SAIL: Self-Improving Efficient Online Alignment of Large Language Models
2406.15567
0
0
Abstract
Reinforcement Learning from Human Feedback (RLHF) is a key method for aligning large language models (LLMs) with human preferences. However, current offline alignment approaches like DPO, IPO, and SLiC rely heavily on fixed preference datasets, which can lead to sub-optimal performance. On the other hand, recent literature has focused on designing online RLHF methods but still lacks a unified conceptual formulation and suffers from distribution shift issues. To address this, we establish that online LLM alignment is underpinned by bilevel optimization. By reducing this formulation to an efficient single-level first-order method (using the reward-policy equivalence), our approach generates new samples and iteratively refines model alignment by exploring responses and regulating preference labels. In doing so, we permit alignment methods to operate in an online and self-improving manner, as well as generalize prior online RLHF methods as special cases. Compared to state-of-the-art iterative RLHF methods, our approach significantly improves alignment performance on open-sourced datasets with minimal computational overhead.
Create account to get full access
Overview
- This paper presents a new method called SAIL (Self-Improving Efficient Online Alignment of Large Language Models) for aligning large language models with human preferences in an efficient and self-improving way.
- The authors propose a novel approach that combines iterative preference learning from human feedback, self-play and adversarial critic, and online merging of optimizers to achieve improved performance and scalability.
- SAIL aims to address challenges in the RLHF (Reinforcement Learning from Human Feedback) workflow such as sample efficiency, reward modeling, and online fine-tuning.
Plain English Explanation
SAIL is a new method for training large language models to better align with human preferences. The key idea is to have the model continuously learn and improve itself based on feedback from humans, rather than just being trained once and then deployed.
The process works like this:
- The model generates some text and gets feedback from a human on how well it aligns with their preferences.
- The model then uses that feedback to update and improve itself, becoming better at producing text that the human likes.
- This cycle of generating text, getting feedback, and improving itself continues, allowing the model to become more and more aligned with human preferences over time.
By using techniques like iterative preference learning, self-play, and online merging of optimizers, the authors have made this process more efficient and scalable compared to previous approaches.
The goal is to create language models that are not only highly capable, but also well-aligned with human values and preferences, which could be important as these models become more widely used in society.
Technical Explanation
The key technical components of SAIL are:
-
Iterative Preference Learning: The model starts with an initial reward function, but this is continuously updated based on human feedback. This allows the model to learn the user's preferences in an iterative and efficient way, rather than having to specify the full reward function upfront.
-
Self-Play and Adversarial Critic: The model engages in a self-play process, generating candidate outputs and then using an adversarial critic to assess how well they align with the current reward function. This allows the model to explore and improve itself without needing additional human feedback.
-
Online Merging of Optimizers: As the model is fine-tuned, the authors use an online merging technique to combine the original pre-trained model with the updated, aligned model. This helps to maintain the broad capabilities of the original model while incorporating the user-specific preferences.
By combining these techniques, the authors demonstrate that SAIL can achieve strong performance on language tasks while requiring significantly less human feedback and compute resources compared to previous RLHF approaches.
Critical Analysis
The authors acknowledge several limitations and areas for future work:
- The current implementation of SAIL assumes access to a large, high-quality dataset of human feedback. Scaling this to more diverse or niche user preferences may require further innovations.
- The paper does not extensively explore the long-term behavior of the self-improving SAIL model, and there may be potential safety or stability issues that arise over time that require further investigation.
- While the authors claim SAIL is more sample-efficient than previous RLHF methods, the absolute scale of human feedback required is still quite large and may limit its real-world applicability, especially for individual users.
Additionally, one could question whether the self-improving nature of SAIL introduces new risks or challenges around model transparency and interpretability. As the model continuously updates itself, it may become increasingly difficult to understand its inner workings and decision-making process.
Overall, the SAIL approach represents an interesting and promising direction for aligning large language models with human preferences, but further research is needed to address the remaining challenges and concerns.
