Visualization Literacy of Multimodal Large Language Models: A Comparative Study

0
Sign in to get full access
Overview
This paper presents a comparative study on the visualization literacy of multimodal large language models (LLMs). The researchers investigate how well these models can understand and reason about visual information, a critical capability for applications like image captioning, visual question answering, and visual reasoning. The study compares the performance of several prominent multimodal LLMs on a range of visualization-focused tasks, providing insights into the strengths and limitations of current approaches.
Plain English Explanation
Large language models like GPT-3 have shown impressive capabilities in processing and generating human-like text. However, real-world applications often require understanding and reasoning about visual information as well. This paper examines how well these multimodal models, which are trained on both text and images, can interpret and work with visualizations like charts, diagrams, and infographics.
The researchers put several leading multimodal LLMs to the test, asking them to perform tasks like describing the key insights or trends shown in a visualization, answering questions about the data, or even generating relevant visualizations from text. By comparing the models' performance, the study sheds light on their current strengths and limitations when it comes to visual literacy.
This is an important area of research, as the ability to seamlessly combine text and visual understanding is crucial for building AI systems that can truly assist humans in tasks involving complex, information-rich materials. The findings of this paper can help guide the development of more capable and versatile multimodal models.
Technical Explanation
The paper begins by providing an overview of related work in the field of multimodal LLMs and their applications, highlighting the growing importance of visual literacy for these models.
The core of the study involves evaluating the performance of several prominent multimodal LLMs, including DALL-E 2, VL-T5, and CLIP, on a diverse set of visualization-focused tasks. These tasks include:
- Visualization Description: Generating natural language descriptions of the key insights or trends conveyed by a given visualization.
- Visualization Question Answering: Answering specific questions about the data or information presented in a visualization.
- Visualization Generation: Generating appropriate visualizations to represent information described in text.
The researchers carefully designed the evaluation datasets and protocols to ensure a comprehensive and rigorous assessment of the models' visual literacy capabilities. They report on the models' performance across these tasks, highlighting their strengths, weaknesses, and the factors that influence their behavior.
Critical Analysis
The paper acknowledges several caveats and limitations of the study. For example, the evaluation datasets, while diverse, may not fully capture the breadth of real-world visualization types and tasks. Additionally, the models' performance may be influenced by various factors, such as their specific architectural choices, training data, and fine-tuning approaches, which are not always fully accounted for.
Moreover, the paper does not delve deeply into the underlying reasons for the observed performance differences between the models. A more in-depth analysis of the models' internal representations and reasoning processes could shed further light on the nature of their visual literacy and guide future model development.
Despite these limitations, the study provides valuable insights into the current state of multimodal LLMs' visualization capabilities and serves as an important benchmark for the field. The findings can inform the ongoing efforts to improve the visual storytelling abilities of these models and advance the development of more capable and versatile AI systems.
Conclusion
This comparative study offers a comprehensive assessment of the visualization literacy of leading multimodal large language models. The researchers' systematic evaluation of the models' performance on a range of visualization-focused tasks reveals both the progress made in this area and the significant challenges that remain.
