Bootstrapping Language Models with DPO Implicit Rewards
2406.09760
0
0
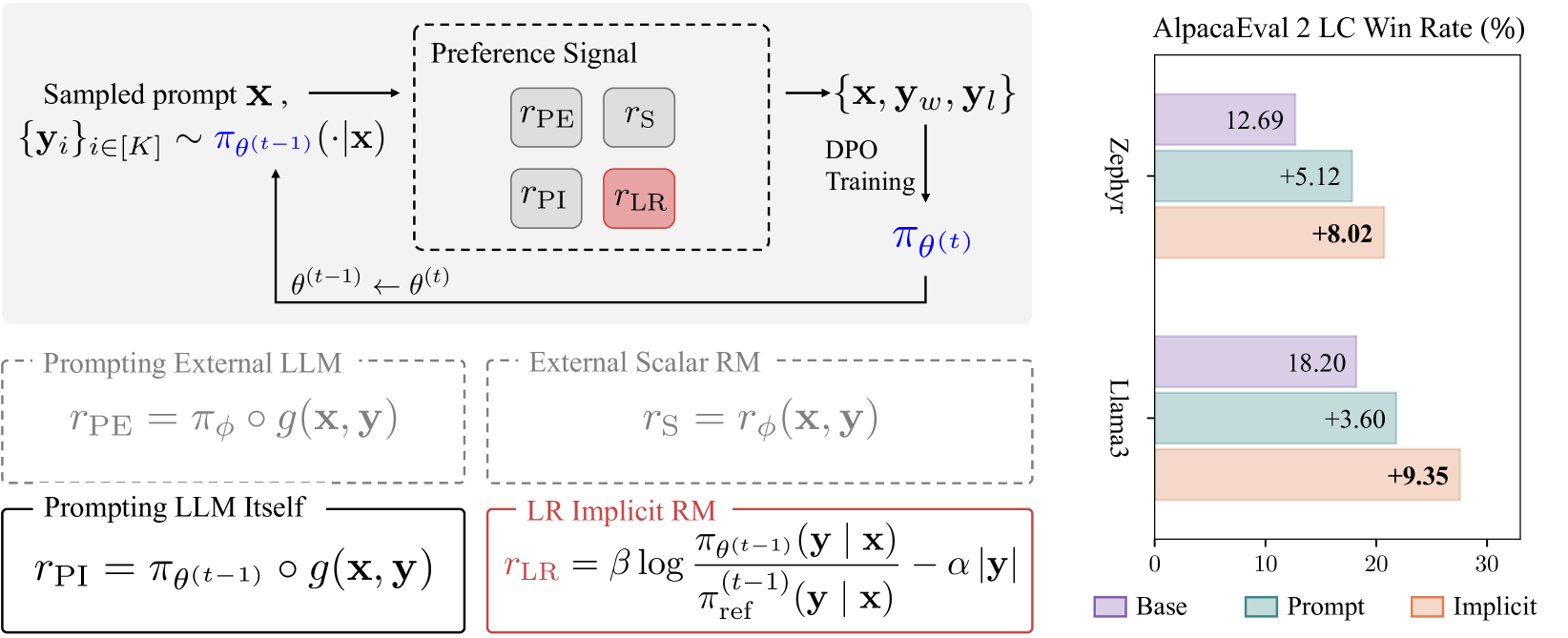
Abstract
Human alignment in large language models (LLMs) is an active area of research. A recent groundbreaking work, direct preference optimization (DPO), has greatly simplified the process from past work in reinforcement learning from human feedback (RLHF) by bypassing the reward learning stage in RLHF. DPO, after training, provides an implicit reward model. In this work, we make a novel observation that this implicit reward model can by itself be used in a bootstrapping fashion to further align the LLM. Our approach is to use the rewards from a current LLM model to construct a preference dataset, which is then used in subsequent DPO rounds. We incorporate refinements that debias the length of the responses and improve the quality of the preference dataset to further improve our approach. Our approach, named self-alignment with DPO ImpliCit rEwards (DICE), shows great improvements in alignment and achieves superior performance than Gemini Pro on AlpacaEval 2, reaching 27.55% length-controlled win rate against GPT-4 Turbo, but with only 8B parameters and no external feedback. Our code is available at https://github.com/sail-sg/dice.