Conclusion
The SAIL method proposed in this paper offers a novel approach to the challenge of aligning large language models with human preferences. By combining techniques like iterative preference learning, self-play, and online merging of optimizers, the authors have developed a more efficient and scalable system compared to previous RLHF workflows.
While the method shows promise, there are still important challenges and limitations that require further investigation, such as the need for large datasets of human feedback and potential issues around model transparency and interpretability. Nonetheless, the SAIL approach represents an important step forward in the pursuit of building AI systems that are not only highly capable, but also well-aligned with human values and preferences.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
Iterative Preference Learning from Human Feedback: Bridging Theory and Practice for RLHF under KL-Constraint
Wei Xiong, Hanze Dong, Chenlu Ye, Ziqi Wang, Han Zhong, Heng Ji, Nan Jiang, Tong Zhang
0
0
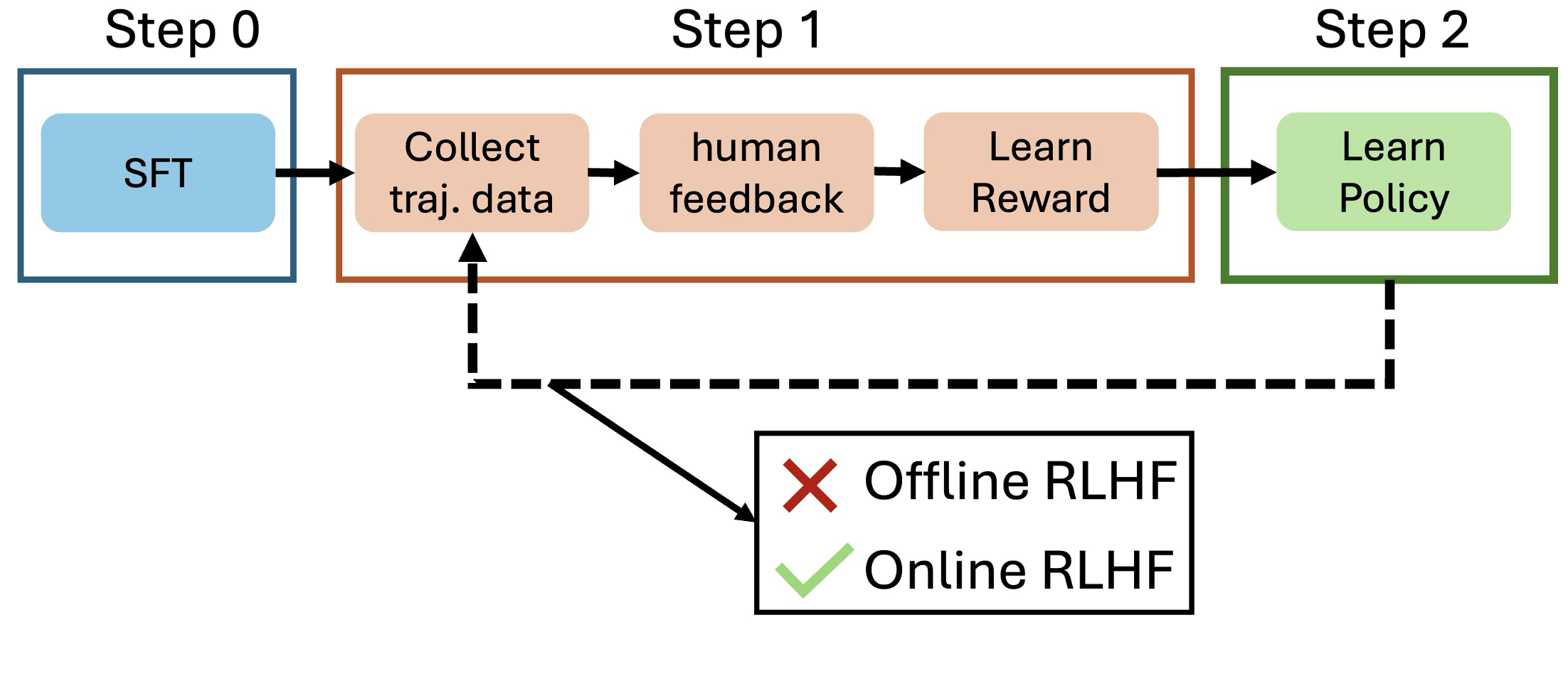
This paper studies the alignment process of generative models with Reinforcement Learning from Human Feedback (RLHF). We first identify the primary challenges of existing popular methods like offline PPO and offline DPO as lacking in strategical exploration of the environment. Then, to understand the mathematical principle of RLHF, we consider a standard mathematical formulation, the reverse-KL regularized contextual bandit for RLHF. Despite its widespread practical application, a rigorous theoretical analysis of this formulation remains open. We investigate its behavior in three distinct settings -- offline, online, and hybrid -- and propose efficient algorithms with finite-sample theoretical guarantees. Moving towards practical applications, our framework, with a robust approximation of