Blocks as Probes: Dissecting Categorization Ability of Large Multimodal Models

0

Sign in to get full access
Overview
- This paper examines the categorization abilities of large multimodal models, which are AI systems trained on both text and visual data.
- The researchers use "blocks" - specific image regions or textual snippets - as "probes" to understand how these models make categorization decisions.
- The goal is to gain insights into the inner workings of these complex models and identify their strengths and limitations in visual and textual understanding.
Plain English Explanation
The paper looks at how well large multimodal AI models, which are trained on both words and images, can categorize or classify different types of information. The researchers use specific "blocks" of images or text as "probes" to test the models' decision-making process.
By examining how the models respond to these targeted probes, the researchers aim to better understand the inner workings of these complex systems and identify areas where they excel or struggle when it comes to visual and textual understanding. This could provide valuable insights for improving the capabilities of these large multimodal models in the future.
Technical Explanation
The researchers designed experiments to "dissect" the categorization abilities of large multimodal AI models. They used "blocks" - specific image regions or textual snippets - as "probes" to interrogate how the models make categorization decisions.
The experiments involved feeding these probes into the models and analyzing the outputs to gain insights into the models' decision-making process. This allowed the researchers to identify which visual and textual cues the models relied on, and where their strengths and limitations lie in terms of understanding the provided information.
By taking this targeted, "block-based" approach, the researchers were able to shed light on the inner workings of these complex multimodal systems and uncover important nuances in their categorization abilities.
Critical Analysis
The paper acknowledges that the experiments were conducted on a limited set of models and datasets, and the researchers note that further research is needed to generalize their findings.
Additionally, the paper does not address potential biases or ethical considerations that may arise from the use of these large multimodal models, which is an important area for future exploration.
While the "blocks as probes" methodology provides valuable insights, the researchers could have delved deeper into the implications of their findings and how they might inform the continued development and responsible deployment of these advanced AI systems.
Conclusion
This paper presents a novel approach to dissecting the categorization abilities of large multimodal AI models. By using targeted "blocks" as probes, the researchers were able to gain important insights into the models' decision-making processes and uncover areas where they excel or struggle in understanding visual and textual information.
The findings from this research could inform efforts to improve the capabilities of these complex systems and ensure they are developed and deployed in a responsible manner. As multimodal AI continues to advance, a deeper understanding of these models' strengths and limitations will be crucial for realizing their full potential while addressing potential societal impacts.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Blocks as Probes: Dissecting Categorization Ability of Large Multimodal Models
Bin Fu, Qiyang Wan, Jialin Li, Ruiping Wang, Xilin Chen
Categorization, a core cognitive ability in humans that organizes objects based on common features, is essential to cognitive science as well as computer vision. To evaluate the categorization ability of visual AI models, various proxy tasks on recognition from datasets to open world scenarios have been proposed. Recent development of Large Multimodal Models (LMMs) has demonstrated impressive results in high-level visual tasks, such as visual question answering, video temporal reasoning, etc., utilizing the advanced architectures and large-scale multimodal instruction tuning. Previous researchers have developed holistic benchmarks to measure the high-level visual capability of LMMs, but there is still a lack of pure and in-depth quantitative evaluation of the most fundamental categorization ability. According to the research on human cognitive process, categorization can be seen as including two parts: category learning and category use. Inspired by this, we propose a novel, challenging, and efficient benchmark based on composite blocks, called ComBo, which provides a disentangled evaluation framework and covers the entire categorization process from learning to use. By analyzing the results of multiple evaluation tasks, we find that although LMMs exhibit acceptable generalization ability in learning new categories, there are still gaps compared to humans in many ways, such as fine-grained perception of spatial relationship and abstract category understanding. Through the study of categorization, we can provide inspiration for the further development of LMMs in terms of interpretability and generalization.
Read more9/4/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024
0
What is the Visual Cognition Gap between Humans and Multimodal LLMs?
Xu Cao, Bolin Lai, Wenqian Ye, Yunsheng Ma, Joerg Heintz, Jintai Chen, Jianguo Cao, James M. Rehg
Recently, Multimodal Large Language Models (MLLMs) have shown great promise in language-guided perceptual tasks such as recognition, segmentation, and object detection. However, their effectiveness in addressing visual cognition problems that require high-level reasoning is not well-established. One such challenge is abstract visual reasoning (AVR) -- the cognitive ability to discern relationships among patterns in a set of images and extrapolate to predict subsequent patterns. This skill is crucial during the early neurodevelopmental stages of children. Inspired by the AVR tasks in Raven's Progressive Matrices (RPM) and Wechsler Intelligence Scale for Children (WISC), we propose a new dataset MaRs-VQA and a new benchmark VCog-Bench containing three datasets to evaluate the zero-shot AVR capability of MLLMs and compare their performance with existing human intelligent investigation. Our comparative experiments with different open-source and closed-source MLLMs on the VCog-Bench revealed a gap between MLLMs and human intelligence, highlighting the visual cognitive limitations of current MLLMs. We believe that the public release of VCog-Bench, consisting of MaRs-VQA, and the inference pipeline will drive progress toward the next generation of MLLMs with human-like visual cognition abilities.