Create account to get full access
Overview
- This paper explores a novel approach called Bootstrapping Language Models with DPO Implicit Rewards, which aims to improve the alignment of language models with human preferences.
- The key ideas include using Discrete Preference Optimization (DPO) to guide language model training, and incorporating implicit rewards derived from human feedback.
- The authors conduct experiments to assess the effectiveness of their approach and compare it to other techniques like Direct Alignment of Language Models via Quality-Aware and Robust Preference Optimization through Reward Model Distillation.
Plain English Explanation
The paper discusses a new way to train language models, like the ones used in chatbots and writing assistants, to better align with human preferences and values. The key idea is to use a technique called Discrete Preference Optimization (DPO) to guide the language model's training. DPO allows the model to learn from implicit feedback, rather than just relying on explicit labels or rewards.
The researchers also incorporate "implicit rewards" derived from human feedback, which helps the model understand what kinds of outputs are preferred by people. This is intended to make the language model's behavior more aligned with human values and preferences, rather than just trying to generate the most statistically likely text.
The authors compare their approach to other methods, like Direct Alignment of Language Models via Quality-Aware and Robust Preference Optimization through Reward Model Distillation, to see how well it performs. The goal is to develop language models that are more reliable, trustworthy, and beneficial to humans.
Technical Explanation
The paper introduces a novel approach called "Bootstrapping Language Models with DPO Implicit Rewards" to improve the alignment of language models with human preferences. The key components of their approach are:
-
Discrete Preference Optimization (DPO): The authors use DPO to guide the language model's training, which allows the model to learn from implicit feedback rather than just explicit labels or rewards. This helps the model better understand human preferences.
-
Implicit Rewards: The researchers derive "implicit rewards" from human feedback, which are then used to further align the language model's behavior with what people prefer. This is in contrast to relying solely on explicit rewards or labels.
The paper compares this approach to other techniques like Direct Alignment of Language Models via Quality-Aware and Robust Preference Optimization through Reward Model Distillation. The experiments assess the effectiveness of the proposed method in terms of language model alignment, preference satisfaction, and other relevant metrics.
Critical Analysis
The paper provides a well-designed and thorough evaluation of the Bootstrapping Language Models with DPO Implicit Rewards approach. However, the authors acknowledge some limitations and areas for further research:
- The implicit reward signals derived from human feedback may not be fully representative of human preferences, and could potentially introduce biases.
- The effectiveness of the approach may be sensitive to the specific implementation details and hyperparameter choices, which could limit its generalizability.
- It would be valuable to explore the long-term effects of this approach on language model behavior and alignment, as well as its scalability to larger and more complex models.
Additionally, one could question whether the implicit rewards truly capture the full breadth of human preferences, or if there are other factors that should be considered to achieve more comprehensive alignment. Further research is needed to address these concerns and refine the techniques.
Conclusion
This paper presents a promising approach, Bootstrapping Language Models with DPO Implicit Rewards, for improving the alignment of language models with human preferences and values. By incorporating Discrete Preference Optimization and implicit rewards derived from user feedback, the authors demonstrate a way to train language models that are more reliable, trustworthy, and beneficial to people.
