Bounds on the Generalization Error in Active Learning

0
🔍
Sign in to get full access
Overview
- This paper provides a new framework for analyzing the generalization performance of machine learning models.
- It introduces a novel concept called "local model validity" that quantifies how well a model performs in specific regions of the input space.
- The paper presents theoretical bounds on the generalization error of machine learning models and demonstrates how these bounds can be used to design more effective active learning strategies.
Plain English Explanation
The paper proposes a new way to understand how well machine learning models will perform when applied to new, unseen data. Traditionally, models are evaluated based on their overall performance on a test set. However, this doesn't capture how the model might behave in different parts of the input space.
The key idea is to measure the local model validity, which refers to how well the model performs in specific regions of the input space. This provides a more nuanced understanding of the model's strengths and weaknesses. For example, a model might be highly accurate for certain types of inputs but struggle with others.
By quantifying local model validity, the researchers show how to derive theoretical bounds on the generalization error of the model. Generalization error refers to how well the model will perform on new, unseen data compared to the training data. These bounds can then be used to guide the active learning process, where the model selects the most informative data points to label and train on.
Overall, this work provides a new framework for analyzing and improving the performance of machine learning models, particularly in complex real-world scenarios where the input data can vary significantly.
Technical Explanation
The paper introduces a novel concept called local model validity, which quantifies how well a machine learning model performs in specific regions of the input space. This is in contrast to the traditional approach of evaluating a model's overall performance on a held-out test set.
The researchers derive theoretical generalization error bounds that depend on the local model validity. These bounds provide guarantees on how well the model will perform on new, unseen data compared to the training data. Importantly, the bounds also capture the model's sensitivity to changes in the input distribution.
The key technical contributions are:
- A formal definition of local model validity and its relationship to generalization error.
- Derivation of non-vacuous generalization error bounds that depend on the local model validity.
- Demonstration of how these bounds can be used to design more effective active learning strategies.
The paper leverages tools from information theory, causal reasoning, and optimization to derive these theoretical results.
Critical Analysis
The paper provides a novel and promising framework for analyzing the generalization performance of machine learning models. By focusing on local model validity, it offers a more nuanced understanding of a model's strengths and weaknesses compared to traditional test set evaluation.
However, the paper does not address several important practical considerations:
- Computational Complexity: The proposed framework relies on complex mathematical tools that may be computationally challenging to apply to large-scale real-world problems.
- Data Dependence: The derived generalization error bounds are data-dependent, which means they may be difficult to estimate accurately in practice.
- Scalability: The paper focuses on single-task learning, and it's unclear how the framework would scale to more complex, multi-task or structured prediction problems.
Additionally, while the paper demonstrates the use of local model validity in active learning, it does not explore other potential applications, such as model interpretability or robust optimization.
Overall, the paper presents an interesting and theoretically-grounded approach to analyzing generalization performance, but further research is needed to address the practical challenges and explore additional use cases.
Conclusion
This paper introduces a novel concept called local model validity and demonstrates how it can be used to derive theoretical bounds on the generalization error of machine learning models. By focusing on the model's performance in specific regions of the input space, the framework provides a more nuanced understanding of the model's strengths and weaknesses.
The derived generalization error bounds can be used to guide the active learning process, where the model selects the most informative data points to label and train on. This has the potential to improve the overall performance and robustness of machine learning models, particularly in complex real-world scenarios.
While the paper presents an interesting and theoretically-grounded approach, further research is needed to address the practical challenges and explore additional applications of the local model validity framework.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
🔍
0
Bounds on the Generalization Error in Active Learning
Vincent Menden, Yahya Saleh, Armin Iske
We establish empirical risk minimization principles for active learning by deriving a family of upper bounds on the generalization error. Aligning with empirical observations, the bounds suggest that superior query algorithms can be obtained by combining both informativeness and representativeness query strategies, where the latter is assessed using integral probability metrics. To facilitate the use of these bounds in application, we systematically link diverse active learning scenarios, characterized by their loss functions and hypothesis classes to their corresponding upper bounds. Our results show that regularization techniques used to constraint the complexity of various hypothesis classes are sufficient conditions to ensure the validity of the bounds. The present work enables principled construction and empirical quality-evaluation of query algorithms in active learning.