The findings of this paper can inform the continued development of multimodal LLMs, guiding researchers and practitioners towards more effective approaches for enhancing the visual understanding and reasoning capabilities of these powerful AI systems. As the field of multimodal machine learning continues to evolve, studies like this one will play a crucial role in shaping the future of technologies that seamlessly integrate text and visual processing.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Visualization Literacy of Multimodal Large Language Models: A Comparative Study
Zhimin Li, Haichao Miao, Valerio Pascucci, Shusen Liu
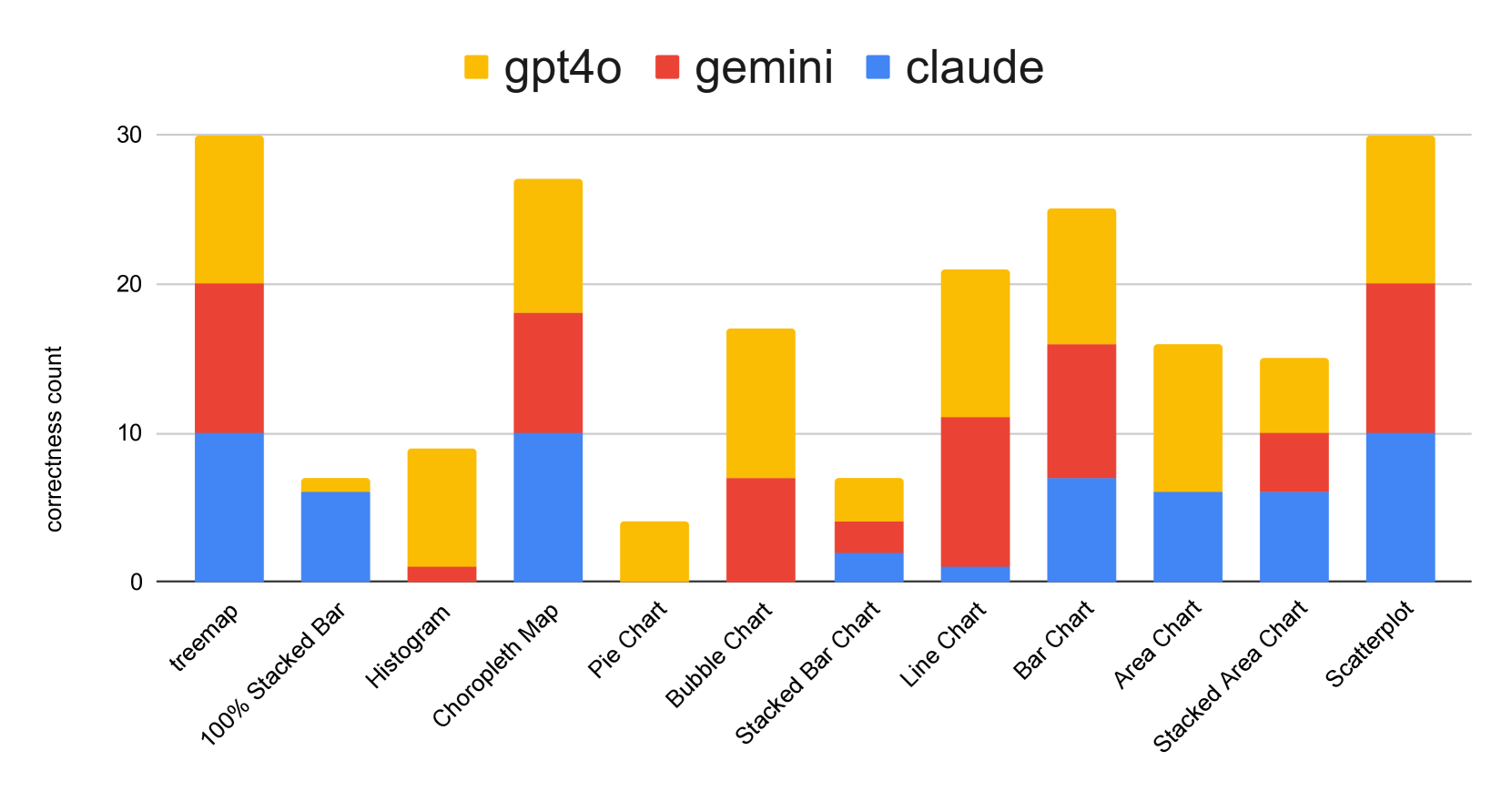
The recent introduction of multimodal large language models (MLLMs) combine the inherent power of large language models (LLMs) with the renewed capabilities to reason about the multimodal context. The potential usage scenarios for MLLMs significantly outpace their text-only counterparts. Many recent works in visualization have demonstrated MLLMs' capability to understand and interpret visualization results and explain the content of the visualization to users in natural language. In the machine learning community, the general vision capabilities of MLLMs have been evaluated and tested through various visual understanding benchmarks. However, the ability of MLLMs to accomplish specific visualization tasks based on visual perception has not been properly explored and evaluated, particularly, from a visualization-centric perspective. In this work, we aim to fill the gap by utilizing the concept of visualization literacy to evaluate MLLMs. We assess MLLMs' performance over two popular visualization literacy evaluation datasets (VLAT and mini-VLAT). Under the framework of visualization literacy, we develop a general setup to compare different multimodal large language models (e.g., GPT4-o, Claude 3 Opus, Gemini 1.5 Pro) as well as against existing human baselines. Our study demonstrates MLLMs' competitive performance in visualization literacy, where they outperform humans in certain tasks such as identifying correlations, clusters, and hierarchical structures.
