Efficient Pruning of Large Language Model with Adaptive Estimation Fusion
2403.10799
0
0

Abstract
Large language models (LLMs) have become crucial for many generative downstream tasks, leading to an inevitable trend and significant challenge to deploy them efficiently on resource-constrained devices. Structured pruning is a widely used method to address this challenge. However, when dealing with the complex structure of the multiple decoder layers, general methods often employ common estimation approaches for pruning. These approaches lead to a decline in accuracy for specific downstream tasks. In this paper, we introduce a simple yet efficient method that adaptively models the importance of each substructure. Meanwhile, it can adaptively fuse coarse-grained and finegrained estimations based on the results from complex and multilayer structures. All aspects of our design seamlessly integrate into the endto-end pruning framework. Our experimental results, compared with state-of-the-art methods on mainstream datasets, demonstrate average accuracy improvements of 1.1%, 1.02%, 2.0%, and 1.2% for LLaMa-7B,Vicuna-7B, Baichuan-7B, and Bloom-7b1, respectively.
Create account to get full access
Overview
- This paper introduces a novel method for efficiently pruning large language models (LLMs) using an Adaptive Estimation Fusion (AEF) technique.
- The proposed approach aims to address the challenges of structured pruning, which can lead to significant performance degradation, by adaptively estimating the importance of different model components.
- The authors demonstrate the effectiveness of their method on several LLM architectures, showing improved performance and computational efficiency compared to existing pruning techniques.
Plain English Explanation
Large language models (LLMs) like GPT-3 and BERT have become increasingly important in natural language processing tasks. However, these models can be very large and computationally expensive, making them difficult to deploy on resource-constrained devices.
To address this issue, researchers have explored techniques like structured pruning to reduce the size and complexity of LLMs. Structured pruning involves selectively removing entire components of the model, such as entire layers or channels, to reduce the overall model size without dramatically impacting performance.
The challenge with structured pruning is that it can be difficult to determine which components are the most important to keep. If you remove the wrong components, the model's performance can suffer significantly. This paper introduces a new technique called Adaptive Estimation Fusion (AEF) that aims to solve this problem.
The key idea behind AEF is to adaptively estimate the importance of different model components during the pruning process. This allows the method to focus on pruning the least important components while preserving the most critical ones. The authors show that this approach outperforms existing pruning techniques, leading to more efficient and accurate LLMs.
Technical Explanation
The paper proposes an Adaptive Estimation Fusion (AEF) method for structured pruning of large language models. The key components of the proposed approach are:
-
Structured Pruning: The authors consider structured pruning, which involves removing entire components of the model (e.g., layers, channels) rather than individual weights. This can lead to significant model compression while maintaining performance.
-
Adaptive Importance Estimation: The core of the AEF method is an adaptive mechanism for estimating the importance of different model components. This is done by fusing multiple importance estimation techniques, including gradient-based and reconstruction-based approaches, to obtain a more reliable and robust importance score.
-
Iterative Pruning and Fine-tuning: The AEF method iterates between pruning the least important components and fine-tuning the pruned model to recover performance. This allows the model to adapt to the pruning changes and maintain high accuracy.
The authors evaluate the proposed AEF method on several large language model architectures, including GPT-2, BERT, and T5. The results demonstrate that AEF outperforms existing structured pruning techniques in terms of model size reduction and performance preservation.
Critical Analysis
The paper presents a well-designed and thorough approach to structured pruning of large language models. The key strength of the AEF method is its ability to adaptively estimate the importance of different model components, which helps maintain performance while achieving significant model compression.
One potential limitation of the study is the lack of analysis on the generalization of the AEF method to other types of large neural networks beyond language models. While the authors demonstrate the effectiveness on several LLM architectures, it would be interesting to see how the method performs on other large-scale models, such as computer vision or multimodal transformers.
Additionally, the paper does not provide much insight into the computational overhead and runtime implications of the AEF method. Understanding the trade-offs between the benefits of model compression and the additional computational resources required for the adaptive importance estimation process would be valuable for practitioners.
Overall, the Adaptive Estimation Fusion approach presented in this paper represents a promising direction for efficient and effective pruning of large language models. The authors have made a valuable contribution to the field of model compression, and their work could inspire further research into adaptive and hybrid pruning techniques.
Conclusion
This paper introduces a novel Adaptive Estimation Fusion (AEF) method for structured pruning of large language models. The key innovation of the AEF approach is its ability to adaptively estimate the importance of different model components, which enables efficient pruning while preserving model performance.
