Boosting Visual Recognition for Autonomous Driving in Real-world Degradations with Deep Channel Prior

0
Sign in to get full access
Overview
- This paper proposes a deep learning-based method to improve visual recognition in autonomous driving systems, even in the presence of real-world degradations like rain, fog, or haze.
- The key idea is to leverage a "deep channel prior" - an unsupervised feature enhancement module that can adaptively boost visual features to enhance performance.
- The authors demonstrate significant improvements in object detection and instance segmentation tasks on standard autonomous driving benchmarks, even under challenging environmental conditions.
Plain English Explanation
Imagine you're building a self-driving car. A crucial part of this is the car's ability to accurately recognize and identify objects around it - things like other vehicles, pedestrians, traffic signals, etc. This allows the car to navigate safely and make the right decisions.
However, real-world driving conditions can make this visual recognition task much harder. Things like heavy rain, thick fog, or dust in the air can degrade the quality of the camera images the car is using. As a result, the car's object detection and understanding suffers.
This paper introduces a new technique to help overcome these challenges. The key idea is to use a type of deep learning model that can automatically "enhance" the visual features in the camera images, even when they are degraded by real-world conditions. This "deep channel prior" model learns to intelligently boost the useful information in the images, improving the overall visual recognition performance.
The authors show that by incorporating this deep channel prior module, their self-driving system can maintain high accuracy in object detection and segmentation, even when tested in rainy, foggy, or hazy conditions. This is an important advance, as it makes autonomous driving systems more robust and reliable for real-world deployment.
Technical Explanation
The paper proposes a deep learning framework that leverages a "deep channel prior" module to boost the visual recognition performance of autonomous driving systems in the presence of real-world degradations.
The overall architecture consists of a base visual recognition model (e.g. an object detector or instance segmentation network) paired with the deep channel prior module. This prior module takes the raw camera input and learns to automatically enhance the visual features, without any explicit supervision.
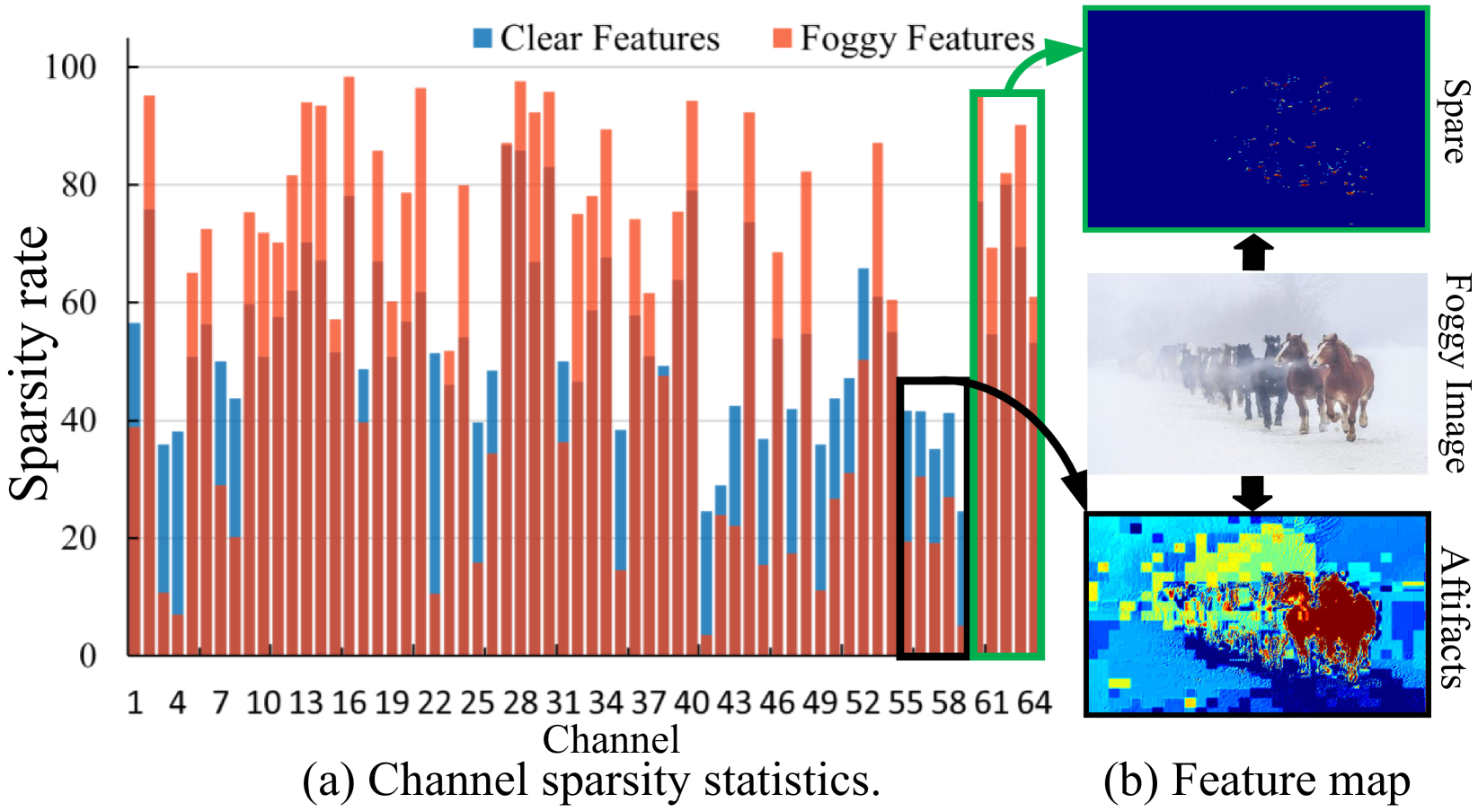
The key insight is that the deep channel prior can adaptively adjust the feature representations to compensate for degradations like rain, fog, or haze. This is achieved through an unsupervised training process that encourages the model to learn a set of latent "prior" channels that capture the essential visual information, even in the presence of distortions.
During inference, the enhanced features produced by the deep channel prior are then fed into the base visual recognition model, boosting its performance on tasks like object detection and instance segmentation. The authors demonstrate substantial improvements over standard models across multiple benchmark datasets, with the gains particularly pronounced in challenging degraded conditions.
Critical Analysis
The paper presents a compelling approach to improving the robustness of autonomous driving vision systems. The proposed deep channel prior module is a clever way to adaptively enhance visual features without requiring any labeled data for the degradation conditions.
One potential limitation is that the training process for the deep channel prior may be computationally expensive, as it involves an iterative optimization procedure. The authors do not provide details on the training time or computational cost, which would be important for real-world deployment.
Additionally, the paper focuses on evaluating the approach on standard autonomous driving benchmarks, but does not explore how it would generalize to more diverse real-world driving scenarios. Further testing in even more challenging conditions, such as extremely poor visibility or unusual weather events, could help validate the broader applicability of the technique.
