BOND: Aligning LLMs with Best-of-N Distillation

0

Sign in to get full access
Overview
- The paper introduces BOND, a technique for aligning large language models (LLMs) with desired behaviors using a "best-of-N" distillation approach.
- BOND aims to make LLMs more reliable and controllable by training them to mimic the outputs of a set of reference models, each of which specializes in a particular desired behavior.
- The key idea is to distill the knowledge from these reference models into a single unified LLM, allowing it to capture a diverse set of capabilities.
Plain English Explanation
The paper presents a new approach called BOND to make large language models (LLMs) more reliable and controllable. LLMs are powerful AI systems that can generate human-like text, but they can sometimes behave in unpredictable or undesirable ways.
The core idea behind BOND is to train the LLM to mimic the outputs of a set of specialized "reference" models, each of which is good at a particular desired behavior. For example, one reference model might be great at providing factual and objective information, while another excels at generating creative and imaginative text.
By distilling the knowledge from these diverse reference models into a single LLM, BOND aims to create a model that can reliably exhibit a wide range of capabilities - the "best of" all the reference models. The authors call this a "best-of-N" distillation approach.
The key benefit of BOND is that it allows users to have more control over the LLM's behavior and outputs. Instead of the LLM behaving in unpredictable ways, it can be trained to reliably produce text that aligns with the user's preferences and needs.
Technical Explanation
The BOND approach involves training a large language model (LLM) to mimic the outputs of a set of specialized "reference" models, each of which has been trained to exhibit a particular desired behavior. This "best-of-N" distillation process allows the LLM to learn a diverse set of capabilities from the reference models.
The authors first define a set of desired behaviors, such as providing factual information, generating creative content, or exhibiting empathy. They then train a separate reference model for each of these behaviors, using appropriate datasets and training techniques.
Next, they train the main LLM using a combination of standard language modeling objectives and a distillation loss that encourages the LLM to match the outputs of the reference models. This allows the LLM to learn the desired behaviors while still maintaining its broader language understanding capabilities.
The authors evaluate BOND on a range of tasks, including question answering, dialogue, and open-ended text generation. They find that the BOND-trained LLM outperforms both the original LLM and a naive ensemble of the reference models, demonstrating the benefits of the best-of-N distillation approach.
Critical Analysis
The BOND paper presents a promising approach for aligning large language models with desired behaviors, but it also raises some potential concerns and areas for further research.
One key limitation is that the success of BOND relies on the quality and diversity of the reference models used. If the reference models themselves are flawed or biased, then those issues may be inherited by the final BOND-trained LLM. The authors acknowledge this and suggest further research into methods for automatically generating high-quality reference models.
Additionally, the BOND approach adds significant complexity to the training process, as it requires training multiple specialized reference models in addition to the main LLM. This could make the approach more computationally expensive and difficult to scale, especially for large-scale language models.
Further research is also needed to better understand the long-term stability and robustness of BOND-trained LLMs. It's possible that the distillation process could lead to unintended consequences or make the models more vulnerable to adversarial attacks.
Overall, the BOND approach is a novel and interesting step towards more reliable and controllable large language models. However, the practicality and scalability of the approach, as well as its potential limitations and risks, will need to be carefully explored in future work.
Conclusion
The BOND paper introduces a novel technique for aligning large language models (LLMs) with desired behaviors using a "best-of-N" distillation approach. By training the LLM to mimic the outputs of a set of specialized reference models, BOND aims to create a unified model that can reliably exhibit a diverse range of capabilities.
This approach has the potential to make LLMs more controllable and reliable, allowing users to tailor the models' behaviors to their specific needs and preferences. However, the complexity of the BOND training process and the reliance on high-quality reference models raise some concerns that will need to be addressed through further research and experimentation.
