Iterative Length-Regularized Direct Preference Optimization: A Case Study on Improving 7B Language Models to GPT-4 Level
2406.11817
0
0
Abstract
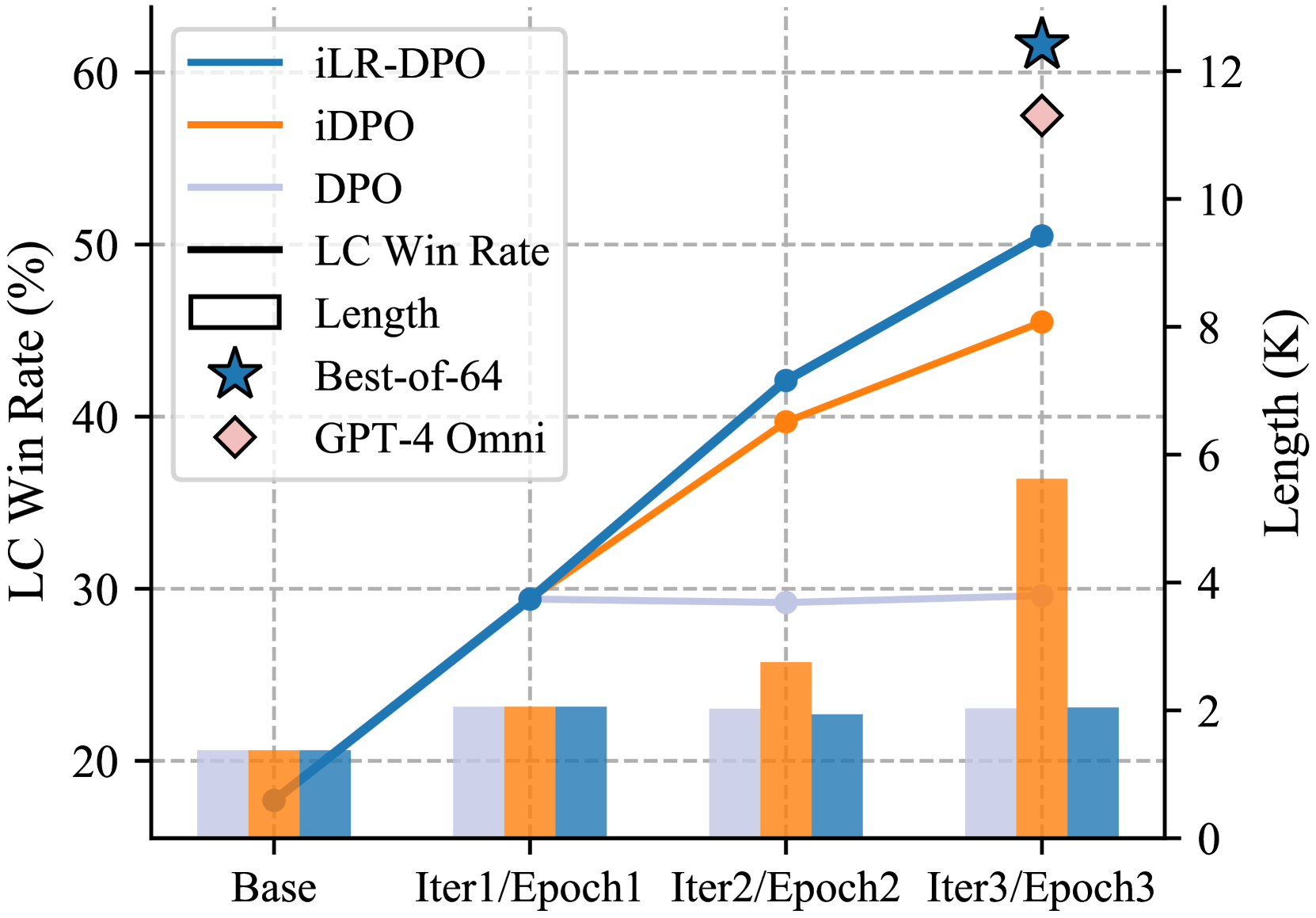
Direct Preference Optimization (DPO), a standard method for aligning language models with human preferences, is traditionally applied to offline preferences. Recent studies show that DPO benefits from iterative training with online preferences labeled by a trained reward model. In this work, we identify a pitfall of vanilla iterative DPO - improved response quality can lead to increased verbosity. To address this, we introduce iterative length-regularized DPO (iLR-DPO) to penalize response length. Our empirical results show that iLR-DPO can enhance a 7B model to perform on par with GPT-4 without increasing verbosity. Specifically, our 7B model achieves a $50.5%$ length-controlled win rate against $texttt{GPT-4 Preview}$ on AlpacaEval 2.0, and excels across standard benchmarks including MT-Bench, Arena-Hard and OpenLLM Leaderboard. These results demonstrate the effectiveness of iterative DPO in aligning language models with human feedback.