the information-theoretical policy improvement oracle, naturally gives rise to several novel RLHF algorithms. This includes an iterative version of the Direct Preference Optimization (DPO) algorithm for online settings, and a multi-step rejection sampling strategy for offline scenarios. Our empirical evaluations on real-world alignment experiment of large language model demonstrate that these proposed methods significantly surpass existing strong baselines, such as DPO and Rejection Sampling Optimization (RSO), showcasing the connections between solid theoretical foundations and their potent practical implementations.
5/2/2024
💬
Self-Play with Adversarial Critic: Provable and Scalable Offline Alignment for Language Models
Xiang Ji, Sanjeev Kulkarni, Mengdi Wang, Tengyang Xie
0
0
This work studies the challenge of aligning large language models (LLMs) with offline preference data. We focus on alignment by Reinforcement Learning from Human Feedback (RLHF) in particular. While popular preference optimization methods exhibit good empirical performance in practice, they are not theoretically guaranteed to converge to the optimal policy and can provably fail when the data coverage is sparse by classical offline reinforcement learning (RL) results. On the other hand, a recent line of work has focused on theoretically motivated preference optimization methods with provable guarantees, but these are not computationally efficient for large-scale applications like LLM alignment. To bridge this gap, we propose SPAC, a new offline preference optimization method with self-play, inspired by the on-average pessimism technique from the offline RL literature, to be the first provable and scalable approach to LLM alignment. We both provide theoretical analysis for its convergence under single-policy concentrability for the general function approximation setting and demonstrate its competitive empirical performance for LLM alignment on a 7B Mistral model with Open LLM Leaderboard evaluations.