Overall, the BOND technique represents an intriguing step forward in the ongoing effort to harness the power of large language models while ensuring they behave in a safe, reliable, and ethical manner. As the field of AI continues to evolve, innovative approaches like BOND will likely play an important role in shaping the future of language-based AI systems.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BOND: Aligning LLMs with Best-of-N Distillation
Pier Giuseppe Sessa, Robert Dadashi, L'eonard Hussenot, Johan Ferret, Nino Vieillard, Alexandre Ram'e, Bobak Shariari, Sarah Perrin, Abe Friesen, Geoffrey Cideron, Sertan Girgin, Piotr Stanczyk, Andrea Michi, Danila Sinopalnikov, Sabela Ramos, Am'elie H'eliou, Aliaksei Severyn, Matt Hoffman, Nikola Momchev, Olivier Bachem
Reinforcement learning from human feedback (RLHF) is a key driver of quality and safety in state-of-the-art large language models. Yet, a surprisingly simple and strong inference-time strategy is Best-of-N sampling that selects the best generation among N candidates. In this paper, we propose Best-of-N Distillation (BOND), a novel RLHF algorithm that seeks to emulate Best-of-N but without its significant computational overhead at inference time. Specifically, BOND is a distribution matching algorithm that forces the distribution of generations from the policy to get closer to the Best-of-N distribution. We use the Jeffreys divergence (a linear combination of forward and backward KL) to balance between mode-covering and mode-seeking behavior, and derive an iterative formulation that utilizes a moving anchor for efficiency. We demonstrate the effectiveness of our approach and several design choices through experiments on abstractive summarization and Gemma models. Aligning Gemma policies with BOND outperforms other RLHF algorithms by improving results on several benchmarks.
Read more7/23/2024

0
BoNBoN Alignment for Large Language Models and the Sweetness of Best-of-n Sampling
Lin Gui, Cristina G^arbacea, Victor Veitch
This paper concerns the problem of aligning samples from large language models to human preferences using best-of-$n$ sampling, where we draw $n$ samples, rank them, and return the best one. We consider two fundamental problems. First: what is the relationship between best-of-$n$ and approaches to alignment that train LLMs to output samples with a high expected reward (e.g., RLHF or DPO)? To answer this, we embed both the best-of-$n$ distribution and the sampling distributions learned by alignment procedures in a common class of tiltings of the base LLM distribution. We then show that, within this class, best-of-$n$ is essentially optimal in terms of the trade-off between win-rate against the base model vs KL distance from the base model. That is, best-of-$n$ is the best choice of alignment distribution if the goal is to maximize win rate. However, best-of-$n$ requires drawing $n$ samples for each inference, a substantial cost. To avoid this, the second problem we consider is how to fine-tune a LLM to mimic the best-of-$n$ sampling distribution. We derive BoNBoN Alignment to achieve this by exploiting the special structure of the best-of-$n$ distribution. Experiments show that BoNBoN alignment yields substantial improvements in producing a model that is preferred to the base policy while minimally affecting off-target aspects.