Create account to get full access
Overview
- This paper presents a novel technique called Iterative Length-Regularized Direct Preference Optimization (iLR-DPO) for improving the performance of 7B language models to the level of GPT-4.
- The approach combines elements from bootstrapping language models with DPO, direct preference optimization with offset, token-level DPO, and filtered DPO to address the issue of biased length reliance in direct preference optimization.
Plain English Explanation
The paper describes a new method for training large language models like GPT-4 to perform better. The key idea is to combine several existing techniques in a novel way to address a problem called "biased length reliance." This means that the language model tends to prefer generating shorter or longer text, which can lead to suboptimal performance.
The new method, called iLR-DPO, iteratively adjusts the model to overcome this bias. It does this by directly optimizing the model's preferences, while also regularizing the length of the output. This helps the model generate high-quality text without being overly influenced by length. The authors test this approach on a 7B language model and show that it can match the performance of the much larger GPT-4 model.
Technical Explanation
The paper introduces a new technique called Iterative Length-Regularized Direct Preference Optimization (iLR-DPO) that builds on several existing approaches to address the issue of biased length reliance in direct preference optimization.
The core elements of iLR-DPO include:
- Bootstrapping language models with DPO and implicit rewards: Using DPO to fine-tune a pre-trained language model based on human preferences.
- Direct preference optimization with offset: Optimizing the model's preferences directly, rather than just maximizing the likelihood of the training data.
- Token-level DPO: Applying DPO at the token level, rather than just at the sequence level.
- Filtered DPO: Filtering the training data to remove low-quality samples and focus the optimization on high-quality ones.
The key innovation in iLR-DPO is the addition of a length regularization term to the objective function. This helps the model generate text that is not overly biased towards shorter or longer outputs, which can improve its overall performance.
The authors test iLR-DPO on a 7B language model and show that it can match the performance of the much larger GPT-4 model, which has 175B parameters. This suggests that iLR-DPO is a promising approach for improving the capabilities of large language models without the need for significantly more computational resources.
Critical Analysis
The paper provides a thorough and well-designed study that addresses an important issue in language model training. The authors acknowledge several limitations and areas for further research, including the need to better understand the underlying mechanisms of the length regularization and the potential for the approach to be extended to other language modeling tasks.
One potential concern is the reliance on human preference data, which can be subjective and may not fully capture the nuances of language quality. Additionally, the authors note that the iLR-DPO approach may be computationally intensive, which could limit its practical applicability for certain use cases.
Despite these caveats, the paper presents a compelling and innovative solution to a critical problem in language model development. The combination of existing techniques in a novel way, along with the impressive performance results, suggests that iLR-DPO is a valuable contribution to the field of natural language processing.
Conclusion
This paper introduces a new technique called Iterative Length-Regularized Direct Preference Optimization (iLR-DPO) that can significantly improve the performance of 7B language models to match the capabilities of the much larger GPT-4 model. By combining elements from various existing approaches and introducing a novel length regularization term, the authors have created a powerful tool for addressing the issue of biased length reliance in language model training.
