BOX3D: Lightweight Camera-LiDAR Fusion for 3D Object Detection and Localization

0

Sign in to get full access
Overview
- BOX3D is a lightweight camera-LiDAR fusion approach for 3D object detection and localization.
- It combines the complementary strengths of cameras and LiDAR to achieve accurate 3D object detection.
- The method is efficient and can run in real-time, making it suitable for autonomous driving and robotics applications.
Plain English Explanation
BOX3D is a new technique that uses data from two common sensors, cameras, and LiDAR, to detect and locate 3D objects in the environment. Cameras provide detailed visual information, while LiDAR sensors measure the distance to objects using lasers. By combining the strengths of these two sensors, BOX3D can accurately identify and position 3D objects, such as cars, pedestrians, or other obstacles, in a scene.
The key innovation of BOX3D is that it can perform this 3D object detection in a very efficient and lightweight way, allowing it to run in real-time. This makes it well-suited for use in autonomous vehicles, robots, and other applications where fast and accurate 3D perception is crucial. Rather than relying on complex and computationally expensive methods, BOX3D uses a smart fusion of the camera and LiDAR data to achieve high performance with low resource requirements.
Technical Explanation
BOX3D is a camera-LiDAR fusion approach for 3D object detection and localization. It leverages the complementary strengths of cameras, which provide rich visual information, and LiDAR, which can accurately measure the 3D structure of the environment.
The BOX3D architecture consists of three main components: a 2D object detector, a 3D bounding box regressor, and a fusion module. The 2D object detector identifies objects in the camera image, while the 3D bounding box regressor estimates the 3D position and dimensions of those objects using the LiDAR data. The fusion module then combines the 2D and 3D information to produce the final 3D object detections.
The key innovations of BOX3D include its lightweight design, efficient implementation, and novel fusion strategy. By carefully optimizing the architecture and leveraging the complementary sensor modalities, BOX3D can achieve high accuracy while running in real-time, making it suitable for autonomous driving and robotics applications.
Critical Analysis
The authors of BOX3D acknowledge that their method has some limitations. For example, the accuracy of the 3D bounding box regression may be affected by the quality and coverage of the LiDAR data, which can be sparse in some areas. Additionally, the fusion strategy may not be as effective in scenarios with significant occlusions or where the camera and LiDAR are not well-calibrated.
While BOX3D represents an important advance in camera-LiDAR fusion for 3D object detection, there are still opportunities for further research and improvements. Potential areas of exploration include developing more robust fusion techniques, incorporating additional sensor modalities (e.g., radar), and exploring end-to-end learning approaches that can optimize the entire perception pipeline.
Conclusion
BOX3D is a promising camera-LiDAR fusion method for 3D object detection and localization. By leveraging the complementary strengths of cameras and LiDAR, it can achieve accurate 3D perception while maintaining high efficiency and real-time performance. This makes BOX3D a valuable tool for autonomous driving, robotics, and other applications that require reliable and responsive 3D scene understanding.
The innovations in BOX3D's lightweight architecture and fusion strategy represent an important step forward in sensor fusion for 3D object detection. As the field continues to evolve, further research and development in this area will likely lead to even more advanced and practical solutions for various real-world applications.
This summary was produced with help from an AI and may contain inaccuracies - check out the links to read the original source documents!
Related Papers
0
BOX3D: Lightweight Camera-LiDAR Fusion for 3D Object Detection and Localization
Mario A. V. Saucedo, Nikolaos Stathoulopoulos, Vidya Sumathy, Christoforos Kanellakis, George Nikolakopoulos
Object detection and global localization play a crucial role in robotics, spanning across a great spectrum of applications from autonomous cars to multi-layered 3D Scene Graphs for semantic scene understanding. This article proposes BOX3D, a novel multi-modal and lightweight scheme for localizing objects of interest by fusing the information from RGB camera and 3D LiDAR. BOX3D is structured around a three-layered architecture, building up from the local perception of the incoming sequential sensor data to the global perception refinement that covers for outliers and the general consistency of each object's observation. More specifically, the first layer handles the low-level fusion of camera and LiDAR data for initial 3D bounding box extraction. The second layer converts each LiDAR's scan 3D bounding boxes to the world coordinate frame and applies a spatial pairing and merging mechanism to maintain the uniqueness of objects observed from different viewpoints. Finally, BOX3D integrates the third layer that supervises the consistency of the results on the global map iteratively, using a point-to-voxel comparison for identifying all points in the global map that belong to the object. Benchmarking results of the proposed novel architecture are showcased in multiple experimental trials on public state-of-the-art large-scale dataset of urban environments.