6/7/2024
🧠
RLHF Workflow: From Reward Modeling to Online RLHF
Hanze Dong, Wei Xiong, Bo Pang, Haoxiang Wang, Han Zhao, Yingbo Zhou, Nan Jiang, Doyen Sahoo, Caiming Xiong, Tong Zhang
0
0
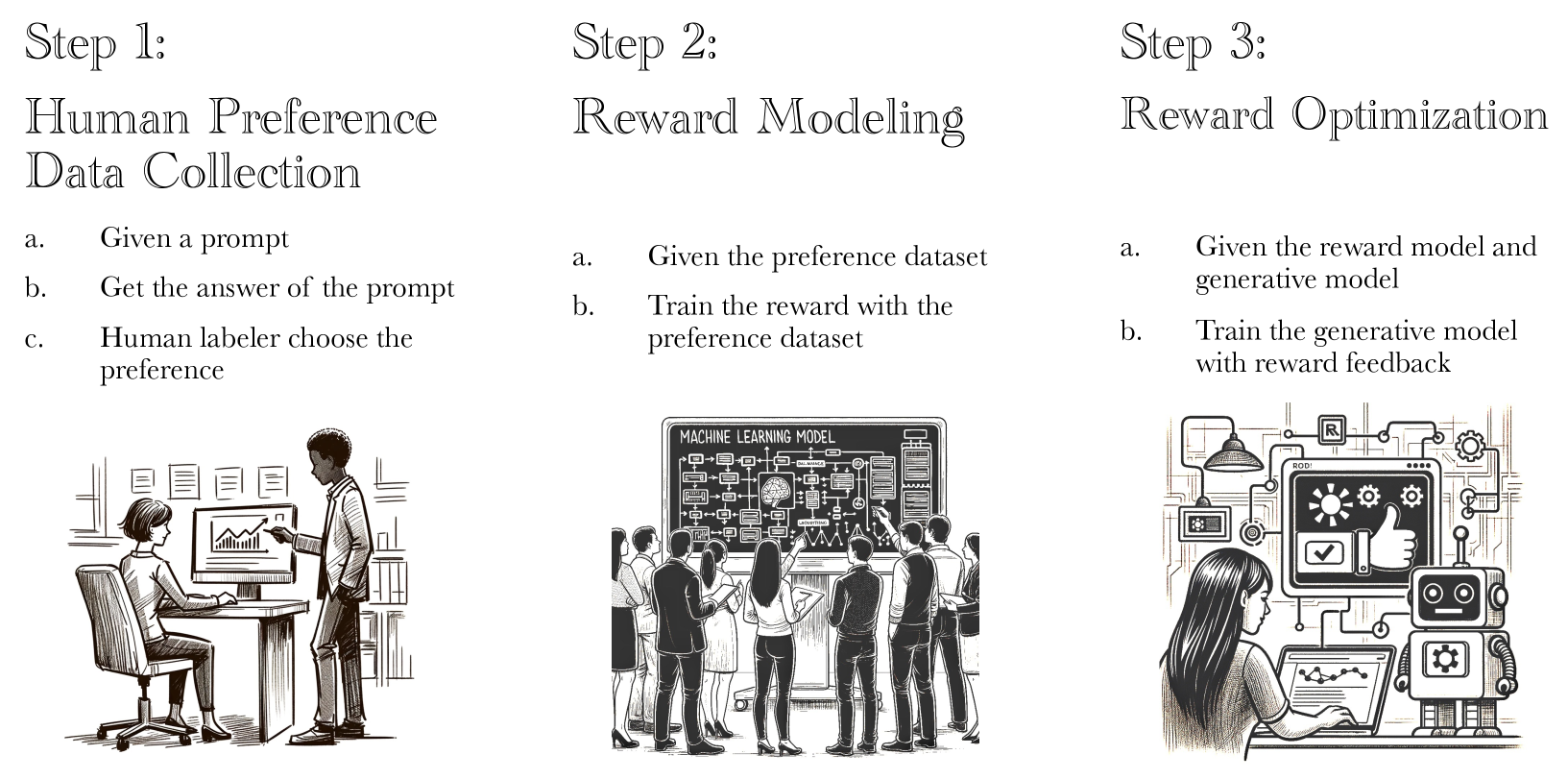
We present the workflow of Online Iterative Reinforcement Learning from Human Feedback (RLHF) in this technical report, which is widely reported to outperform its offline counterpart by a large margin in the recent large language model (LLM) literature. However, existing open-source RLHF projects are still largely confined to the offline learning setting. In this technical report, we aim to fill in this gap and provide a detailed recipe that is easy to reproduce for online iterative RLHF. In particular, since online human feedback is usually infeasible for open-source communities with limited resources, we start by constructing preference models using a diverse set of open-source datasets and use the constructed proxy preference model to approximate human feedback. Then, we discuss the theoretical insights and algorithmic principles behind online iterative RLHF, followed by a detailed practical implementation. Our trained LLM, LLaMA-3-8B-SFR-Iterative-DPO-R, achieves impressive performance on LLM chatbot benchmarks, including AlpacaEval-2, Arena-Hard, and MT-Bench, as well as other academic benchmarks such as HumanEval and TruthfulQA. We have shown that supervised fine-tuning (SFT) and iterative RLHF can obtain state-of-the-art performance with fully open-source datasets. Further, we have made our models, curated datasets, and comprehensive step-by-step code guidebooks publicly available. Please refer to https://github.com/RLHFlow/RLHF-Reward-Modeling and https://github.com/RLHFlow/Online-RLHF for more detailed information.
