Error Bounds of Supervised Classification from Information-Theoretic Perspective
2406.04567
0
0
Abstract
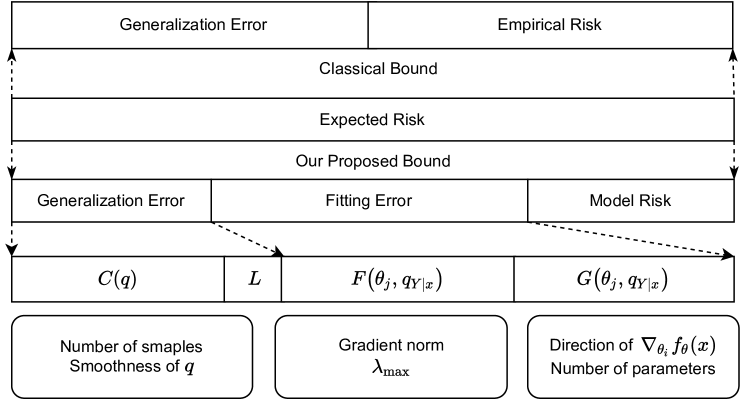
There remains a list of unanswered research questions on deep learning (DL), including the remarkable generalization power of overparametrized neural networks, the efficient optimization performance despite the non-convexity, and the mechanisms behind flat minima in generalization. In this paper, we adopt an information-theoretic perspective to explore the theoretical foundations of supervised classification using deep neural networks (DNNs). Our analysis introduces the concepts of fitting error and model risk, which, together with generalization error, constitute an upper bound on the expected risk. We demonstrate that the generalization errors are bounded by the complexity, influenced by both the smoothness of distribution and the sample size. Consequently, task complexity serves as a reliable indicator of the dataset's quality, guiding the setting of regularization hyperparameters. Furthermore, the derived upper bound fitting error links the back-propagated gradient, Neural Tangent Kernel (NTK), and the model's parameter count with the fitting error. Utilizing the triangle inequality, we establish an upper bound on the expected risk. This bound offers valuable insights into the effects of overparameterization, non-convex optimization, and the flat minima in DNNs.Finally, empirical verification confirms a significant positive correlation between the derived theoretical bounds and the practical expected risk, confirming the practical relevance of the theoretical findings.
Create account to get full access
Overview
- This paper explores the fundamental limits of supervised classification from an information-theoretic perspective.
- The authors derive new generalization error bounds for deep neural networks trained with the logistic loss function.
- These bounds provide insights into the role of mutual information between the input and output in determining the classification performance.
- The results have implications for understanding the generalization capabilities of deep learning models.
Plain English Explanation
The paper investigates the theoretical limits of how well a machine learning model can classify data into different categories. The researchers focus on a common type of model called a deep neural network, which is trained using a specific loss function called the logistic loss.
The paper on information-theoretic generalization bounds for deep neural networks provides a mathematical analysis to understand how much information the model needs to learn in order to perform well on new, unseen data. This is an important question, as it helps explain the strengths and limitations of deep learning models.
The key insight is that the model's classification performance is fundamentally tied to the amount of mutual information between the input data and the correct labels. This builds on prior work on classification bounds using margin-based approaches and slicing mutual information.
By deriving these new information-theoretic bounds, the researchers offer a fresh perspective on why deep neural networks trained with the logistic loss function can generalize well to new data. The results provide insights that could help improve the design and training of deep learning models in the future.
Technical Explanation
The paper derives new generalization error bounds for deep neural networks trained with the logistic loss function. The authors leverage information-theoretic tools to connect the model's classification performance to the amount of mutual information between the input data and the corresponding labels.
Specifically, they prove that the generalization error is upper bounded by a term that scales inversely with the mutual information. This suggests that models can achieve low generalization error by learning to extract a large amount of relevant information from the input data.
The theoretical analysis builds upon prior work on margin-based generalization bounds and mutual information-based approaches. For example, the authors build on the margin-based multiclass generalization bound derived in a previous paper. They also draw connections to the slicing mutual information framework for bounding the generalization error of neural networks.
The key technical contributions include:
- Deriving a new generalization error bound for deep neural networks trained with the logistic loss
- Analyzing the role of mutual information between the input and output in determining this bound
- Providing insights into the factors that influence the generalization performance of deep learning models
Critical Analysis
The paper presents a rigorous theoretical analysis and derives novel generalization error bounds for deep neural networks. The information-theoretic perspective offers a fresh viewpoint on understanding the generalization capabilities of these models.
One potential limitation is that the analysis assumes the model has access to the true underlying data distribution, which may not always be the case in practice. Additionally, the bounds are derived for the logistic loss function, and it would be valuable to extend the analysis to other loss functions commonly used in deep learning.
Furthermore, the paper focuses on the population-level generalization error, whereas in many real-world applications, the performance on a finite test set is of primary interest. Bridging the gap between population-level bounds and finite-sample guarantees remains an important challenge.
Despite these caveats, the information-theoretic perspective presented in this paper offers valuable insights and opens up new research directions. The theoretical framework could inspire the design of more efficient deep learning algorithms and provide a better understanding of the fundamental limits of supervised classification.
Conclusion
This paper offers a novel information-theoretic approach to analyzing the generalization error bounds of deep neural networks trained with the logistic loss function. The key insight is that the classification performance is fundamentally linked to the mutual information between the input data and the corresponding labels.
By deriving these new bounds, the researchers provide a fresh perspective on why deep learning models can generalize well to new data. The results have implications for understanding the capabilities and limitations of deep neural networks, which could guide the development of more robust and efficient machine learning algorithms in the future.
Overall, the paper contributes to the ongoing efforts to bridge the gap between the empirical success of deep learning and its theoretical underpinnings, ultimately advancing our understanding of this powerful class of models.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers

Information-Theoretic Generalization Bounds for Deep Neural Networks
Haiyun He, Christina Lee Yu, Ziv Goldfeld
0
0
Deep neural networks (DNNs) exhibit an exceptional capacity for generalization in practical applications. This work aims to capture the effect and benefits of depth for supervised learning via information-theoretic generalization bounds. We first derive two hierarchical bounds on the generalization error in terms of the Kullback-Leibler (KL) divergence or the 1-Wasserstein distance between the train and test distributions of the network internal representations. The KL divergence bound shrinks as the layer index increases, while the Wasserstein bound implies the existence of a layer that serves as a generalization funnel, which attains a minimal 1-Wasserstein distance. Analytic expressions for both bounds are derived under the setting of binary Gaussian classification with linear DNNs. To quantify the contraction of the relevant information measures when moving deeper into the network, we analyze the strong data processing inequality (SDPI) coefficient between consecutive layers of three regularized DNN models: Dropout, DropConnect, and Gaussian noise injection. This enables refining our generalization bounds to capture the contraction as a function of the network architecture parameters. Specializing our results to DNNs with a finite parameter space and the Gibbs algorithm reveals that deeper yet narrower network architectures generalize better in those examples, although how broadly this statement applies remains a question.
4/5/2024
🏷️
Classification with Deep Neural Networks and Logistic Loss
Zihan Zhang, Lei Shi, Ding-Xuan Zhou
0
0
Deep neural networks (DNNs) trained with the logistic loss (i.e., the cross entropy loss) have made impressive advancements in various binary classification tasks. However, generalization analysis for binary classification with DNNs and logistic loss remains scarce. The unboundedness of the target function for the logistic loss is the main obstacle to deriving satisfactory generalization bounds. In this paper, we aim to fill this gap by establishing a novel and elegant oracle-type inequality, which enables us to deal with the boundedness restriction of the target function, and using it to derive sharp convergence rates for fully connected ReLU DNN classifiers trained with logistic loss. In particular, we obtain optimal convergence rates (up to log factors) only requiring the Holder smoothness of the conditional class probability $eta$ of data. Moreover, we consider a compositional assumption that requires $eta$ to be the composition of several vector-valued functions of which each component function is either a maximum value function or a Holder smooth function only depending on a small number of its input variables. Under this assumption, we derive optimal convergence rates (up to log factors) which are independent of the input dimension of data. This result explains why DNN classifiers can perform well in practical high-dimensional classification problems. Besides the novel oracle-type inequality, the sharp convergence rates given in our paper also owe to a tight error bound for approximating the natural logarithm function near zero (where it is unbounded) by ReLU DNNs. In addition, we justify our claims for the optimality of rates by proving corresponding minimax lower bounds. All these results are new in the literature and will deepen our theoretical understanding of classification with DNNs.
4/23/2024

A Margin-based Multiclass Generalization Bound via Geometric Complexity
Michael Munn, Benoit Dherin, Javier Gonzalvo
0
0
There has been considerable effort to better understand the generalization capabilities of deep neural networks both as a means to unlock a theoretical understanding of their success as well as providing directions for further improvements. In this paper, we investigate margin-based multiclass generalization bounds for neural networks which rely on a recent complexity measure, the geometric complexity, developed for neural networks. We derive a new upper bound on the generalization error which scales with the margin-normalized geometric complexity of the network and which holds for a broad family of data distributions and model classes. Our generalization bound is empirically investigated for a ResNet-18 model trained with SGD on the CIFAR-10 and CIFAR-100 datasets with both original and random labels.
5/30/2024

Slicing Mutual Information Generalization Bounds for Neural Networks
Kimia Nadjahi, Kristjan Greenewald, Rickard Bruel Gabrielsson, Justin Solomon
0
0
The ability of machine learning (ML) algorithms to generalize well to unseen data has been studied through the lens of information theory, by bounding the generalization error with the input-output mutual information (MI), i.e., the MI between the training data and the learned hypothesis. Yet, these bounds have limited practicality for modern ML applications (e.g., deep learning), due to the difficulty of evaluating MI in high dimensions. Motivated by recent findings on the compressibility of neural networks, we consider algorithms that operate by slicing the parameter space, i.e., trained on random lower-dimensional subspaces. We introduce new, tighter information-theoretic generalization bounds tailored for such algorithms, demonstrating that slicing improves generalization. Our bounds offer significant computational and statistical advantages over standard MI bounds, as they rely on scalable alternative measures of dependence, i.e., disintegrated mutual information and $k$-sliced mutual information. Then, we extend our analysis to algorithms whose parameters do not need to exactly lie on random subspaces, by leveraging rate-distortion theory. This strategy yields generalization bounds that incorporate a distortion term measuring model compressibility under slicing, thereby tightening existing bounds without compromising performance or requiring model compression. Building on this, we propose a regularization scheme enabling practitioners to control generalization through compressibility. Finally, we empirically validate our results and achieve the computation of non-vacuous information-theoretic generalization bounds for neural networks, a task that was previously out of reach.
6/7/2024