Read more8/28/2024
🔎
0
On Onboard LiDAR-based Flying Object Detection
Matouv{s} Vrba, Viktor Walter, V'aclav Pritzl, Michal Pliska, Tom'av{s} B'av{c}a, Vojtv{e}ch Spurn'y, Daniel Hev{r}t, Martin Saska
A new robust and accurate approach for the detection and localization of flying objects with the purpose of highly dynamic aerial interception and agile multi-robot interaction is presented in this paper. The approach is proposed for use onboard an autonomous aerial vehicle equipped with a 3D LiDAR sensor providing input data for the algorithm. It relies on a novel 3D occupancy voxel mapping method for the target detection and a cluster-based multiple hypothesis tracker to compensate uncertainty of the sensory data. When compared to state-of-the-art methods of onboard detection of other flying objects, the presented approach provides superior localization accuracy and robustness to different environments and appearance changes of the target, as well as a greater detection range. Furthermore, in combination with the proposed multi-target tracker, sporadic false positives are suppressed, state estimation of the target is provided and the detection latency is negligible. This makes the detector suitable for tasks of agile multi-robot interaction, such as autonomous aerial interception or formation control where precise, robust, and fast relative localization of other robots is crucial. We demonstrate the practical usability and performance of the system in simulated and real-world experiments.
Read more7/12/2024

0
BiCo-Fusion: Bidirectional Complementary LiDAR-Camera Fusion for Semantic- and Spatial-Aware 3D Object Detection
Yang Song, Lin Wang
3D object detection is an important task that has been widely applied in autonomous driving. Recently, fusing multi-modal inputs, i.e., LiDAR and camera data, to perform this task has become a new trend. Existing methods, however, either ignore the sparsity of Lidar features or fail to preserve the original spatial structure of LiDAR and the semantic density of camera features simultaneously due to the modality gap. To address issues, this letter proposes a novel bidirectional complementary Lidar-camera fusion framework, called BiCo-Fusion that can achieve robust semantic- and spatial-aware 3D object detection. The key insight is to mutually fuse the multi-modal features to enhance the semantics of LiDAR features and the spatial awareness of the camera features and adaptatively select features from both modalities to build a unified 3D representation. Specifically, we introduce Pre-Fusion consisting of a Voxel Enhancement Module (VEM) to enhance the semantics of voxel features from 2D camera features and Image Enhancement Module (IEM) to enhance the spatial characteristics of camera features from 3D voxel features. Both VEM and IEM are bidirectionally updated to effectively reduce the modality gap. We then introduce Unified Fusion to adaptively weight to select features from the enchanted Lidar and camera features to build a unified 3D representation. Extensive experiments demonstrate the superiority of our BiCo-Fusion against the prior arts. Project page: https://t-ys.github.io/BiCo-Fusion/.
