-8B with 25% layers removed, and 95% performance of Llama3-70B with 30% layers removed, all without fine-tuning or post-pruning reconstruction. Strikingly, we observe intriguing results with FinerCut: 42% (34 out of 80) of the self-attention layers in Llama3-70B can be removed while preserving 99% of its performance -- without additional fine-tuning after removal. Moreover, FinerCut provides a tool to inspect the types and locations of pruned layers, allowing to observe interesting pruning behaviors. For instance, we observe a preference for pruning self-attention layers, often at deeper consecutive decoder layers. We hope our insights inspire future efficient LLM architecture designs.
Create account to get full access
Overview
- This paper introduces "FinerCut," a method for pruning large language models at a finer granularity to improve interpretability and efficiency.
- The key idea is to prune individual attention heads and feedforward sub-layers, rather than entire transformer layers, to achieve more targeted model compression.
- FinerCut is evaluated on several large language models, including LORA, Sheared LLAMA, and Efficient Pruning, demonstrating improved performance and efficiency over previous layer-wise pruning approaches.
Plain English Explanation
Large language models, like GPT-3, are incredibly powerful but also very complex and computationally intensive. This makes them challenging to deploy on resource-constrained devices or in applications with strict latency requirements.
FinerCut aims to address this by pruning, or removing, parts of the model in a more targeted way. Rather than just removing entire layers of the model, FinerCut prunes individual attention heads and sub-layers within the transformer architecture. This allows the model to be made smaller and more efficient while preserving more of the original model's capabilities.
The key insight is that not all parts of a large language model are equally important. Some attention heads and sub-layers contribute more to the model's performance than others. By selectively pruning the less important components, FinerCut can achieve significant model compression without sacrificing too much accuracy.
Additionally, this fine-grained pruning approach makes the model more interpretable. It's easier to understand which specific parts of the model are being used for different tasks, which can provide valuable insights for model debugging and improvement.
FinerCut has been evaluated on several state-of-the-art large language models, including LORA, Sheared LLAMA, and Efficient Pruning. The results show that FinerCut can achieve significant model compression while maintaining high performance, outperforming previous layer-wise pruning techniques.
Technical Explanation
The FinerCut approach involves pruning individual attention heads and feedforward sub-layers within the transformer architecture, rather than entire transformer layers. This is motivated by the observation that not all model components are equally important for performance, and selectively pruning less crucial parts can lead to more efficient models without excessive accuracy loss.
The authors propose a two-stage pruning process. First, they use an adaptive estimation method to identify the most important attention heads and feedforward sub-layers. This involves analyzing the sensitivity of the model's outputs to changes in each component, allowing the researchers to rank the sub-layers by importance.
In the second stage, the researchers prune the least important sub-layers, gradually increasing the pruning ratio until the desired model size or accuracy target is reached. This fine-grained pruning approach is evaluated on several large language models, including LORA, Sheared LLAMA, and Efficient Pruning.
The results show that FinerCut outperforms previous layer-wise pruning techniques in terms of model compression and inference efficiency, while maintaining high task performance. Additionally, the fine-grained pruning approach makes the model more interpretable, as it's possible to identify which specific sub-components are most crucial for different tasks.
Critical Analysis
The FinerCut approach addresses an important challenge in deploying large language models in resource-constrained environments. By pruning at a finer granularity than previous layer-wise methods, the researchers demonstrate significant improvements in model efficiency without excessive accuracy loss.
However, the paper does not provide a thorough analysis of the limitations or potential drawbacks of the FinerCut approach. For example, it's unclear how the method would scale to even larger models, or how the pruning decisions might interact with the model's overall architecture and training process.
Additionally, the paper could benefit from a more detailed exploration of the interpretability benefits of FinerCut. While the authors claim that the fine-grained pruning makes the model more interpretable, they do not provide a comprehensive analysis of how the pruned components relate to the model's internal representations and reasoning processes.
Further research could also investigate the interplay between FinerCut and other model compression and acceleration techniques, such as MLP-based Transformers or Structured Pruning. Combining FinerCut with these approaches may lead to even more efficient and interpretable large language models.
Conclusion
The FinerCut method presented in this paper represents a significant advance in the field of large language model optimization. By pruning at a finer granularity than previous techniques, the researchers have demonstrated a way to achieve substantial model compression and efficiency gains without excessive accuracy loss.
This work has important implications for the deployment of large language models in a wide range of applications, from edge devices to cloud-based services. The improved interpretability of the pruned models could also lead to valuable insights for model debugging and improvement, ultimately enhancing the capabilities and robustness of these powerful AI systems.
While the paper leaves room for further exploration of the method's limitations and potential synergies with other compression techniques, the FinerCut approach is a promising step towards more efficient and interpretable large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
BlockPruner: Fine-grained Pruning for Large Language Models
Longguang Zhong, Fanqi Wan, Ruijun Chen, Xiaojun Quan, Liangzhi Li
0
0
With the rapid growth in the size and complexity of large language models (LLMs), the costs associated with their training and inference have escalated significantly. Research indicates that certain layers in LLMs harbor substantial redundancy, and pruning these layers has minimal impact on the overall performance. While various layer pruning methods have been developed based on this insight, they generally overlook the finer-grained redundancies within the layers themselves. In this paper, we delve deeper into the architecture of LLMs and demonstrate that finer-grained pruning can be achieved by targeting redundancies in multi-head attention (MHA) and multi-layer perceptron (MLP) blocks. We propose a novel, training-free structured pruning approach called BlockPruner. Unlike existing layer pruning methods, BlockPruner segments each Transformer layer into MHA and MLP blocks. It then assesses the importance of these blocks using perplexity measures and applies a heuristic search for iterative pruning. We applied BlockPruner to LLMs of various sizes and architectures and validated its performance across a wide range of downstream tasks. Experimental results show that BlockPruner achieves more granular and effective pruning compared to state-of-the-art baselines.
6/21/2024