Finally, while the performance gains are significant, it would be helpful to understand the specific failure cases or edge cases where the deep channel prior approach still struggles. This could inform future research directions to make the systems even more robust.
Overall, this is an impressive and impactful piece of research that advances the state of the art in robust visual recognition for autonomous driving. The deep channel prior concept is a promising direction that could find broader applications beyond just self-driving cars.
Conclusion
This paper presents a novel deep learning-based approach to boost the visual recognition capabilities of autonomous driving systems, even in the presence of real-world degradations like rain, fog, or haze. By incorporating a deep channel prior module that can adaptively enhance visual features, the authors demonstrate significant improvements in object detection and instance segmentation performance on standard autonomous driving benchmarks.
This work is an important step towards building more robust and reliable self-driving car systems that can function reliably in diverse, challenging environmental conditions. The deep channel prior concept offers a compelling way to make vision-based autonomous systems more resilient, which could have far-reaching implications for the safe deployment of self-driving technology in the real world.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
Boosting Visual Recognition for Autonomous Driving in Real-world Degradations with Deep Channel Prior
Zhanwen Liu, Yuhang Li, Yang Wang, Bolin Gao, Yisheng An, Xiangmo Zhao
The environmental perception of autonomous vehicles in normal conditions have achieved considerable success in the past decade. However, various unfavourable conditions such as fog, low-light, and motion blur will degrade image quality and pose tremendous threats to the safety of autonomous driving. That is, when applied to degraded images, state-of-the-art visual models often suffer performance decline due to the feature content loss and artifact interference caused by statistical and structural properties disruption of captured images. To address this problem, this work proposes a novel Deep Channel Prior (DCP) for degraded visual recognition. Specifically, we observe that, in the deep representation space of pre-trained models, the channel correlations of degraded features with the same degradation type have uniform distribution even if they have different content and semantics, which can facilitate the mapping relationship learning between degraded and clear representations in high-sparsity feature space. Based on this, a novel plug-and-play Unsupervised Feature Enhancement Module (UFEM) is proposed to achieve unsupervised feature correction, where the multi-adversarial mechanism is introduced in the first stage of UFEM to achieve the latent content restoration and artifact removal in high-sparsity feature space. Then, the generated features are transferred to the second stage for global correlation modulation under the guidance of DCP to obtain high-quality and recognition-friendly features. Evaluations of three tasks and eight benchmark datasets demonstrate that our proposed method can comprehensively improve the performance of pre-trained models in real degradation conditions. The source code is available at https://github.com/liyuhang166/Deep_Channel_Prior
Read more5/14/2024

0
Indoor scene recognition from images under visual corruptions
Willams de Lima Costa, Raul Ismayilov, Nicola Strisciuglio, Estefania Talavera Martinez
The classification of indoor scenes is a critical component in various applications, such as intelligent robotics for assistive living. While deep learning has significantly advanced this field, models often suffer from reduced performance due to image corruption. This paper presents an innovative approach to indoor scene recognition that leverages multimodal data fusion, integrating caption-based semantic features with visual data to enhance both accuracy and robustness against corruption. We examine two multimodal networks that synergize visual features from CNN models with semantic captions via a Graph Convolutional Network (GCN). Our study shows that this fusion markedly improves model performance, with notable gains in Top-1 accuracy when evaluated against a corrupted subset of the Places365 dataset. Moreover, while standalone visual models displayed high accuracy on uncorrupted images, their performance deteriorated significantly with increased corruption severity. Conversely, the multimodal models demonstrated improved accuracy in clean conditions and substantial robustness to a range of image corruptions. These results highlight the efficacy of incorporating high-level contextual information through captions, suggesting a promising direction for enhancing the resilience of classification systems.