The authors demonstrate the effectiveness of AEF on several LLM architectures, showing significant improvements in model compression and computational efficiency compared to existing pruning techniques. While the paper focuses on language models, the principles behind the AEF method could potentially be extended to other types of large-scale neural networks, making it a valuable contribution to the broader field of model compression.
The critical analysis highlights the strengths of the AEF approach, as well as potential areas for further research, such as exploring the generalization of the method to other neural network domains and investigating the computational overhead of the adaptive importance estimation process. Overall, this paper represents an important step forward in the development of efficient and effective techniques for pruning large-scale language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Optimization-based Structural Pruning for Large Language Models without Back-Propagation
Yuan Gao, Zujing Liu, Weizhong Zhang, Bo Du, Gui-Song Xia
0
0
Compared to the moderate size of neural network models, structural weight pruning on the Large-Language Models (LLMs) imposes a novel challenge on the efficiency of the pruning algorithms, due to the heavy computation/memory demands of the LLMs. Recent efficient LLM pruning methods typically operate at the post-training phase without the expensive weight finetuning, however, their pruning criteria often rely on heuristically designed metrics, potentially leading to suboptimal performance. We instead propose a novel optimization-based structural pruning that learns the pruning masks in a probabilistic space directly by optimizing the loss of the pruned model. To preserve the efficiency, our method 1) works at post-training phase} and 2) eliminates the back-propagation through the LLM per se during the optimization (i.e., only requires the forward pass of the LLM). We achieve this by learning an underlying Bernoulli distribution to sample binary pruning masks, where we decouple the Bernoulli parameters from the LLM loss, thus facilitating an efficient optimization via a policy gradient estimator without back-propagation. As a result, our method is able to 1) operate at structural granularities of channels, heads, and layers, 2) support global and heterogeneous pruning (i.e., our method automatically determines different redundancy for different layers), and 3) optionally use a metric-based method as initialization (of our Bernoulli distributions). Extensive experiments on LLaMA, LLaMA-2, and Vicuna using the C4 and WikiText2 datasets demonstrate that our method operates for 2.7 hours with around 35GB memory for the 13B models on a single A100 GPU, and our pruned models outperform the state-of-the-arts w.r.t. perplexity. Codes will be released.
6/18/2024
💬
Sheared LLaMA: Accelerating Language Model Pre-training via Structured Pruning
Mengzhou Xia, Tianyu Gao, Zhiyuan Zeng, Danqi Chen
0
0