Read more7/17/2024

0
The Revolution of Multimodal Large Language Models: A Survey
Davide Caffagni, Federico Cocchi, Luca Barsellotti, Nicholas Moratelli, Sara Sarto, Lorenzo Baraldi, Lorenzo Baraldi, Marcella Cornia, Rita Cucchiara
Connecting text and visual modalities plays an essential role in generative intelligence. For this reason, inspired by the success of large language models, significant research efforts are being devoted to the development of Multimodal Large Language Models (MLLMs). These models can seamlessly integrate visual and textual modalities, while providing a dialogue-based interface and instruction-following capabilities. In this paper, we provide a comprehensive review of recent visual-based MLLMs, analyzing their architectural choices, multimodal alignment strategies, and training techniques. We also conduct a detailed analysis of these models across a wide range of tasks, including visual grounding, image generation and editing, visual understanding, and domain-specific applications. Additionally, we compile and describe training datasets and evaluation benchmarks, conducting comparisons among existing models in terms of performance and computational requirements. Overall, this survey offers a comprehensive overview of the current state of the art, laying the groundwork for future MLLMs.
Read more6/7/2024
💬
0
Explaining Multi-modal Large Language Models by Analyzing their Vision Perception
Loris Giulivi, Giacomo Boracchi
Multi-modal Large Language Models (MLLMs) have demonstrated remarkable capabilities in understanding and generating content across various modalities, such as images and text. However, their interpretability remains a challenge, hindering their adoption in critical applications. This research proposes a novel approach to enhance the interpretability of MLLMs by focusing on the image embedding component. We combine an open-world localization model with a MLLM, thus creating a new architecture able to simultaneously produce text and object localization outputs from the same vision embedding. The proposed architecture greatly promotes interpretability, enabling us to design a novel saliency map to explain any output token, to identify model hallucinations, and to assess model biases through semantic adversarial perturbations.