Read more8/26/2024

0
DCPI-Depth: Explicitly Infusing Dense Correspondence Prior to Unsupervised Monocular Depth Estimation
Mengtan Zhang, Yi Feng, Qijun Chen, Rui Fan
There has been a recent surge of interest in learning to perceive depth from monocular videos in an unsupervised fashion. A key challenge in this field is achieving robust and accurate depth estimation in challenging scenarios, particularly in regions with weak textures or where dynamic objects are present. This study makes three major contributions by delving deeply into dense correspondence priors to provide existing frameworks with explicit geometric constraints. The first novelty is a contextual-geometric depth consistency loss, which employs depth maps triangulated from dense correspondences based on estimated ego-motion to guide the learning of depth perception from contextual information, since explicitly triangulated depth maps capture accurate relative distances among pixels. The second novelty arises from the observation that there exists an explicit, deducible relationship between optical flow divergence and depth gradient. A differential property correlation loss is, therefore, designed to refine depth estimation with a specific emphasis on local variations. The third novelty is a bidirectional stream co-adjustment strategy that enhances the interaction between rigid and optical flows, encouraging the former towards more accurate correspondence and making the latter more adaptable across various scenarios under the static scene hypotheses. DCPI-Depth, a framework that incorporates all these innovative components and couples two bidirectional and collaborative streams, achieves state-of-the-art performance and generalizability across multiple public datasets, outperforming all existing prior arts. Specifically, it demonstrates accurate depth estimation in texture-less and dynamic regions, and shows more reasonable smoothness.
Read more5/28/2024

0
A Physical Model-Guided Framework for Underwater Image Enhancement and Depth Estimation
Dazhao Du, Enhan Li, Lingyu Si, Fanjiang Xu, Jianwei Niu, Fuchun Sun
Due to the selective absorption and scattering of light by diverse aquatic media, underwater images usually suffer from various visual degradations. Existing underwater image enhancement (UIE) approaches that combine underwater physical imaging models with neural networks often fail to accurately estimate imaging model parameters such as depth and veiling light, resulting in poor performance in certain scenarios. To address this issue, we propose a physical model-guided framework for jointly training a Deep Degradation Model (DDM) with any advanced UIE model. DDM includes three well-designed sub-networks to accurately estimate various imaging parameters: a veiling light estimation sub-network, a factors estimation sub-network, and a depth estimation sub-network. Based on the estimated parameters and the underwater physical imaging model, we impose physical constraints on the enhancement process by modeling the relationship between underwater images and desired clean images, i.e., outputs of the UIE model. Moreover, while our framework is compatible with any UIE model, we design a simple yet effective fully convolutional UIE model, termed UIEConv. UIEConv utilizes both global and local features for image enhancement through a dual-branch structure. UIEConv trained within our framework achieves remarkable enhancement results across diverse underwater scenes. Furthermore, as a byproduct of UIE, the trained depth estimation sub-network enables accurate underwater scene depth estimation. Extensive experiments conducted in various real underwater imaging scenarios, including deep-sea environments with artificial light sources, validate the effectiveness of our framework and the UIEConv model.
Read more7/8/2024