Read more6/6/2024
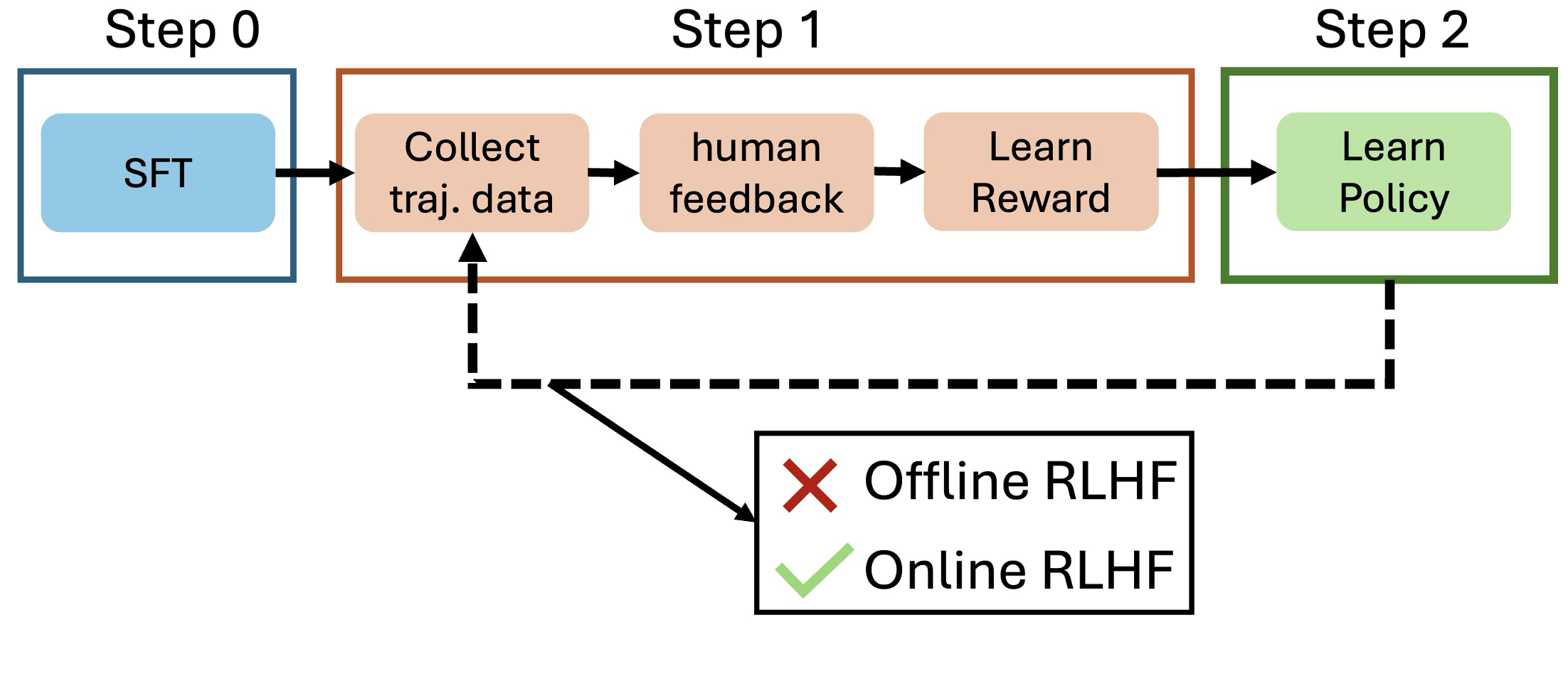
0
SAIL: Self-Improving Efficient Online Alignment of Large Language Models
Mucong Ding, Souradip Chakraborty, Vibhu Agrawal, Zora Che, Alec Koppel, Mengdi Wang, Amrit Bedi, Furong Huang
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
Read more6/26/2024

0
Self and Cross-Model Distillation for LLMs: Effective Methods for Refusal Pattern Alignment
Jie Li, Yi Liu, Chongyang Liu, Xiaoning Ren, Ling Shi, Weisong Sun, Yinxing Xue
Large Language Models (LLMs) like OpenAI's GPT series, Anthropic's Claude, and Meta's LLaMa have shown remarkable capabilities in text generation. However, their susceptibility to toxic prompts presents significant security challenges. This paper investigates alignment techniques, including Supervised Fine-Tuning (SFT) and Reinforcement Learning from Human Feedback (RLHF), to mitigate these risks. We conduct an empirical study on refusal patterns across nine LLMs, revealing that models with uniform refusal patterns, such as Claude3, exhibit higher security. Based on these findings, we propose self-distilling and cross-model distilling methods to enhance LLM security. Our results show that these methods significantly improve refusal rates and reduce unsafe content, with cross-model distilling achieving refusal rates close to Claude3's 94.51%. These findings underscore the potential of distillation-based alignment in securing LLMs against toxic prompts.
Read more6/18/2024