The popularity of LLaMA (Touvron et al., 2023a;b) and other recently emerged moderate-sized large language models (LLMs) highlights the potential of building smaller yet powerful LLMs. Regardless, the cost of training such models from scratch on trillions of tokens remains high. In this work, we study structured pruning as an effective means to develop smaller LLMs from pre-trained, larger models. Our approach employs two key techniques: (1) targeted structured pruning, which prunes a larger model to a specified target shape by removing layers, heads, and intermediate and hidden dimensions in an end-to-end manner, and (2) dynamic batch loading, which dynamically updates the composition of sampled data in each training batch based on varying losses across different domains. We demonstrate the efficacy of our approach by presenting the Sheared-LLaMA series, pruning the LLaMA2-7B model down to 1.3B and 2.7B parameters. Sheared-LLaMA models outperform state-of-the-art open-source models of equivalent sizes, such as Pythia, INCITE, OpenLLaMA and the concurrent TinyLlama models, on a wide range of downstream and instruction tuning evaluations, while requiring only 3% of compute compared to training such models from scratch. This work provides compelling evidence that leveraging existing LLMs with structured pruning is a far more cost-effective approach for building competitive small-scale LLMs
4/12/2024
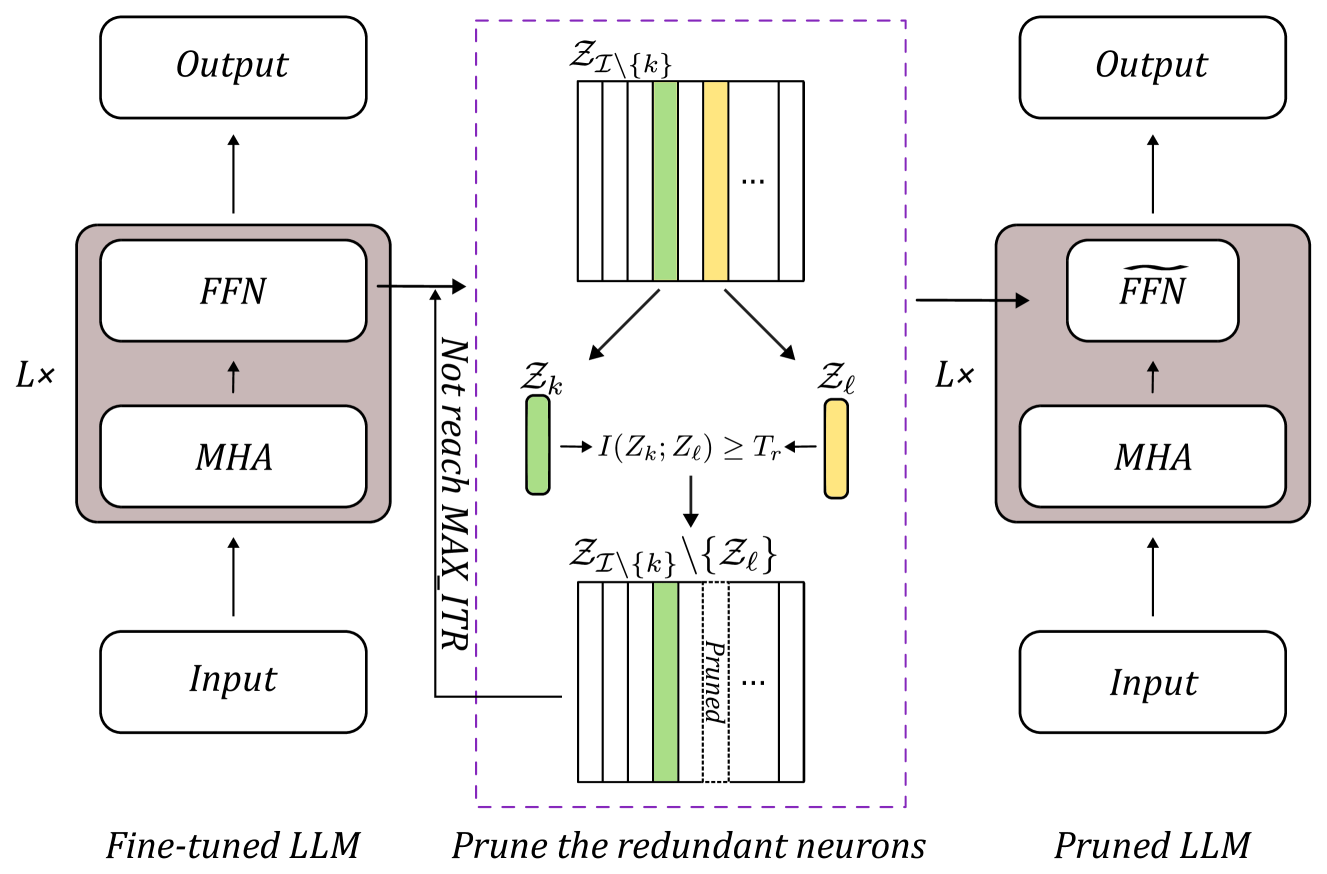
Large Language Model Pruning
Hanjuan Huang (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hao-Jia Song (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan), Hsing-Kuo Pao (Dept. of Computer Science and Information Engineering National Taiwan University of Science and Technology, Taipei, Taiwan)
0
0
We surely enjoy the larger the better models for their superior performance in the last couple of years when both the hardware and software support the birth of such extremely huge models. The applied fields include text mining and others. In particular, the success of LLMs on text understanding and text generation draws attention from researchers who have worked on NLP and related areas for years or even decades. On the side, LLMs may suffer from problems like model overfitting, hallucination, and device limitation to name a few. In this work, we suggest a model pruning technique specifically focused on LLMs. The proposed methodology emphasizes the explainability of deep learning models. By having the theoretical foundation, we obtain a trustworthy deep model so that huge models with a massive number of model parameters become not quite necessary. A mutual information-based estimation is adopted to find neurons with redundancy to eliminate. Moreover, an estimator with well-tuned parameters helps to find precise estimation to guide the pruning procedure. At the same time, we also explore the difference between pruning on large-scale models vs. pruning on small-scale models. The choice of pruning criteria is sensitive in small models but not for large-scale models. It is a novel finding through this work. Overall, we demonstrate the superiority of the proposed model to the state-of-the-art models.