Read more6/28/2024
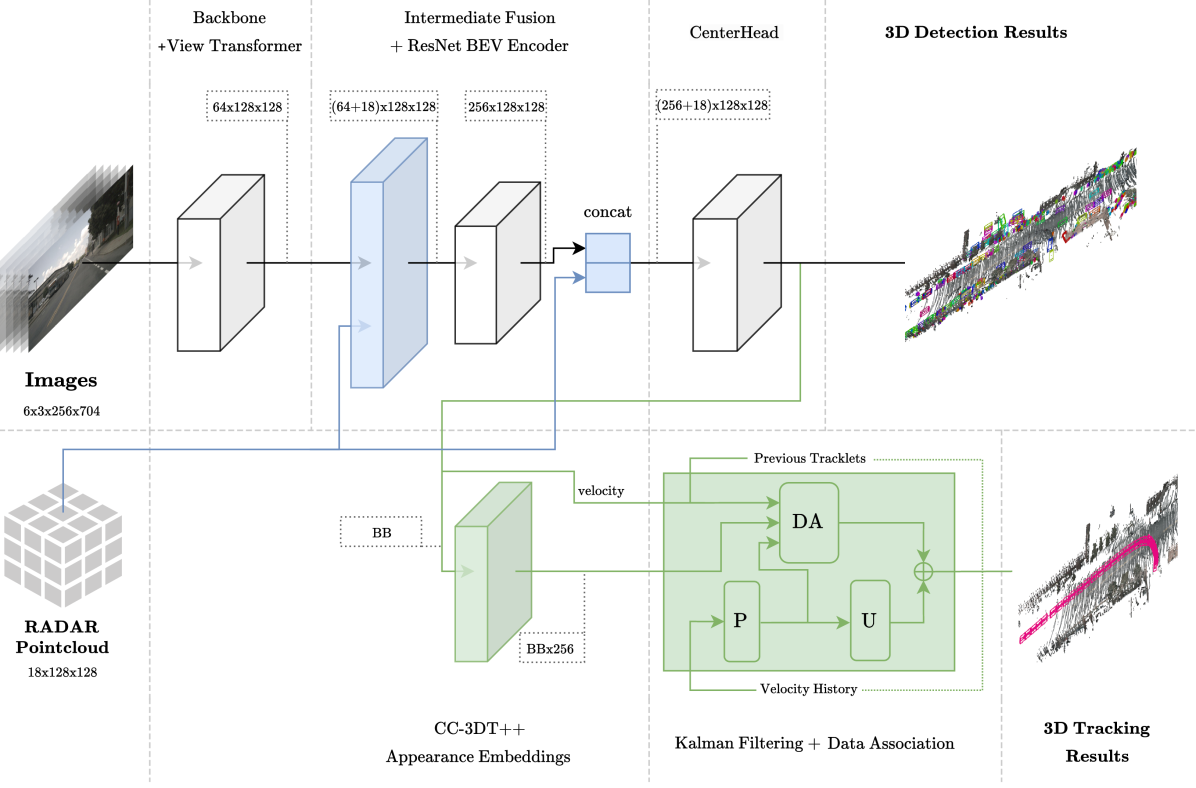
0
CR3DT: Camera-RADAR Fusion for 3D Detection and Tracking
Nicolas Baumann, Michael Baumgartner, Edoardo Ghignone, Jonas Kuhne, Tobias Fischer, Yung-Hsu Yang, Marc Pollefeys, Michele Magno
To enable self-driving vehicles accurate detection and tracking of surrounding objects is essential. While Light Detection and Ranging (LiDAR) sensors have set the benchmark for high-performance systems, the appeal of camera-only solutions lies in their cost-effectiveness. Notably, despite the prevalent use of Radio Detection and Ranging (RADAR) sensors in automotive systems, their potential in 3D detection and tracking has been largely disregarded due to data sparsity and measurement noise. As a recent development, the combination of RADARs and cameras is emerging as a promising solution. This paper presents Camera-RADAR 3D Detection and Tracking (CR3DT), a camera-RADAR fusion model for 3D object detection, and Multi-Object Tracking (MOT). Building upon the foundations of the State-of-the-Art (SotA) camera-only BEVDet architecture, CR3DT demonstrates substantial improvements in both detection and tracking capabilities, by incorporating the spatial and velocity information of the RADAR sensor. Experimental results demonstrate an absolute improvement in detection performance of 5.3% in mean Average Precision (mAP) and a 14.9% increase in Average Multi-Object Tracking Accuracy (AMOTA) on the nuScenes dataset when leveraging both modalities. CR3DT bridges the gap between high-performance and cost-effective perception systems in autonomous driving, by capitalizing on the ubiquitous presence of RADAR in automotive applications. The code is available at: https://github.com/ETH-PBL/CR3DT.
Read more8/7/2024