Read more5/29/2024
0
A Survey on Evaluation of Multimodal Large Language Models
Jiaxing Huang, Jingyi Zhang
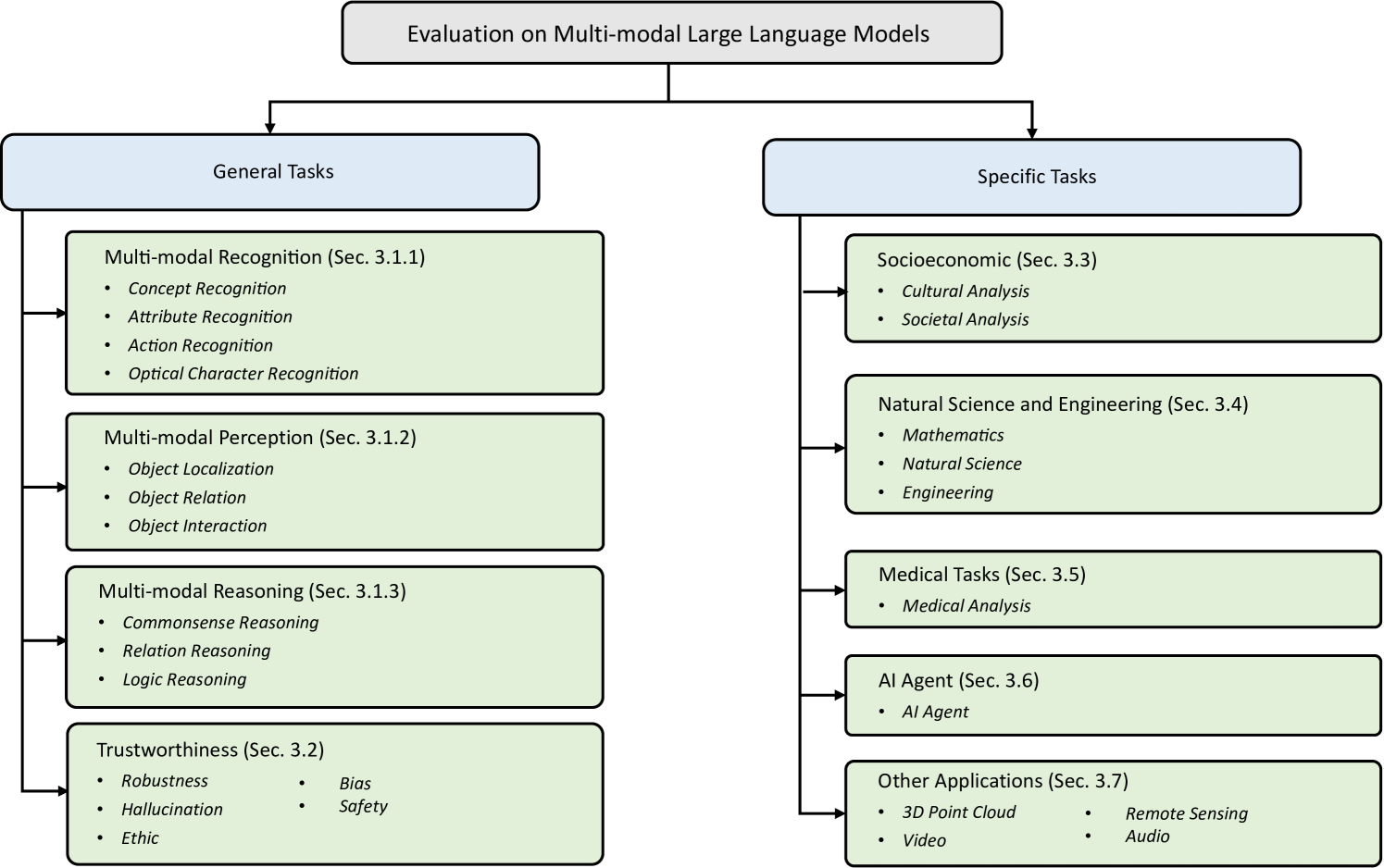
Multimodal Large Language Models (MLLMs) mimic human perception and reasoning system by integrating powerful Large Language Models (LLMs) with various modality encoders (e.g., vision, audio), positioning LLMs as the brain and various modality encoders as sensory organs. This framework endows MLLMs with human-like capabilities, and suggests a potential pathway towards achieving artificial general intelligence (AGI). With the emergence of all-round MLLMs like GPT-4V and Gemini, a multitude of evaluation methods have been developed to assess their capabilities across different dimensions. This paper presents a systematic and comprehensive review of MLLM evaluation methods, covering the following key aspects: (1) the background of MLLMs and their evaluation; (2) what to evaluate that reviews and categorizes existing MLLM evaluation tasks based on the capabilities assessed, including general multimodal recognition, perception, reasoning and trustworthiness, and domain-specific applications such as socioeconomic, natural sciences and engineering, medical usage, AI agent, remote sensing, video and audio processing, 3D point cloud analysis, and others; (3) where to evaluate that summarizes MLLM evaluation benchmarks into general and specific benchmarks; (4) how to evaluate that reviews and illustrates MLLM evaluation steps and metrics; Our overarching goal is to provide valuable insights for researchers in the field of MLLM evaluation, thereby facilitating the development of more capable and reliable MLLMs. We emphasize that evaluation should be regarded as a critical discipline, essential for advancing the field of MLLMs.
Read more8/29/2024