Building on Efficient Foundations: Effectively Training LLMs with Structured Feedforward Layers
Xiuying Wei, Skander Moalla, Razvan Pascanu, Caglar Gulcehre
0
0
State-of-the-art results in large language models (LLMs) often rely on scale, which becomes computationally expensive. This has sparked a research agenda to reduce these models' parameter count and computational costs without significantly impacting their performance. Our study focuses on transformer-based LLMs, specifically targeting the computationally intensive feedforward networks (FFN), which are less studied than attention blocks. We consider three candidate linear layer approximations in the FFN by combining efficient low-rank and block-diagonal matrices. In contrast to many previous works that examined these approximations, our study i) explores these structures from the training-from-scratch perspective, ii) scales up to 1.3B parameters, and iii) is conducted within recent Transformer-based LLMs rather than convolutional architectures. We first demonstrate they can lead to actual computational gains in various scenarios, including online decoding when using a pre-merge technique. Additionally, we propose a novel training regime, called textit{self-guided training}, aimed at improving the poor training dynamics that these approximations exhibit when used from initialization. Experiments on the large RefinedWeb dataset show that our methods are both efficient and effective for training and inference. Interestingly, these structured FFNs exhibit steeper scaling curves than the original models. Further applying self-guided training to the structured matrices with 32% FFN parameters and 2.5$times$ speed-up enables only a 0.4 perplexity increase under the same training FLOPs. Finally, we develop the wide and structured networks surpassing the current medium-sized and large-sized Transformer in perplexity and throughput performance. Our code is available at url{https://github.com/CLAIRE-Labo/StructuredFFN/tree/main}.
6/26/2024

Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
Jun Liu, Chao Wu, Changdi Yang, Hao Tang, Zhenglun Kong, Geng Yuan, Wei Niu, Dong Huang, Yanzhi Wang
0
0
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
5/16/2024

What Matters in Transformers? Not All Attention is Needed
Shwai He, Guoheng Sun, Zheyu Shen, Ang Li
0
0
Scaling Transformer-based large language models (LLMs) has demonstrated promising performance across various tasks. However, this scaling also introduces redundant structures, posing challenges for real-world deployment. Despite some recognition of redundancy in LLMs, the variability of redundancy across different structures, such as MLP and Attention layers, is under-explored. In this work, we investigate the varying redundancy across different modules within Transformers, including Blocks, MLP, and Attention layers, using a similarity-based metric. This metric operates on the premise that redundant structures produce outputs highly similar to their inputs. Surprisingly, while attention layers are essential for transformers and distinguish them from other mainstream architectures, we found that a large proportion of attention layers exhibit excessively high similarity and can be safely pruned without degrading performance, leading to reduced memory and computation costs. Additionally, we further propose a method that jointly drops Attention and MLP layers, achieving improved performance and dropping ratios. Extensive experiments demonstrate the effectiveness of our methods, e.g., Llama-3-70B maintains comparable performance even after pruning half of the attention layers. Our findings provide valuable insights for future network architecture design. The code will be released at: url{https://github.com/Shwai-He/LLM-Drop}.
6/26/2024