6/4/2024
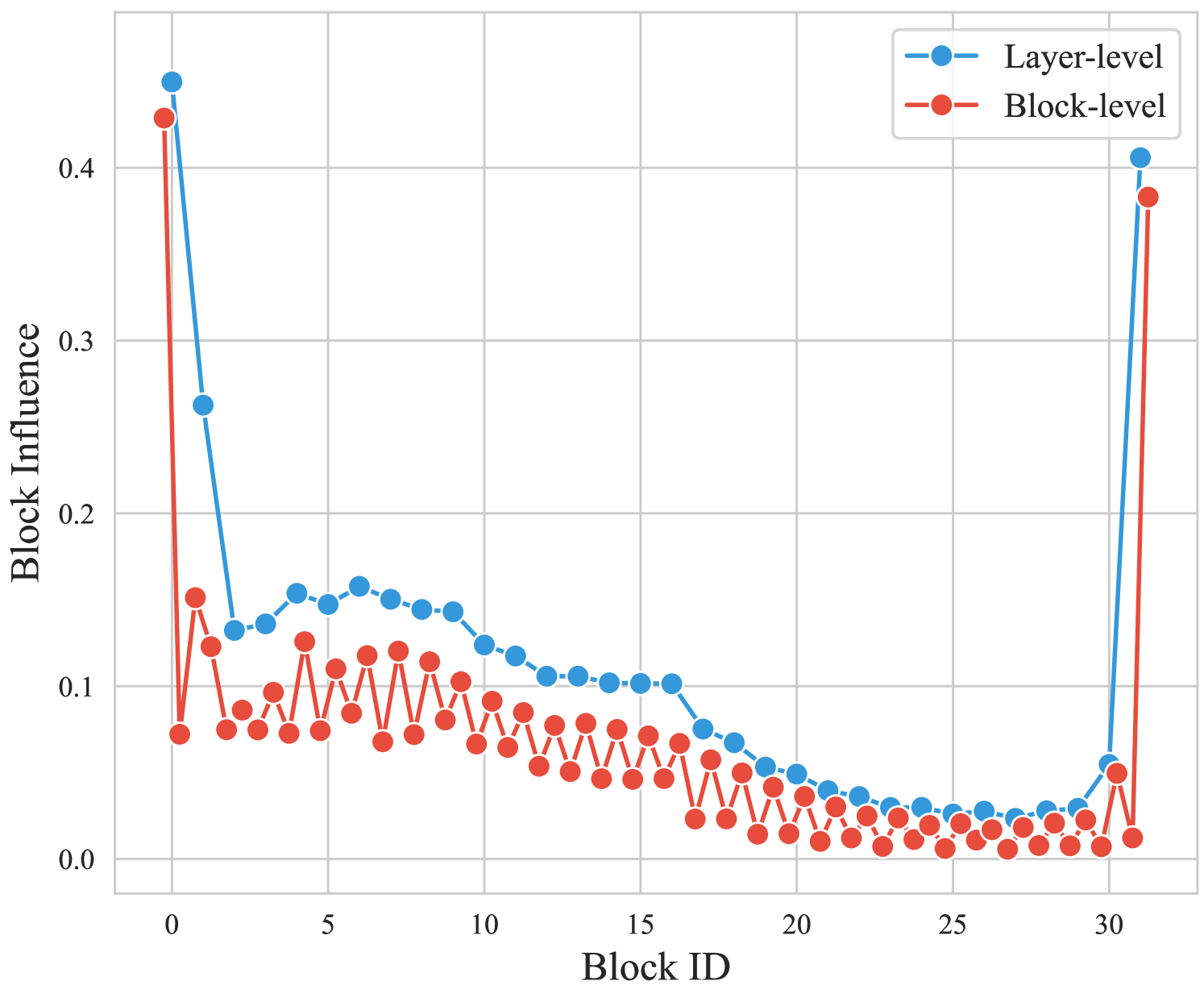
BlockPruner: Fine-grained Pruning for Large Language Models
Longguang Zhong, Fanqi Wan, Ruijun Chen, Xiaojun Quan, Liangzhi Li
0
0
With the rapid growth in the size and complexity of large language models (LLMs), the costs associated with their training and inference have escalated significantly. Research indicates that certain layers in LLMs harbor substantial redundancy, and pruning these layers has minimal impact on the overall performance. While various layer pruning methods have been developed based on this insight, they generally overlook the finer-grained redundancies within the layers themselves. In this paper, we delve deeper into the architecture of LLMs and demonstrate that finer-grained pruning can be achieved by targeting redundancies in multi-head attention (MHA) and multi-layer perceptron (MLP) blocks. We propose a novel, training-free structured pruning approach called BlockPruner. Unlike existing layer pruning methods, BlockPruner segments each Transformer layer into MHA and MLP blocks. It then assesses the importance of these blocks using perplexity measures and applies a heuristic search for iterative pruning. We applied BlockPruner to LLMs of various sizes and architectures and validated its performance across a wide range of downstream tasks. Experimental results show that BlockPruner achieves more granular and effective pruning compared to state-of-the-art baselines.
6/21/2024