Read more6/18/2024
0
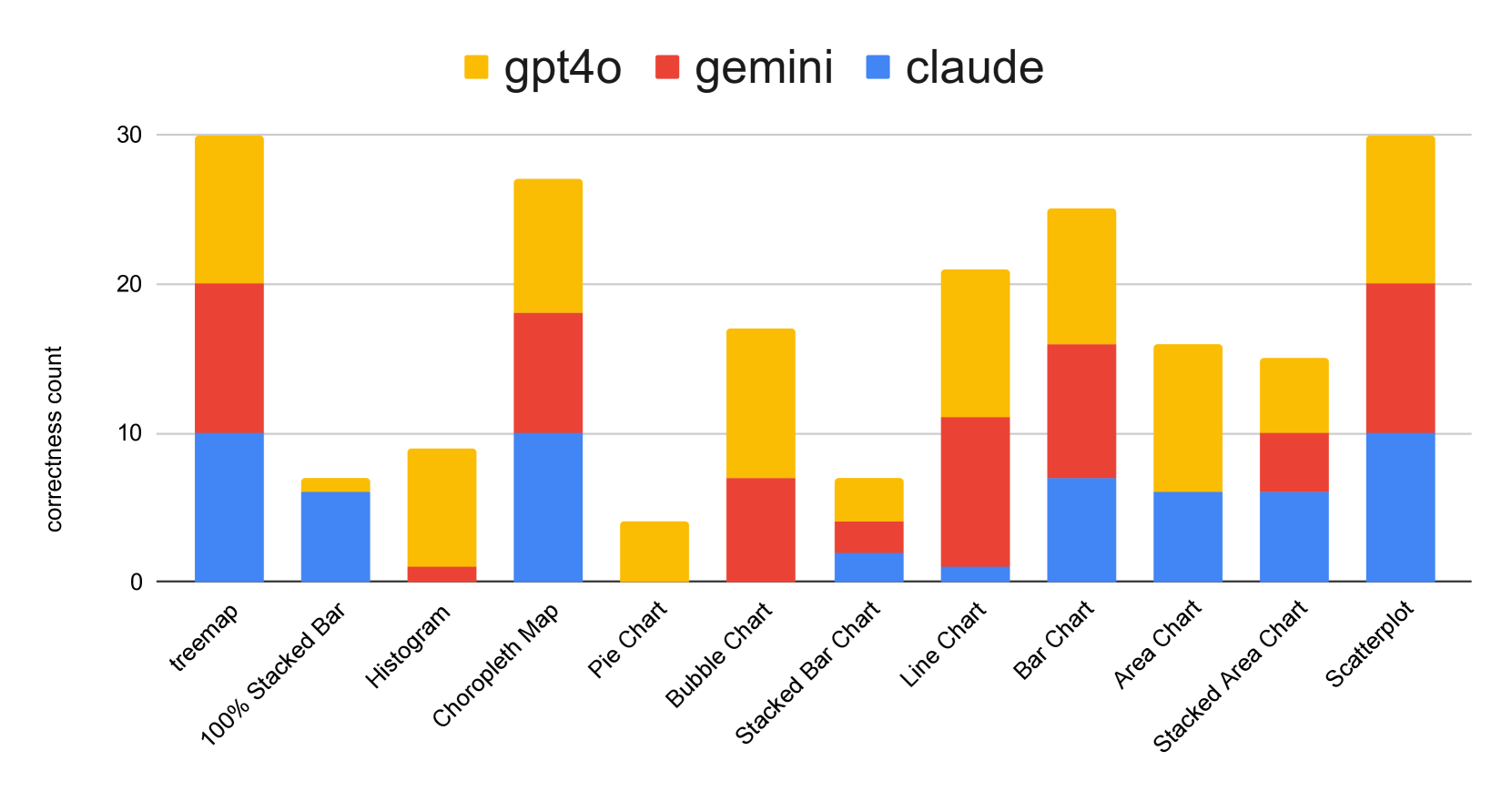
Visualization Literacy of Multimodal Large Language Models: A Comparative Study
Zhimin Li, Haichao Miao, Valerio Pascucci, Shusen Liu
The recent introduction of multimodal large language models (MLLMs) combine the inherent power of large language models (LLMs) with the renewed capabilities to reason about the multimodal context. The potential usage scenarios for MLLMs significantly outpace their text-only counterparts. Many recent works in visualization have demonstrated MLLMs' capability to understand and interpret visualization results and explain the content of the visualization to users in natural language. In the machine learning community, the general vision capabilities of MLLMs have been evaluated and tested through various visual understanding benchmarks. However, the ability of MLLMs to accomplish specific visualization tasks based on visual perception has not been properly explored and evaluated, particularly, from a visualization-centric perspective. In this work, we aim to fill the gap by utilizing the concept of visualization literacy to evaluate MLLMs. We assess MLLMs' performance over two popular visualization literacy evaluation datasets (VLAT and mini-VLAT). Under the framework of visualization literacy, we develop a general setup to compare different multimodal large language models (e.g., GPT4-o, Claude 3 Opus, Gemini 1.5 Pro) as well as against existing human baselines. Our study demonstrates MLLMs' competitive performance in visualization literacy, where they outperform humans in certain tasks such as identifying correlations, clusters, and hierarchical structures.
Read more7/17/2024