DCPI-Depth: Explicitly Infusing Dense Correspondence Prior to Unsupervised Monocular Depth Estimation
2405.16960
0
0

Abstract
There has been a recent surge of interest in learning to perceive depth from monocular videos in an unsupervised fashion. A key challenge in this field is achieving robust and accurate depth estimation in challenging scenarios, particularly in regions with weak textures or where dynamic objects are present. This study makes three major contributions by delving deeply into dense correspondence priors to provide existing frameworks with explicit geometric constraints. The first novelty is a contextual-geometric depth consistency loss, which employs depth maps triangulated from dense correspondences based on estimated ego-motion to guide the learning of depth perception from contextual information, since explicitly triangulated depth maps capture accurate relative distances among pixels. The second novelty arises from the observation that there exists an explicit, deducible relationship between optical flow divergence and depth gradient. A differential property correlation loss is, therefore, designed to refine depth estimation with a specific emphasis on local variations. The third novelty is a bidirectional stream co-adjustment strategy that enhances the interaction between rigid and optical flows, encouraging the former towards more accurate correspondence and making the latter more adaptable across various scenarios under the static scene hypotheses. DCPI-Depth, a framework that incorporates all these innovative components and couples two bidirectional and collaborative streams, achieves state-of-the-art performance and generalizability across multiple public datasets, outperforming all existing prior arts. Specifically, it demonstrates accurate depth estimation in texture-less and dynamic regions, and shows more reasonable smoothness.
Create account to get full access
Overview
- The paper presents a novel method called DCPI-Depth for unsupervised monocular depth estimation.
- The key innovation is the explicit infusion of dense correspondence prior information to improve depth estimation, especially for dynamic objects.
- The method leverages geometric constraints to capture dense correspondence between images, which is then used to guide the depth estimation process.
- This allows the model to better handle challenging scenarios like dynamic objects, which are often difficult for traditional unsupervised depth estimation approaches.
Plain English Explanation
The paper describes a new way to estimate depth from a single camera, without any labeled training data. Depth estimation is the process of determining how far away objects are from the camera. This is a challenging problem, especially when the scene contains moving objects.
The researchers developed a method called DCPI-Depth that explicitly incorporates information about the geometric relationship between images. By finding dense correspondences - identifying which pixels in one image match up with pixels in another image - the model can better understand the 3D structure of the scene, including moving objects.
This dense correspondence prior information helps guide the depth estimation process, allowing the model to produce more accurate depth maps, even in complex scenes with dynamic elements. The key insight is that by understanding how objects and pixels are related across multiple views, the model can overcome some of the limitations of traditional unsupervised depth estimation techniques.
Technical Explanation
The paper introduces a new unsupervised monocular depth estimation method called DCPI-Depth that explicitly infuses dense correspondence prior information. The core idea is to leverage geometric constraints to capture dense correspondence between input images, and then use this information to guide the depth estimation process.
The DCPI-Depth architecture consists of several key components. First, there is a depth estimation network that produces a per-pixel depth map from a single input image. Second, there is a correspondence network that finds dense pixel-level matches between pairs of input images. The correspondence information is then repurposed to refine the depth estimates.
This dense correspondence prior information is particularly helpful for handling dynamic objects, which are often challenging for traditional unsupervised depth estimation approaches. By understanding how pixels move and match across views, the model can better infer the 3D structure of the scene, including moving elements.
The researchers evaluate DCPI-Depth on several standard benchmarks for unsupervised monocular depth estimation, demonstrating state-of-the-art performance. The method is also shown to be robust to different sensor modalities and to refine depth edges with sparse supervision.
Critical Analysis
The paper makes a compelling case for the benefits of incorporating dense correspondence prior information for unsupervised monocular depth estimation. The experiments demonstrate the method's ability to handle challenging scenarios like dynamic objects, which is an important capability.
However, the paper does not deeply explore the limitations of the approach. For example, it is unclear how well DCPI-Depth would perform in highly cluttered scenes or environments with significant occlusions, where the dense correspondence estimation may become more challenging. Additionally, the computational cost of the dense correspondence network is not discussed, which could be an important practical consideration.
Further research could also investigate ways to make the correspondence estimation more robust, perhaps by leveraging self-supervised representation learning or other techniques. Exploring how the dense correspondence prior could be combined with other depth cues, such as sensor-agnostic depth prompting, may also lead to further performance improvements.
Overall, the DCPI-Depth method represents a promising step forward in unsupervised monocular depth estimation, with the potential to significantly impact applications that rely on accurate 3D scene understanding from a single camera.
Conclusion
The DCPI-Depth paper presents a novel approach to unsupervised monocular depth estimation that explicitly incorporates dense correspondence prior information. By leveraging geometric constraints to capture the relationship between input images, the method is able to better handle challenging scenarios, such as scenes with dynamic objects.