The results demonstrated in this study suggest that iLR-DPO could be a valuable addition to the language modeling toolbox, potentially enabling the development of high-performing models without the need for exponential increases in computational resources. As the field of natural language processing continues to advance, techniques like iLR-DPO will likely play an important role in pushing the boundaries of what is possible with large language models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Step-DPO: Step-wise Preference Optimization for Long-chain Reasoning of LLMs
Xin Lai, Zhuotao Tian, Yukang Chen, Senqiao Yang, Xiangru Peng, Jiaya Jia
0
0
Mathematical reasoning presents a significant challenge for Large Language Models (LLMs) due to the extensive and precise chain of reasoning required for accuracy. Ensuring the correctness of each reasoning step is critical. To address this, we aim to enhance the robustness and factuality of LLMs by learning from human feedback. However, Direct Preference Optimization (DPO) has shown limited benefits for long-chain mathematical reasoning, as models employing DPO struggle to identify detailed errors in incorrect answers. This limitation stems from a lack of fine-grained process supervision. We propose a simple, effective, and data-efficient method called Step-DPO, which treats individual reasoning steps as units for preference optimization rather than evaluating answers holistically. Additionally, we have developed a data construction pipeline for Step-DPO, enabling the creation of a high-quality dataset containing 10K step-wise preference pairs. We also observe that in DPO, self-generated data is more effective than data generated by humans or GPT-4, due to the latter's out-of-distribution nature. Our findings demonstrate that as few as 10K preference data pairs and fewer than 500 Step-DPO training steps can yield a nearly 3% gain in accuracy on MATH for models with over 70B parameters. Notably, Step-DPO, when applied to Qwen2-72B-Instruct, achieves scores of 70.8% and 94.0% on the test sets of MATH and GSM8K, respectively, surpassing a series of closed-source models, including GPT-4-1106, Claude-3-Opus, and Gemini-1.5-Pro. Our code, data, and models are available at https://github.com/dvlab-research/Step-DPO.
6/28/2024
Bootstrapping Language Models with DPO Implicit Rewards
Changyu Chen, Zichen Liu, Chao Du, Tianyu Pang, Qian Liu, Arunesh Sinha, Pradeep Varakantham, Min Lin
0
0
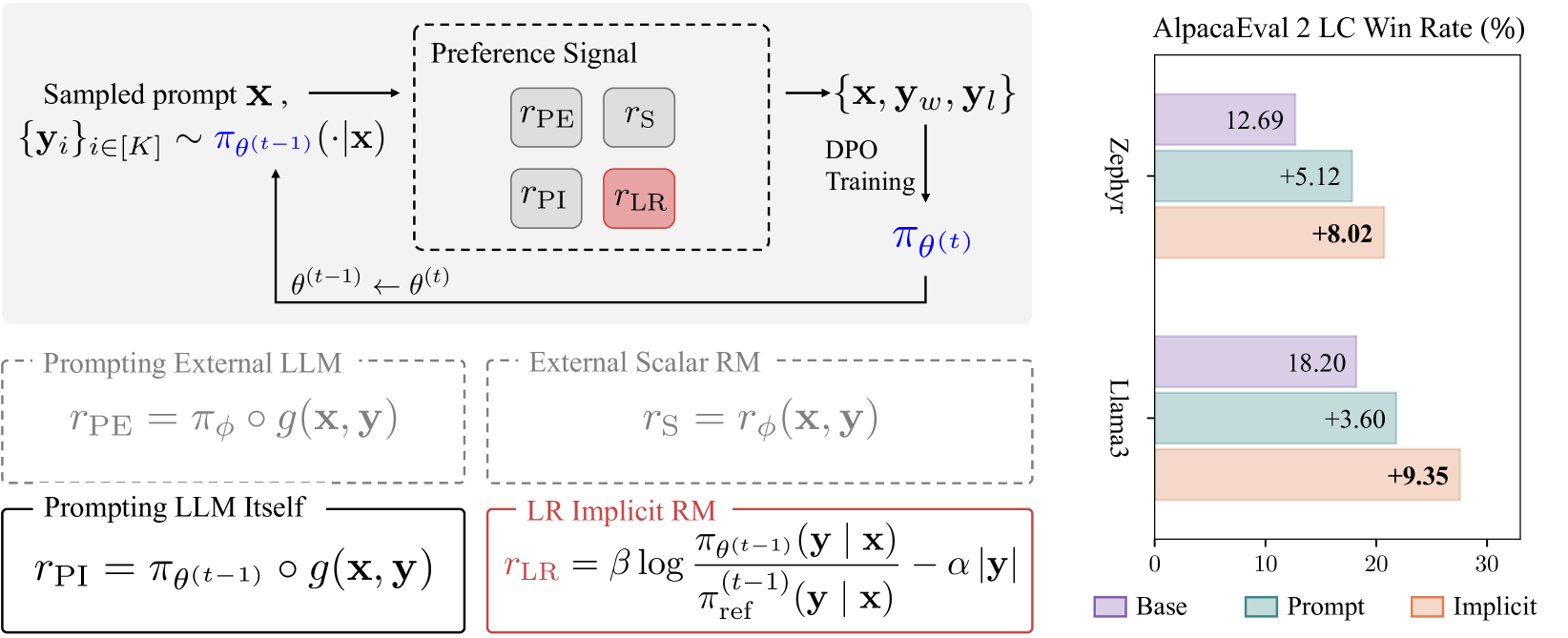
Human alignment in large language models (LLMs) is an active area of research. A recent groundbreaking work, direct preference optimization (DPO), has greatly simplified the process from past work in reinforcement learning from human feedback (RLHF) by bypassing the reward learning stage in RLHF. DPO, after training, provides an implicit reward model. In this work, we make a novel observation that this implicit reward model can by itself be used in a bootstrapping fashion to further align the LLM. Our approach is to use the rewards from a current LLM model to construct a preference dataset, which is then used in subsequent DPO rounds. We