The findings of this research have the potential to significantly impact the development of advanced language models, particularly in applications where alignment with human preferences is crucial, such as conversational AI, content generation, and decision support systems. As the field of AI continues to evolve, techniques like the one proposed in this paper will be increasingly important in ensuring that these powerful technologies are designed and deployed in a responsible and ethical manner.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Direct Alignment of Language Models via Quality-Aware Self-Refinement
Runsheng Yu, Yong Wang, Xiaoqi Jiao, Youzhi Zhang, James T. Kwok
0
0
Reinforcement Learning from Human Feedback (RLHF) has been commonly used to align the behaviors of Large Language Models (LLMs) with human preferences. Recently, a popular alternative is Direct Policy Optimization (DPO), which replaces an LLM-based reward model with the policy itself, thus obviating the need for extra memory and training time to learn the reward model. However, DPO does not consider the relative qualities of the positive and negative responses, and can lead to sub-optimal training outcomes. To alleviate this problem, we investigate the use of intrinsic knowledge within the on-the-fly fine-tuning LLM to obtain relative qualities and help to refine the loss function. Specifically, we leverage the knowledge of the LLM to design a refinement function to estimate the quality of both the positive and negative responses. We show that the constructed refinement function can help self-refine the loss function under mild assumptions. The refinement function is integrated into DPO and its variant Identity Policy Optimization (IPO). Experiments across various evaluators indicate that they can improve the performance of the fine-tuned models over DPO and IPO.
6/3/2024

Robust Preference Optimization through Reward Model Distillation
Adam Fisch, Jacob Eisenstein, Vicky Zayats, Alekh Agarwal, Ahmad Beirami, Chirag Nagpal, Pete Shaw, Jonathan Berant
0
0
Language model (LM) post-training (or alignment) involves maximizing a reward function that is derived from preference annotations. Direct Preference Optimization (DPO) is a popular offline alignment method that trains a policy directly on preference data without the need to train a reward model or apply reinforcement learning. However, typical preference datasets have only a single, or at most a few, annotation per preference pair, which causes DPO to overconfidently assign rewards that trend towards infinite magnitude. This frequently leads to degenerate policies, sometimes causing even the probabilities of the preferred generations to go to zero. In this work, we analyze this phenomenon and propose distillation to get a better proxy for the true preference distribution over generation pairs: we train the LM to produce probabilities that match the distribution induced by a reward model trained on the preference data. Moreover, to account for uncertainty in the reward model we are distilling from, we optimize against a family of reward models that, as a whole, is likely to include at least one reasonable proxy for the preference distribution. Our results show that distilling from such a family of reward models leads to improved robustness to distribution shift in preference annotations, while preserving the simple supervised nature of DPO.
5/30/2024
Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level
Jie Liu, Zhanhui Zhou, Jiaheng Liu, Xingyuan Bu, Chao Yang, Han-Sen Zhong, Wanli Ouyang
0
0
Direct Preference Optimization (DPO), a standard method for aligning language models with human preferences, is traditionally applied to offline preferences. Recent studies show that DPO benefits from iterative training with online preferences labeled by a trained reward model. In this work, we identify a pitfall of vanilla iterative DPO - improved response quality can lead to increased verbosity. To address this, we introduce iterative length-regularized DPO (iLR-DPO) to penalize response length. Our empirical results show that iLR-DPO can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. Specifically, our 7B model achieves a $50.5%$ length-controlled win rate against $texttt{GPT-4 Preview}$ on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard. These results demonstrate the effectiveness of iterative DPO in aligning language models with human feedback.
6/18/2024

Direct Preference Optimization With Unobserved Preference Heterogeneity
Keertana Chidambaram, Karthik Vinay Seetharaman, Vasilis Syrgkanis
0
0
RLHF has emerged as a pivotal step in aligning language models with human objectives and values. It typically involves learning a reward model from human preference data and then using reinforcement learning to update the generative model accordingly. Conversely, Direct Preference Optimization (DPO) directly optimizes the generative model with preference data, skipping reinforcement learning. However, both RLHF and DPO assume uniform preferences, overlooking the reality of diverse human annotators. This paper presents a new method to align generative models with varied human preferences. We propose an Expectation-Maximization adaptation to DPO, generating a mixture of models based on latent preference types of the annotators. We then introduce a min-max regret ensemble learning model to produce a single generative method to minimize worst-case regret among annotator subgroups with similar latent factors. Our algorithms leverage the simplicity of DPO while accommodating diverse preferences. Experimental results validate the effectiveness of our approach in producing equitable generative policies.
5/27/2024