The experiments demonstrate the effectiveness of this approach, with DCPI-Depth achieving state-of-the-art performance on standard benchmarks. While the paper does not fully explore the limitations of the method, it represents an important contribution to the field of 3D scene understanding from single-view imagery, with potential applications in areas like autonomous navigation, augmented reality, and computational photography.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
📈
Mining Supervision for Dynamic Regions in Self-Supervised Monocular Depth Estimation
Hoang Chuong Nguyen, Tianyu Wang, Jose M. Alvarez, Miaomiao Liu
0
0
This paper focuses on self-supervised monocular depth estimation in dynamic scenes trained on monocular videos. Existing methods jointly estimate pixel-wise depth and motion, relying mainly on an image reconstruction loss. Dynamic regions1 remain a critical challenge for these methods due to the inherent ambiguity in depth and motion estimation, resulting in inaccurate depth estimation. This paper proposes a self-supervised training framework exploiting pseudo depth labels for dynamic regions from training data. The key contribution of our framework is to decouple depth estimation for static and dynamic regions of images in the training data. We start with an unsupervised depth estimation approach, which provides reliable depth estimates for static regions and motion cues for dynamic regions and allows us to extract moving object information at the instance level. In the next stage, we use an object network to estimate the depth of those moving objects assuming rigid motions. Then, we propose a new scale alignment module to address the scale ambiguity between estimated depths for static and dynamic regions. We can then use the depth labels generated to train an end-to-end depth estimation network and improve its performance. Extensive experiments on the Cityscapes and KITTI datasets show that our self-training strategy consistently outperforms existing self/unsupervised depth estimation methods.
4/24/2024
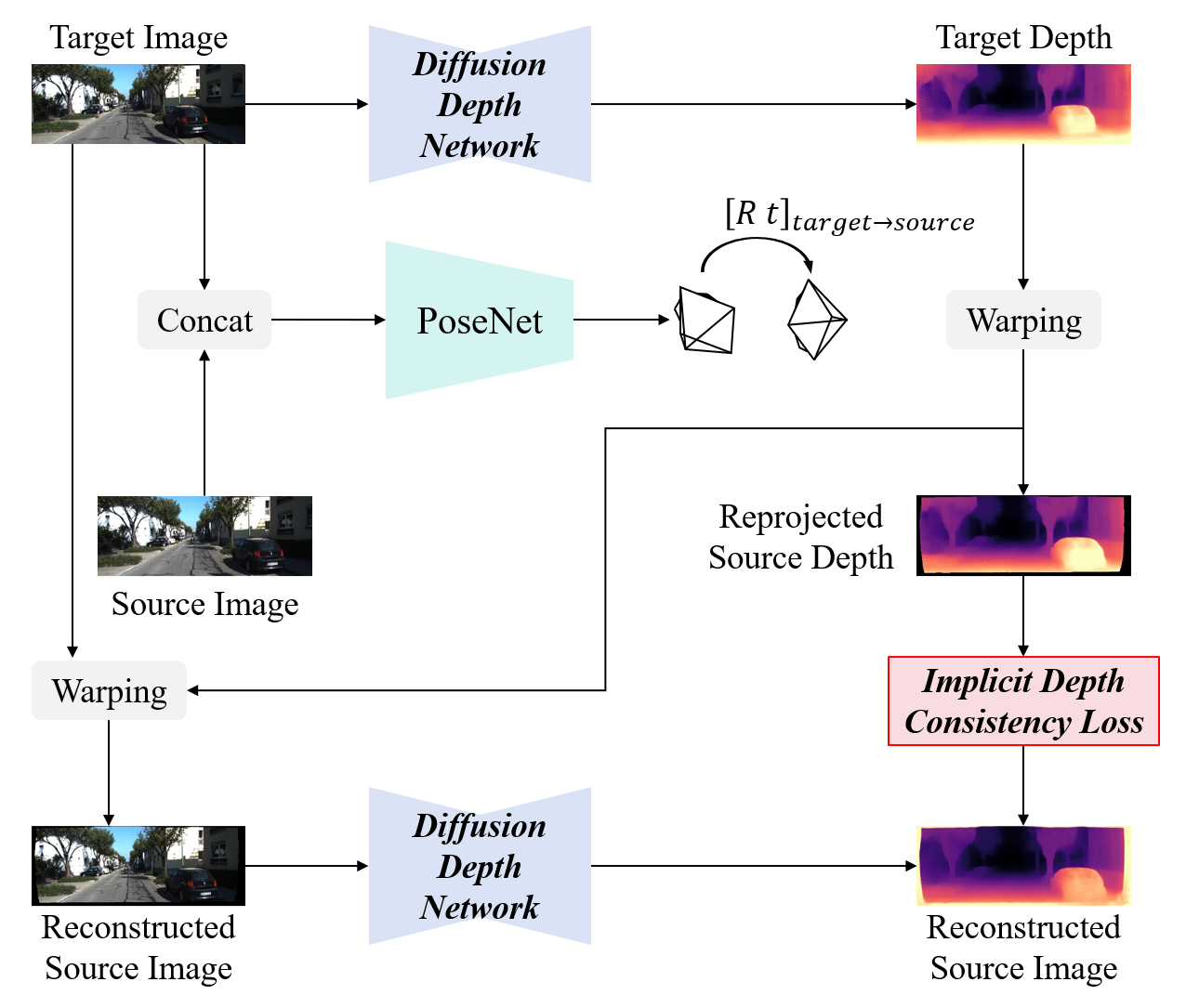
Unsupervised Monocular Depth Estimation Based on Hierarchical Feature-Guided Diffusion
Runze Liu, Dongchen Zhu, Guanghui Zhang, Yue Xu, Wenjun Shi, Xiaolin Zhang, Lei Wang, Jiamao Li
0
0
Unsupervised monocular depth estimation has received widespread attention because of its capability to train without ground truth. In real-world scenarios, the images may be blurry or noisy due to the influence of weather conditions and inherent limitations of the camera. Therefore, it is particularly important to develop a robust depth estimation model. Benefiting from the training strategies of generative networks, generative-based methods often exhibit enhanced robustness. In light of this, we employ a well-converging diffusion model among generative networks for unsupervised monocular depth estimation. Additionally, we propose a hierarchical feature-guided denoising module. This model significantly enriches the model's capacity for learning and interpreting depth distribution by fully leveraging image features to guide the denoising process. Furthermore, we explore the implicit depth within reprojection and design an implicit depth consistency loss. This loss function serves to enhance the performance of the model and ensure the scale consistency of depth within a video sequence. We conduct experiments on the KITTI, Make3D, and our self-collected SIMIT datasets. The results indicate that our approach stands out among generative-based models, while also showcasing remarkable robustness.