incorporate refinements that debias the length of the responses and improve the quality of the preference dataset to further improve our approach. Our approach, named self-alignment with DPO ImpliCit rEwards (DICE), shows great improvements in alignment and achieves superior performance than Gemini Pro on AlpacaEval 2, reaching 27.55% length-controlled win rate against GPT-4 Turbo, but with only 8B parameters and no external feedback. Our code is available at https://github.com/sail-sg/dice.
6/17/2024

Direct Preference Optimization with an Offset
Afra Amini, Tim Vieira, Ryan Cotterell
0
0
Direct preference optimization (DPO) is a successful fine-tuning strategy for aligning large language models with human preferences without the need to train a reward model or employ reinforcement learning. DPO, as originally formulated, relies on binary preference data and fine-tunes a language model to increase the likelihood of a preferred response over a dispreferred response. However, not all preference pairs are equal. Sometimes, the preferred response is only slightly better than the dispreferred one. In other cases, the preference is much stronger. For instance, if a response contains harmful or toxic content, the annotator will have a strong preference for that response. In this paper, we propose a generalization of DPO, termed DPO with an offset (ODPO), that does not treat every preference pair equally during fine-tuning. Intuitively, ODPO requires the difference between the likelihood of the preferred and dispreferred response to be greater than an offset value. The offset is determined based on the extent to which one response is preferred over another. Our experiments on various tasks suggest that ODPO significantly outperforms DPO in aligning language models, especially when the number of preference pairs is limited.
6/7/2024
Filtered Direct Preference Optimization
Tetsuro Morimura, Mitsuki Sakamoto, Yuu Jinnai, Kenshi Abe, Kaito Ariu
0
0
Reinforcement learning from human feedback (RLHF) plays a crucial role in aligning language models with human preferences. While the significance of dataset quality is generally recognized, explicit investigations into its impact within the RLHF framework, to our knowledge, have been limited. This paper addresses the issue of text quality within the preference dataset by focusing on Direct Preference Optimization (DPO), an increasingly adopted reward-model-free RLHF method. We confirm that text quality significantly influences the performance of models optimized with DPO more than those optimized with reward-model-based RLHF. Building on this new insight, we propose an extension of DPO, termed filtered direct preference optimization (fDPO). fDPO uses a trained reward model to monitor the quality of texts within the preference dataset during DPO training. Samples of lower quality are discarded based on comparisons with texts generated by the model being optimized, resulting in a more accurate dataset. Experimental results demonstrate that fDPO enhances the final model performance. Our code is available at https://github.com/CyberAgentAILab/filtered-dpo.
4/24/2024