Read more9/17/2024
0
Error Bounds of Supervised Classification from Information-Theoretic Perspective
Binchuan Qi, Wei Gong, Li Li
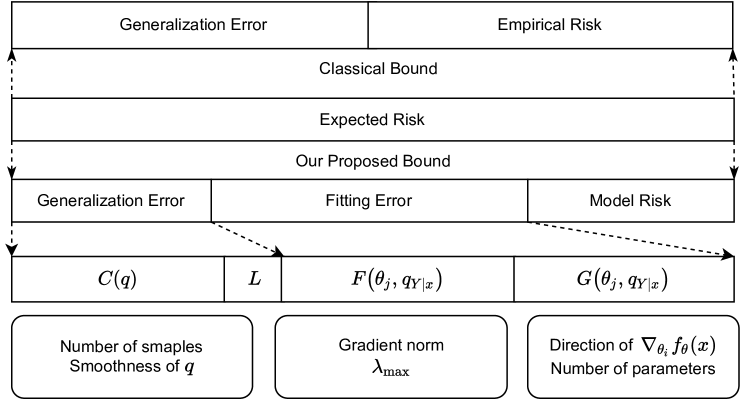
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
Read more6/28/2024
🛠️
0
Learning Non-Vacuous Generalization Bounds from Optimization
Chengli Tan, Jiangshe Zhang, Junmin Liu
One of the fundamental challenges in the deep learning community is to theoretically understand how well a deep neural network generalizes to unseen data. However, current approaches often yield generalization bounds that are either too loose to be informative of the true generalization error or only valid to the compressed nets. In this study, we present a simple yet non-vacuous generalization bound from the optimization perspective. We achieve this goal by leveraging that the hypothesis set accessed by stochastic gradient algorithms is essentially fractal-like and thus can derive a tighter bound over the algorithm-dependent Rademacher complexity. The main argument rests on modeling the discrete-time recursion process via a continuous-time stochastic differential equation driven by fractional Brownian motion. Numerical studies demonstrate that our approach is able to yield plausible generalization guarantees for modern neural networks such as ResNet and Vision Transformer, even when they are trained on a large-scale dataset (e.g. ImageNet-1K).
Read more7/23/2024
0
Generalization Bounds for Causal Regression: Insights, Guarantees and Sensitivity Analysis
Daniel Csillag, Claudio Jos'e Struchiner, Guilherme Tegoni Goedert
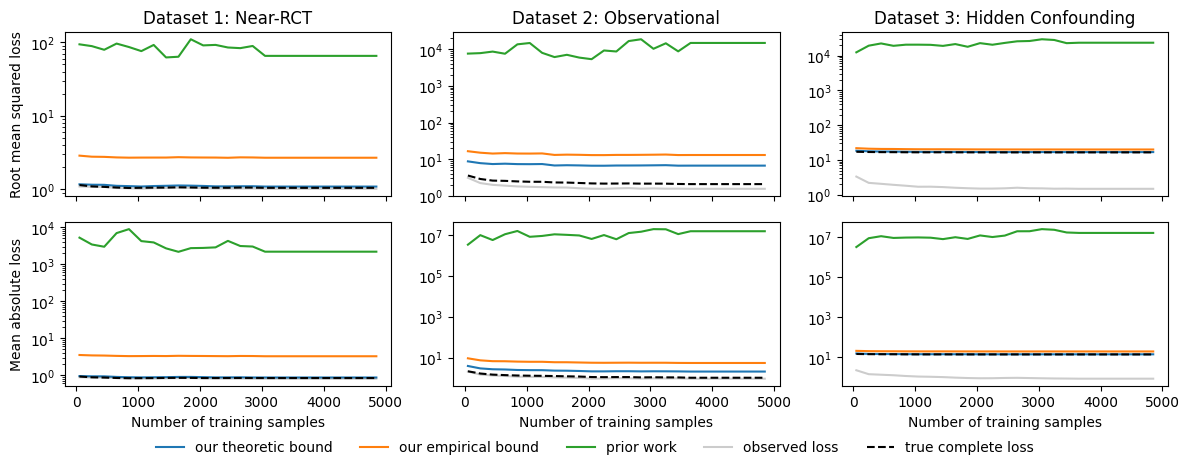
Many algorithms have been recently proposed for causal machine learning. Yet, there is little to no theory on their quality, especially considering finite samples. In this work, we propose a theory based on generalization bounds that provides such guarantees. By introducing a novel change-of-measure inequality, we are able to tightly bound the model loss in terms of the deviation of the treatment propensities over the population, which we show can be empirically limited. Our theory is fully rigorous and holds even in the face of hidden confounding and violations of positivity. We demonstrate our bounds on semi-synthetic and real data, showcasing their remarkable tightness and practical utility.
Read more5/16/2024