6/17/2024
🖼️
Repurposing Diffusion-Based Image Generators for Monocular Depth Estimation
Bingxin Ke, Anton Obukhov, Shengyu Huang, Nando Metzger, Rodrigo Caye Daudt, Konrad Schindler
0
0
Monocular depth estimation is a fundamental computer vision task. Recovering 3D depth from a single image is geometrically ill-posed and requires scene understanding, so it is not surprising that the rise of deep learning has led to a breakthrough. The impressive progress of monocular depth estimators has mirrored the growth in model capacity, from relatively modest CNNs to large Transformer architectures. Still, monocular depth estimators tend to struggle when presented with images with unfamiliar content and layout, since their knowledge of the visual world is restricted by the data seen during training, and challenged by zero-shot generalization to new domains. This motivates us to explore whether the extensive priors captured in recent generative diffusion models can enable better, more generalizable depth estimation. We introduce Marigold, a method for affine-invariant monocular depth estimation that is derived from Stable Diffusion and retains its rich prior knowledge. The estimator can be fine-tuned in a couple of days on a single GPU using only synthetic training data. It delivers state-of-the-art performance across a wide range of datasets, including over 20% performance gains in specific cases. Project page: https://marigoldmonodepth.github.io.
4/4/2024

Learning Temporally Consistent Video Depth from Video Diffusion Priors
Jiahao Shao, Yuanbo Yang, Hongyu Zhou, Youmin Zhang, Yujun Shen, Matteo Poggi, Yiyi Liao
0
0
This work addresses the challenge of video depth estimation, which expects not only per-frame accuracy but, more importantly, cross-frame consistency. Instead of directly developing a depth estimator from scratch, we reformulate the prediction task into a conditional generation problem. This allows us to leverage the prior knowledge embedded in existing video generation models, thereby reducing learning difficulty and enhancing generalizability. Concretely, we study how to tame the public Stable Video Diffusion (SVD) to predict reliable depth from input videos using a mixture of image depth and video depth datasets. We empirically confirm that a procedural training strategy -- first optimizing the spatial layers of SVD and then optimizing the temporal layers while keeping the spatial layers frozen -- yields the best results in terms of both spatial accuracy and temporal consistency. We further examine the sliding window strategy for inference on arbitrarily long videos. Our observations indicate a trade-off between efficiency and performance, with a one-frame overlap already producing favorable results. Extensive experimental results demonstrate the superiority of our approach, termed ChronoDepth, over existing alternatives, particularly in terms of the temporal consistency of the estimated depth. Additionally, we highlight the benefits of more consistent video depth in two practical applications: depth-conditioned video generation and novel view synthesis. Our project page is available at https://jhaoshao.github.io/ChronoDepth/.
6/5/2024