6/13/2024
Online Merging Optimizers for Boosting Rewards and Mitigating Tax in Alignment
Keming Lu, Bowen Yu, Fei Huang, Yang Fan, Runji Lin, Chang Zhou
0
0
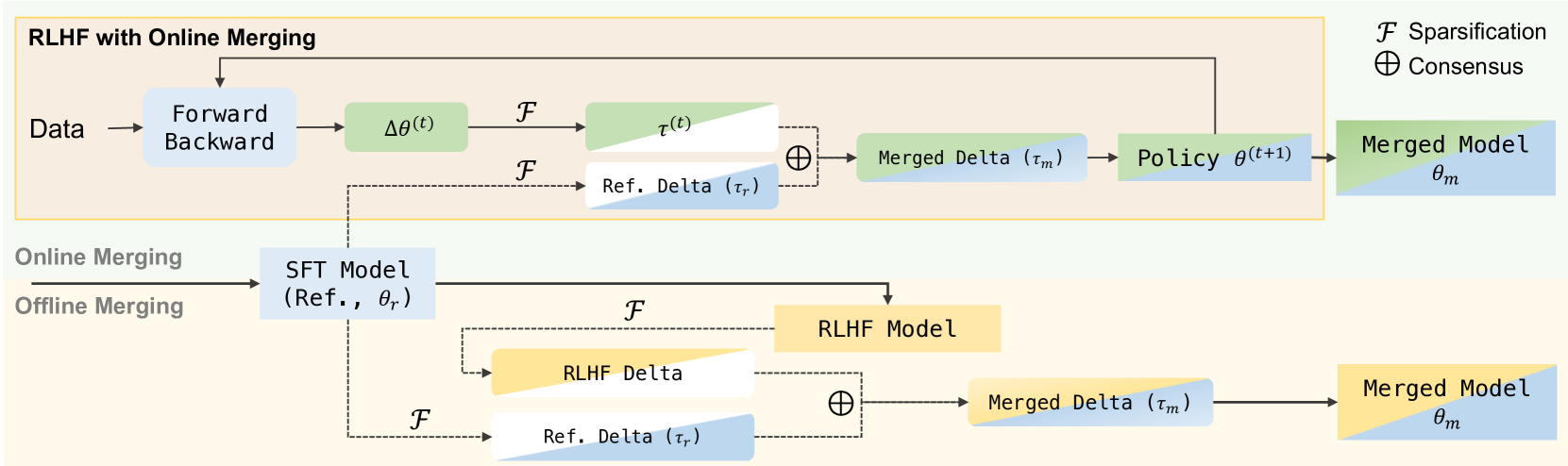
Effectively aligning Large Language Models (LLMs) with human-centric values while preventing the degradation of abilities acquired through Pre-training and Supervised Fine-tuning (SFT) poses a central challenge in Reinforcement Learning from Human Feedback (RLHF). In this paper, we first discover that interpolating RLHF and SFT model parameters can adjust the trade-off between human preference and basic capabilities, thereby reducing the alignment tax at the cost of alignment reward. Inspired by this, we propose integrating the RL policy and SFT models at each optimization step in RLHF to continuously regulate the training direction, introducing the Online Merging Optimizer. Specifically, we merge gradients with the parameter differences between SFT and pretrained models, effectively steering the gradient towards maximizing rewards in the direction of SFT optimization. We demonstrate that our optimizer works well with different LLM families, such as Qwen and LLaMA, across various model sizes ranging from 1.8B to 8B, various RLHF algorithms like DPO and KTO, and existing model merging methods. It significantly enhances alignment reward while mitigating alignment tax, achieving higher overall performance across 14 benchmarks.
5/29/2024